
Aligning Cyber Space with Physical World A Comprehensive Survey on Embodied AI
这是一篇Embodied AI的综述文章,介绍了Embodied AI的几个研究方向以及现状。
背景介绍
在计算机空间Cyber-Space中的智能体,被称为非具身智能体,而在物理世界中的智能体则称之为具身智能。
Embodied AI对AGI的实现很重要,是链接计算机世界与物理世界之间的各种应用的基础。
目前多模态大模型(MLM)和世界模型(WM)使具身模型具有更强大的感知、交互以及规划能力。这些模型表现出卓越的模拟能力和对物理定律的良好理解,这使得具体模型能够全面理解物理和真实环境。具身智能也被认为是这些模型的最佳载体。
具身智能最初是由 Alan Turing 于 1950 年提出的 Embodied Turing Test,该测试旨在确定具身代理是否能够显示不仅限于解决计算机空间,而且还有物理世界中的复杂性和不可预测性问题。
具身智能和非具身智能的对比如下:
| 类型 | 所在环境 | 物理实体 | 描述 | 代表 |
|---|---|---|---|---|
| 非具身AI | CyberSpace | 无 | 认知与物理实体分离 | ChatGPT |
| 具身AI | 物理空间 | 机器人,车… | 认知融入于物理实体 | 谷歌机器人RT-1 |
为了实现AGI,具身智能是一个基本途径。Embodied AI其具有控制物理实体,可以和模拟或者物理环境交互。(这点和AGI相同)
基于MLMs和WMs的具身智能的总体框架。具身智能使用具身世界模型作为它的“大脑”。它具有理解虚拟物理环境并主动感知多模态元素的能力。它可以充分理解人类意图,符合人类价值和事件因果关系,分解复杂的任务并执行可靠的行动,以及与人类交互并利用知识和工具。如图:
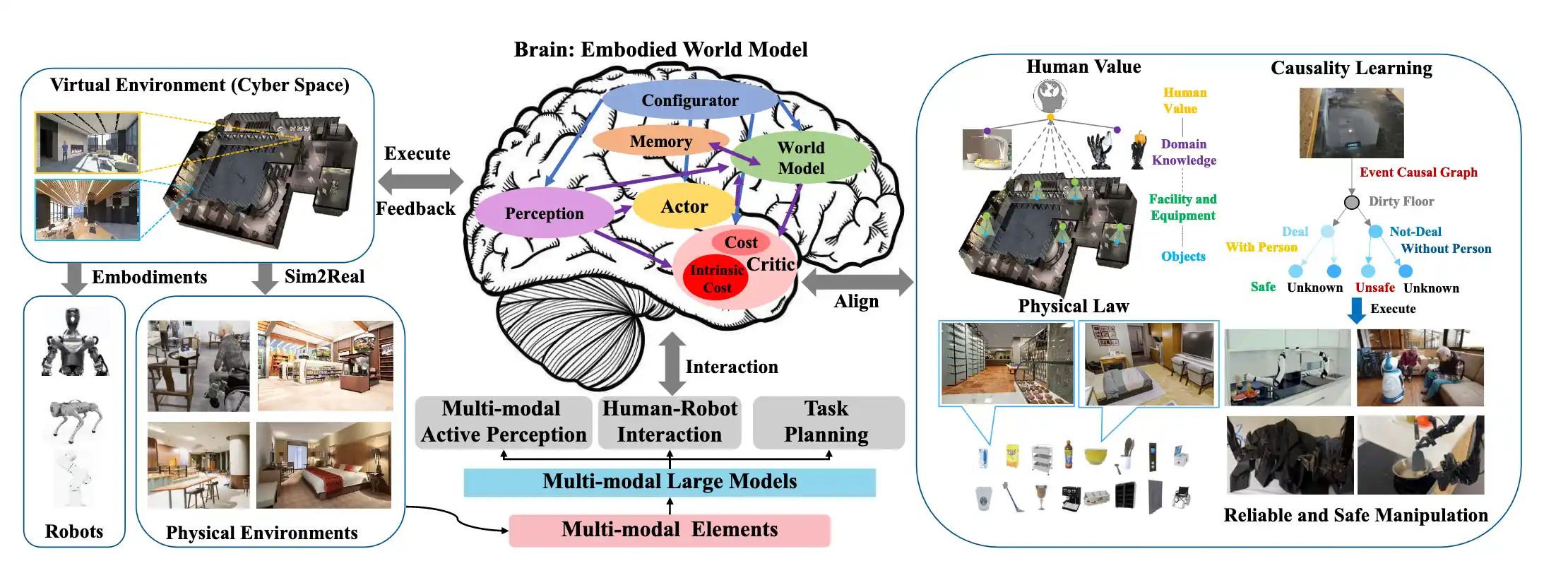
具身智能包含的不同研究方向:
- 具身机器人
- 模拟器
-下面四个是任务: - 具身感知(视觉主动感知)embodied perception
- 具身交互 embodied interaction
- 多模态(具身)智能体 embodied agents
- 模拟到现实的机器人控制 sim-to-real robotic control
下面对各个方向进行介绍:
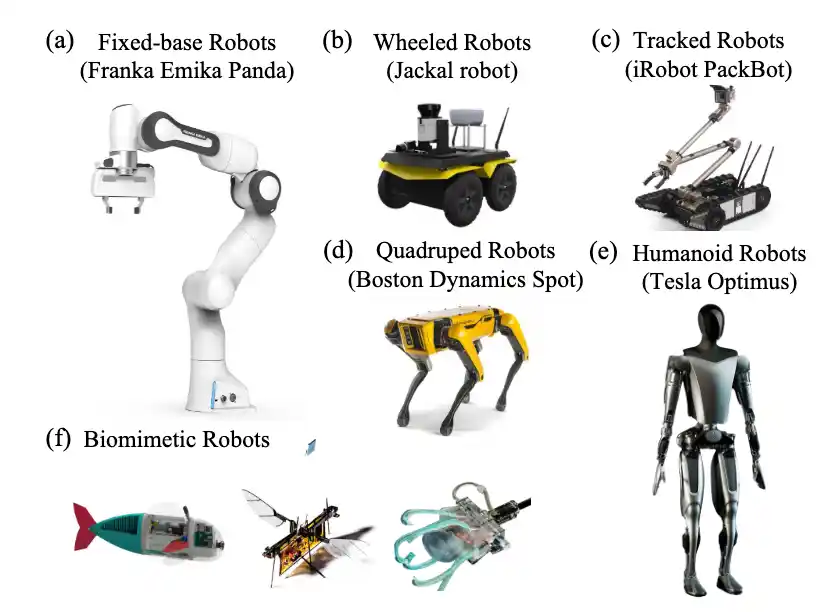
具身机器人 Embodied Robots
能与环境主动交互的实体类型有很多,例如 机器人、智能家电、智能眼镜、自动驾驶汽车等等。其中机器人是最有代表性的实体。
机器人可以被设计成各种形式,来完成特定任务。例如 定基机器人、轮式、履带式、四足、人形、仿生机器人等等。
定基机器人 Fixed-based Robots
定基机器人具有紧凑性和操作精度、稳定性高的特点,一般配备高精度传感器和执行器,可以使其实现微米级操作精度。可编程,用户可以通过编程可以使其适用于各种任务场景。
但是固定的底座设计限制了他们的操作范围和灵活性,难以在大范围内移动或者调整位置、以及与人类或者其他机器人合作。
轮式、履带式机器人
受益于其常规的移动方式,这些机器人可以面对更复杂多样的场景。
轮式机器人 Wheeled Robots
具有高效的移动性(在平面上)、结构简单、成本相对较低、能源效率高的优点,广泛应用于物流、仓储、安检等等领域。
这些机器人常常配备激光雷达和摄像头等高精度传感器,可以实现自主导航和环境感知。例如kiva、jackal机器人。
但是在复杂地形或者恶劣环境中,移动性有限,负载能力和机动性也会受到一定限制。
履带式机器人 Tracked Robots
履带式机器人在非平面上的机动性更强,有强大的越野能力。履带与地面接触面积更大,分散重量,防止在松软地形下沉。应用于恶劣、特殊环境下的任务:农业、建筑、灾难恢复、军事。
由于履带系统的高摩擦力,履带式机器人能源效率较低。此外,平面上的移动速度比轮式机器人慢,灵活性和可操作性也较差。
四足机器人
稳定性和适应性较强,可以通过雷达或者摄像头来进行环境感知。甚至可以主动导航避开障碍物。
设计复杂而且制造成本很高,限制在成本敏感领域的使用。此外,在复杂环境下的电池续航能力有限,需要频繁充电或更换电池才能长时间运行。
人形机器人
手部设计使它们能够执行复杂的任务具有多个自由度和高精度传感器,使它们能够模仿人手的抓取和操纵能力,这在医疗手术和精密制造等领域尤其重要。可以行走、跑步、爬楼梯、识别面孔和手势,适合接待和引导服务,可以识别情绪并进行自然语言交流,广泛应用于客户服务和教育环境中。
但是,由于其复杂的控制系统,人形机器人在复杂环境下保持运行稳定性和可靠性面临挑战。
仿生机器人
通过模拟自然生物体的高效运动和功能,在复杂和动态的环境中执行任务。在医疗保健、环境监测和生物研究等领域展现出巨大的潜力。仿生设计可以通过模仿生物有机体的高效运动机制来显着提高机器人的能源效率,使它们在能源消耗方面更加经济。
但是,其设计和制造工艺复杂且成本高昂,限制了大规模生产和广泛应用。其次,由于采用柔性材料和复杂的运动机制,仿生机器人在极端环境下的耐用性和可靠性受到限制。
具身模拟器 Embodied Simulators
为了使智能体能够与环境交互,需要构建一个真实的模拟环境。这需要考虑环境的物理特征、物体的属性及其相互作用。具身模拟器,提供了高效经济的实验环境。可以为具身智能提供不同的测试环境,模拟潜在危险场景。
下面介绍两种模拟器:基于底层模拟的通用模拟器和基于现实场景的模拟器。
基于底层仿真的通用模拟器 general simulator based on underlying simulation
在物理世界中的 物理交互 和 动态变化 是 不可替代的,但是在物理世界直接部署具身模型进行训练或者测试的成本太高。而通用模拟器提供一个几乎仿真(物理世界)的虚拟环境。可以在其中进行算法开发、模型训练。在成本、时间、安全上都具有一定优势。本文介绍了3种常见的通用模拟器:Isaac Sim、Gazebo、PyBullet.
Isaac Sim
isaac sim是NVDIA为机器人和AI研究提供的先进的仿真平台,具有高保真物理模拟、实时光线追踪、广泛的机器人模型库和深度学习支持。应用场景包括自动驾驶、工业自动化和人机交互。
Gazebo
gazebo是一个用于机器人研究的开源模拟器,支持各种传感器的仿真,拥有丰富的机器人库,主要用于机器人导航与控制以及多机器人系统。
PyBullet
PyBullet是Bullet 物理引擎的python接口,易于使用,具有多种传感器模拟和深度学习集成。支持实时物理模拟,包括刚体动力学、碰撞检测和约束求解
各种仿真平台
下图介绍了10个通用模拟器的主要特点和主要应用场景。它们各自在具体人工智能领域提供独特的优势。
综合
HFPS:高保真物理模拟;
HQGR:高质量图形渲染;
RRL:丰富的机器人库;
DLS:深度学习支持;
LSPC:大规模并行计算;
ROS:与 ROS 紧密集成;
MSS:多传感器模拟;
CP:跨平台;
NAV:机器人导航;
AD:自动驾驶;
RL:强化学习;
LSPS:大规模并行;
SIM MR:多机器人系统;
RS:机器人仿真

各种仿真平台的可视化效果如下:

基于现实场景的模拟器 the simulator based on real scenes
在家庭活动中实现通用的具身智能体一直是具身人工智能研究领域的主要焦点。这些实体代理需要深入了解人类的日常生活并执行复杂的实体任务,例如室内环境中的导航和交互。
基于这种特定的复杂任务场景,模拟器的需要尽可能接近现实世界。这一要求对模拟器的复杂性和真实性有很高的要求。这些模拟器主要从现实世界收集数据,创建逼真的 3D 资源,并使用 UE5 和 Unity 等 3D 游戏引擎构建场景。这些模拟器的侧重点各不相同,有的具有丰富的交互场景对象以及分配给它们的物理属性(例如打开/关闭甚至冷/热),有的支持多智能体模拟。来自开放资源或定制的多个实体代理(例如人类和机器狗)可以在模拟器中合作,自由移动,并与场景进行简单的交互。有的甚至实现刚体、软体、织物、流体等多种材质的物理交互模拟,并提供与物体交互时的情境声音。可以支持用户自定义环境进行训练。
各种现实场景模拟器的条件:

现实场景模拟器的可视化场景:

具身感知 Embodied Perception
未来视觉感知的启明星是以具身为中心的视觉推理和社交智能,即具身感知任务。这种任务和仅仅识别图像中的物体不同,具身感知要求Agent可以在物理世界中移动并且与环境进行交互,要求具身智能体对3D空间和动态的环境有更加深入的了解。具身感知需要视觉感知和推理、理解场景内的3D关系,以及基于视觉信息预测和执行复杂任务。
具身智能体的感知任务包含以下方向:
- 主动视觉感知
- 3D视觉定位
- 视觉语言导航
- 非视觉感知-触觉
主动视觉感知 Active Visual Perception
主动视觉感知系统状态估计、场景感知和环境探索等基本能力。这些能力在 视觉SLAM(视觉同步定位和映射,visual simultaneous localization and mapping)和3D场景理解、主动探索 任务中 被 广泛研究。
下面是主动视觉感知的示意图: 3D 场景理解、vSLAM 为 被动视觉感知 提供了基础,而主动探索可以为被动感知系统提供主动性。这三个要素相辅相成,对于主动视觉感知系统至关重要。
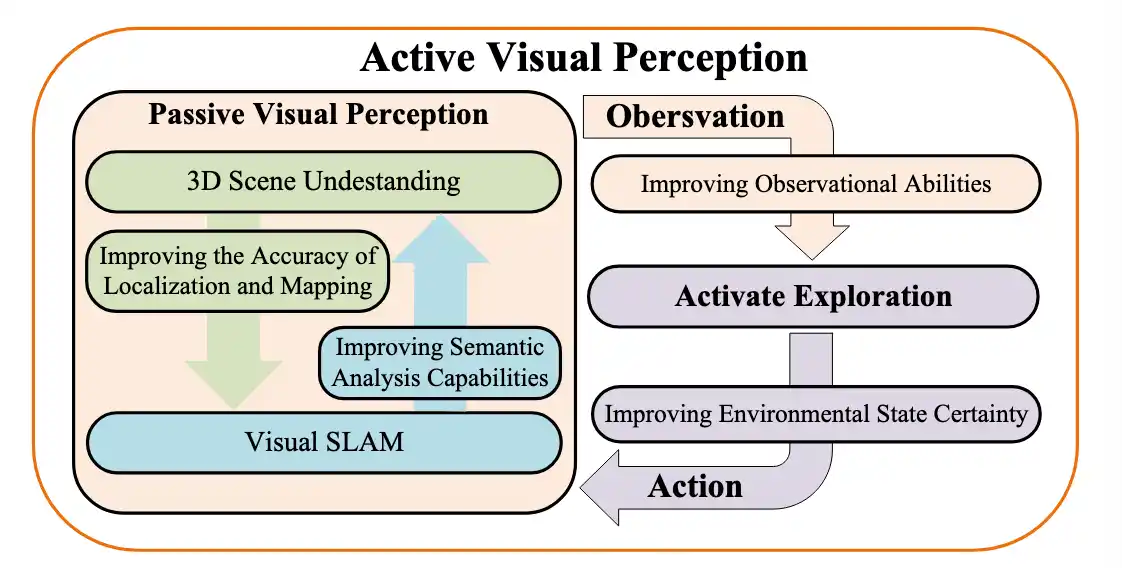
这些研究领域有助于开发强大的主动视觉感知系统,促进复杂动态环境中改善环境交互和导航。而其中的 三个组成部分 的研究现状如下表:
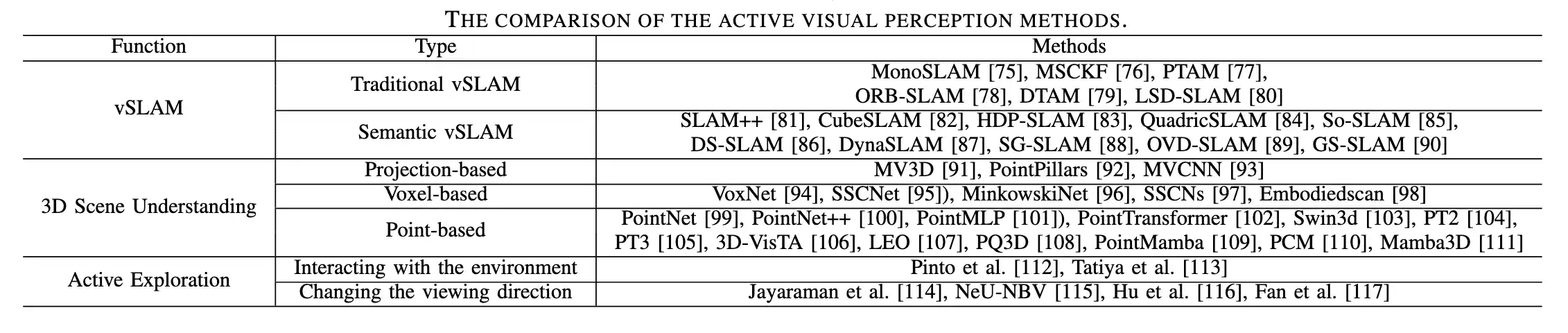
下面大概介绍各个组成部分的主要方法。
视觉 同步定位 和 映射 vSLAM : Visual Simultaneous Localization and Mapping
同步定位和映射(SLAM)是一种 在确定 可移动机器人在位置环境的位置 的同时 构造所在位置环境的地图的技术。
基于距离的SLAM通过测距仪,创建点云,但是成本高且提供的信息很少。
视觉SLAM 通过 机载摄像机 获取帧 然后 构建环境的表示。硬件成本低,小规模场景准确率高,可以捕获到丰富的环境信息。经典的vSLAM又可以分为 传统vSLAM 和 语义vSLAM。
传统vSLAM :Tradition
通过 图像信息 和 多视图几何原理 估计robot在位置环境中的姿势,来建造由点云构成的低级地图(稀疏地图、半密集地图)。 但是由于 低级地图的点云 与 环境中的物体 并不直接对应,所以robots很难 对其进行解释或者利用。
例子中的方法有 MonoSLAM MSCKF ORB-SLAM PTAM DTAM
语义vSLAM :Semantic
#TODO 什么是语义SLAM
与 语义信息处理方法 集成的的 语义vSLAM系统的出现,让robots有更强对未知环境的感知能力。
早期的方法有SLAM++,通过 实时的3D目标识别与追踪 来创建高效的对象图,从而实现在复杂环境的重定位和目标检测功能。
CubeSLAM和HDP-SLAM将3D矩形引入地图来构建轻量语义图。
QuadricSLAM 采用语义 3D 椭球体来实现复杂几何环境中物体形状和姿势的精确建模。
So-SLAM 在室内环境中纳入了完全耦合的空间结构约束(共面性、共线性和邻近性)。
为了应对动态环境的挑战,DS-SLAM、DynaSLAM 和SG-SLAM 采用语义分割进行运动一致性检查,并采用多视图几何算法来识别和过滤动态对象,确保稳定的定位和建图。
OVD-SLAM 利用语义、深度和光流信息来区分没有预定义标签的动态区域,实现更准确和鲁棒的定位。
GSSLAM 利用 3D 高斯表示,通过实时可微分泼溅渲染管道和自适应扩展策略来平衡效率和准确性。
3D场景理解 3D Scence Understanding
#TODO 主要方法的插图
3D场景理解旨在区分对象的语义,识别其位置,并从3D场景数据中推断几何属性,这是自动驾驶、机器人导航和人机交互的基础等。可以使用 LiDAR 或 RGB-D 传感器等 3D 扫描工具将场景记录为 3D 点云。与图像不同,点云稀疏、无序且不规则,使得场景解释很有难度。
近年所提出的基于深度学习理解3D场景方法,分为:基于投影(projection)的方法、基于体素(voxel)的方法、基于点(point)的方法。这三种方法是对点云的不同处理方式、角度。
基于投影的方法(MV3D、PointPillars、MVCNN)将3D点投影到各种图像平面上,然后采用CNN的2D主干进行特征提取。
基于voxel的方法将点云转化为规则的voxel网格以促进3D卷积运算(例如VoxNet,SSCNet),还有一些通过稀疏卷积提高效率。
基于点的方法直接处理点云(PointNet、PointNet++、PointMLP)。或者为了模型的可拓展性有基于Transformer或者Mamba的架构。
主动探索 Active Exploration
上面提到的3D场景理解方法,赋予了robots被动感知环境的能力,但是感知系统的信息获取和决策不适应不断变化的场景。
被动的感知方式为为robots对环境的理解提供了基础,但是这种理解是从特定(或者说给定)的角度。有一定的局限性。
但是由于robots可以移动以及与环境进行互动,结合这一特点,使robots获得主动感知探索环境的能力,通过与环境交互、通过观察环境的视角获取更多信息,使其加深对环境的理解能力。这也是近些方法的做法。
例如:
- 有人提出了一种好奇的机器人,它通过与环境的物理交互来学习视觉表示,而不是仅仅依赖数据集中的类别标签。为了解决具有不同形态的机器人之间的交互式对象感知的挑战。
- 提出了一种多阶段投影框架,通过学习的探索性交互传递隐式知识,使机器人能够有效地识别物体属性,而无需从头开始重新学习。
- 认识到自主捕获信息性观察结果的挑战。 [114]提出了一种强化学习方法,其中代理通过减少其环境中未观察到的部分的不确定性来学习主动获取信息丰富的视觉观察,使用循环神经网络主动完成全景场景和 3D 对象形状。
- 引入了一种无地图规划框架,该框架迭代地定位 RGB 相机以捕获未知场景中信息最丰富的图像,并在基于图像的神经渲染中使用新颖的不确定性估计来引导数据收集到最不确定的视图。
- [116]开发了一种机器人探索算法,该算法使用状态值函数来预测未来状态的值,结合离线蒙特卡罗训练、在线时间差异自适应和基于传感器信息覆盖的内在奖励函数。
3D视觉定位 3D Visual Grounding
3D VG(visual grounding)区别于2D VG,不只是在平面中考察,而是包含了对象的深度,视角以及空间关系。这类任务涉及 使用自然语言描述在3D环境中的定位对象。近期的3D VG方法大致分为两类 :2-stage和1-stage:
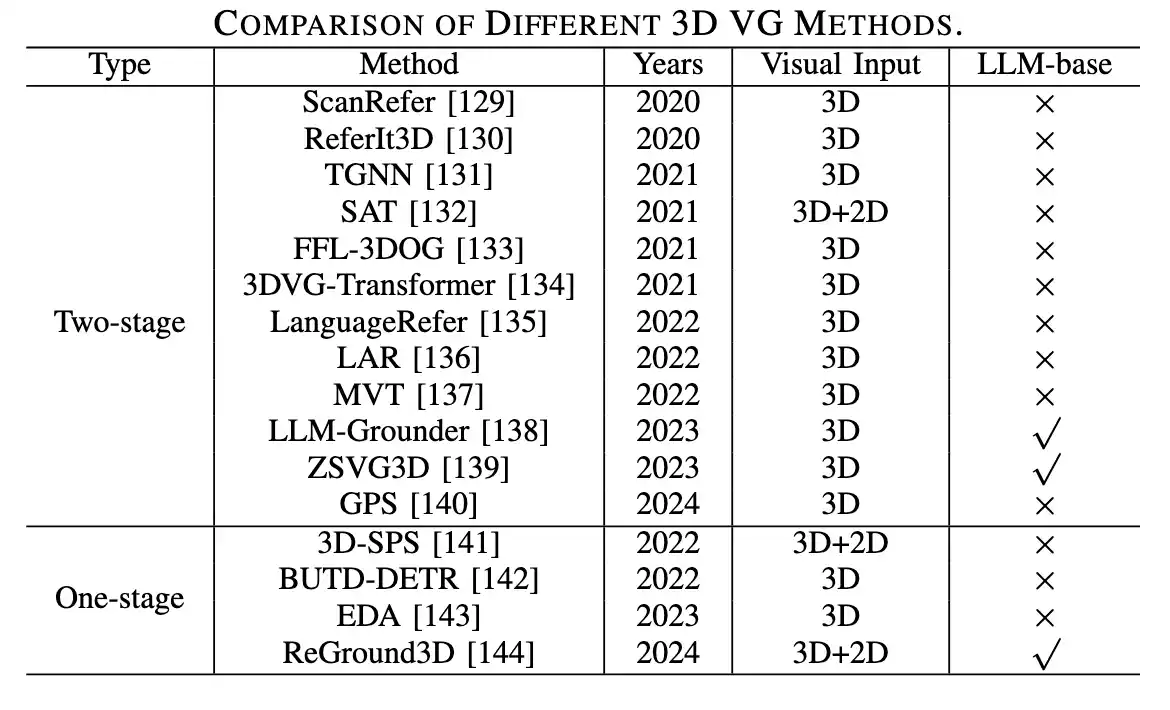
两阶段3D VG : Two-Stage 3D Visual Grounding Methods
类似于2D任务,3D grounding的早期研究主要通过两个阶段的检测然后匹配流程。早期现实用预训练的检测器或者分割器,从3D场景中的众多 3D目标 建议(proposal)中提取特征,然后将其与 语言查询特征融合 来匹配得到目标对象。
重点主要在第二阶段(语言查询的特征和3D对象proposal的特征相关性找到最佳匹配)。例如Referlt3D、TGNN不仅学习将proposal特征与文本embedding相匹配,而且还通过图神经网络对对象之间的上下文关系进行编码,增强对物体的理解。
最近随着transformer在NLP和CV中的出色表现,很多研究通过transformer提取融合视觉语言特征。
LanguageRefer 基于 Transformer 的架构,结合了 3D 空间嵌入、语言描述和类标签嵌入,以实现强大的 3D 视觉定位。
3DVG-Transformer是一种用于 3D 点云的关系感知视觉定位方法,具有用于关系增强提案生成的坐标引导上下文聚合模块和用于跨模式提案消歧的多重注意模块。
为了实现对 3D 对象和引用表达式进行更细粒度的推理,TransRefer3D使用实体和关系感知注意力增强了跨模态特征表示,结合了自我注意力、实体感知注意力和关系感知注意力。
现有的 3D VG 方法通常依赖于大量标记数据进行训练,或者在处理复杂语言查询时表现出局限性。结合LLM的强大的语言理解能力:
LLM-Grounder 提出了一种不需要标记数据的开放词汇 3D VG流水线:利用LLM 分解查询 并生成 对象识别计划 ,然后评估空间和常识关系以选择最匹配的对象。
ZSVG3D 设计了一种零样本 开放词汇 3D VG方法,该方法使用 LLM 来识别相关对象并执行推理,将此过程转换为脚本化视觉程序,然后转化为可执行的 Python 代码来预测对象位置。捕获依赖于视图的查询并理解 3D 空间中的空间关系。
但是 这些两阶段方法面临着确定proposal数量的困境,因为第一阶段的3D检测器需要采样关键点来表示整个3D场景并为每个关键点生成相应的proposal。 稀疏的proposal可能会忽略第一阶段的目标,从而使它们在第二阶段无法匹配。 相反,密集的proposal可能 包含 冗余 对象,由于proposal间关系过于复杂,导致第二阶段的目标区分困难。此外,关键点采样策略与语言无关,这增加了检测器识别与语言相关的proposal的难度。如图所示:
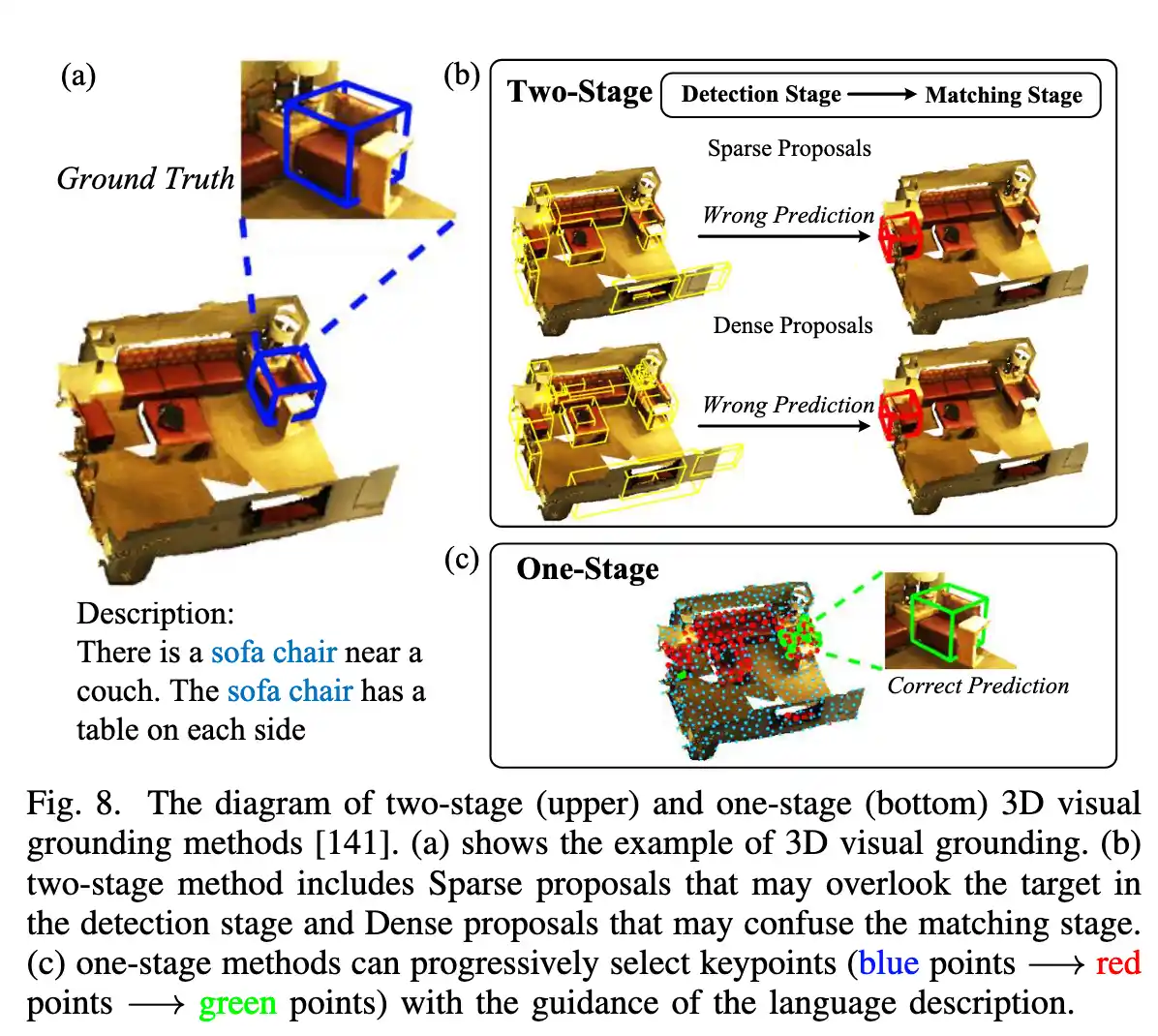
一阶段3D VG : One-Stage 3D Visual Grounding Methods
#TODO 介绍一下这个流程
二阶段是先 给出 proposal 然后在 对 这些proposal与给出的文字特征进行匹配。
而一阶段3D Visual Grounding则是 通过 语言查询queries 把 特征提取 和 目标检测 集成在
起。根据语言描述逐步选择关键点。有的方法(MDFETR,GLIP)会提取 耦合所有单词的在句子中的特征 或者 直接更关注描述中的 物品名称,但是忽略单词中的信息。 EDA提出了解耦句子中的文本属性。
视觉语言导航 Visual Language Navigation
以视觉观察以及语言指令作为输入,使robot具有在环境中穿梭的能力。
旨在使Agent可以 根据语言指令穿越于位置的环境中。要求agent可以理解复杂多样的视觉观察对象,以及不同粒度的语言指令。一般来说 VLN 有 视觉信息 和 语言指令 作为输入。
视觉信息:所经过的轨迹上的观察视频、或者 一组 时序 观察图片。
语言指令:Agent 需要达到的目标 或者 需要完成任务。完整的目标、粗略的任务描述。
Navigation:Embodied Agent 则通过 上面的信息,从候选动作列表中选择 一个或者一组 动作 来执行以满足要求,单个任务或者有交互的任务,公式如下:
其中
在VLN任务中,成功率(Success Rate,性能)、轨迹长度(Trajectory Length,效率)、成功每单位路径 SPL(Success Weighted by Path Length,综合指标).
用到的数据集
由于语言指令的 详细程度不一,要求的Agent完成的任务有无交互动作、顺序要求,对VLN有不同的挑战。基于这些差异有以下数据集:
- Room to Room ,基于Matterport3D,代理根据分步指令进行导航,根据视觉观察选择下一个相邻的导航图节点前进,直到到达目标位置。代理需要动态跟踪进度,以使导航过程与细粒度指令保持一致。
- Room for Room,将R2R中的路径延伸到更长的轨迹,这需要实体代理更强的远程指令和历史对齐能力。
- VLN-CE,将R2R和R4R扩展到连续环境,体现的智能体可以在场景中自由移动。这使得实体主体的行动决策变得更加困难。
- TOUCHDOWN,基于Google Street View和Matterport3D模拟器创建,代理按照指令在纽约市的街景渲染模拟中导航,以找到指定的对象。
- REVERIE要求具身智能能够准确定位由简洁的、人工注释的高级自然语言指令指定的远处不可见的目标物体,这意味着具身智能体需要在大量的物体中找到场景中的目标物体。
- SOON,代理接收从粗到细的长而复杂的指令,以在 3D 环境中找到目标对象。在导航过程中,智能体首先搜索较大的区域,然后根据视觉场景和指令逐渐缩小搜索范围。这使得SOON的导航具有目标导向性并且与初始位置无关。
- DDN,只提供人类需求,而不指定明确的对象。代理需要在场景中导航以找到满足人类需求的对象。
- ALFRED,基于AI2-THOR 模拟器,实体需要理解环境观察结果,并根据粗粒度和细粒度的指令在交互环境中完成家务任务。
- DialFRED 是 ALFRED 的扩展,允许代理在导航和交互过程中提出问题以获得帮助。这些数据集都引入了额外的预言(Additional Oracles),Agent需要通过提问来获取更多有利于导航的信息。
- OVMM,基于Habitat 模拟器,Agent需要在未知环境中拾取任何对象并将其放置在指定位置。智能体需要在家庭环境中定位目标物体,导航并抓取它,然后导航到目标位置并放下该物体。
- Behaviour-1K ,基于OmniGibson 模拟器。基于人类需求,包含 1,000 个长序列、复杂、依赖技能的日常任务。智能体需要完成长跨度的导航交互任务,其中包含数千个基于视觉信息和语言指令的低级操作步骤。这些复杂的任务需要很强的理解和记忆能力。
- CVDN 要求实体代理根据对话历史导航到目标,并在不确定时提出问题以帮助决定下一步行动。
相关的方法
受到到LLM影响,主要分为两个方向:Memory Understanding Based ,Future-Prediction Based。
基于记忆理解 Memory Understanding Based - Past Learning
侧重于对环境的感知和理解,模型 大多 根据对历史轨迹上的观察进行设计。并且由于 VLN 任务 属于 部分可观测的 马尔可夫决策过程,其中的未来状态的观测结果取决于当下智能体在环境中的行为。历史信息对于navigation的决策有很大作用。所以基于记忆的方法也是主流方法。
基于图的学习是该方法的重要组成部分,通常以图的形式表示navigation的过程,Agent在每个时间节点得到信息编码为图的一个节点。然后通过全局或者部分的图信息作为历史信息。Navigation Graph 将环境离散化,但是理解编码环境也是重要的部分。还有结合大模型,应用大模型强大的理解记忆能力。下面是一些方法:(有些对编码进行改进,有些侧重于理解方式以及信息处理,还有的结合LLM)
- LVERG分别编码每个节点的语言信息和视觉信息,设计新的语言和视觉实体关系图来建模文本和视觉之间的模态间关系以及视觉实体之间的模态内关系。
- LM-Nav 使用目标条件距离函数来推断原始观测集之间的联系并构建导航图,并通过LLM从指令中提取地标,使用视觉语言模型将它们与导航图的节点进行匹配。
- HOP不是基于图学习,但其方法与图类似,要求模型对不同粒度的时间有序信息进行建模,从而实现对历史轨迹和记忆的深入理解。
- VER 通过 2D-3D 采样将物理世界量化为结构化 3D 单元,提供细粒度的几何细节和语义。不同的学习方案探索如何更好地利用历史轨迹和记忆。
- 通过对抗性学习,CMG在模仿学习和探索激励方案之间交替,有效加强了对指令和历史轨迹的理解,缩短了训练和推理之间的差异。
- GOAT通过后门调整因果学习(BACL)和前门调整因果学习(FACL)直接训练无偏模型,与视觉、导航历史及其组合到指令进行对比学习,使智能体能够更充分地利用信息。
- RCM提出的增强型跨模态匹配方法使用面向目标的外部奖励和面向指令的内部奖励来进行全局和局部的跨模态接地,并通过自监督模仿学习从自己的历史良好决策中学习。
- FSTT将TTA引入VLN,并在时间步和任务两个尺度上对模型的梯度和模型参数进行优化,有效提高了模型性能。
- NaviLLM通过视觉编码器将历史观察序列集成到嵌入空间中,将融合编码的多模态信息输入到LLM中并对其进行微调,在多个基准上达到了state-of-the-art。
- NaVid对历史信息的编码进行了改进,通过不同程度的池化实现对历史观测值和当前观测值的不同程度的信息保留。
- DiscussNav将不同能力的大型模型专家分配给不同的角色,驱动大型模型在导航动作之前进行讨论以完成导航决策,并在零样本VLN中取得了优异的性能。
基于未来预测 Future-Prediction Based - Future Learning
这种方法更注重对未来状态的理解、建模以及预测。这种方式对环境有更加深刻的理解,尤其是在连续环境中。
基于未来预测的Visual Language Navigation方法(未来预测视觉语言导航)主要旨在通过对环境和未来路径的预测,提升导航模型在未知环境中的表现和决策能力。该方法主要通过图学习和环境编码来预测可行路径和未来观测,从而简化复杂的导航任务,帮助模型在从离散环境过渡到连续环境时更好地表现。
-
图学习和路径预测:在未来预测方法中,常利用图学习进行路径点预测。例如,BGBL和ETPNav方法通过当前导航图节点的观测来预测可移动路径点,旨在通过从离散到连续环境的迁移,提升导航的精确度和稳定性。
-
环境编码:为了更好地理解未来环境,NvEM模型设计了一种融合编码方法,通过主题模块和参考模块从全局和局部视角对邻近视野进行编码。这种方法帮助导航模型学习对未来观测的理解,从而更加准确地预测未来环境。
-
多级表示与路径树构建:HNR模型采用层级神经辐射表示来预测未来环境的视觉表示,通过三维特征空间编码构建可导航的未来路径树。这种方法从不同层级预测未来环境,为导航决策提供了更丰富的参考。
-
强化学习的应用:部分方法采用强化学习进行未来状态的预测。例如,LookBY利用强化学习让预测模块模拟未来的状态和回报,这样可以将“当前观测”和“未来观测的预测”直接映射为行动,从而显著提升导航的表现。
-
大型模型的‘想象’功能:大型语言模型的丰富世界知识和零样本能力,为未来预测方法提供了新的可能性。比如,MiC模型要求语言模型根据指令直接预测目标及其可能位置,通过场景感知来提供导航指示。这一方法要求大型模型充分发挥‘想象力’,并通过提示词构建假想场景来辅助导航。
非视觉感知(触觉 Non-Visual Perception: Tactile
触觉感知是具身智能体在物理世界中理解和操作物体的一项重要能力,它能够提供关于物体的纹理、硬度和温度等详细信息,帮助智能体更精确地执行复杂任务。通过触觉传感器,智能体可以在实际操作中获得与视觉信息互补的触觉数据,增强其在高精度任务中的表现。
在触觉感知任务中,传感器设计 决定了Agent获取的信息, 然后介绍数据集 ,最后介绍 触觉感知方法。
预备:传感器设计、数据集介绍
在触觉信息获取中,传感器有三类:
-
非视觉(Non-vision-based)传感器:主要使用电学和机械原理,感知力、压力、振动和温度等低维度信息,代表如BioTac。此类传感器直接测量触觉物理量,适用于检测简单触觉信息。
-
视觉(Vision-based)触觉传感器:基于光学原理,通过图像(触觉表面的纹理和形变)来捕获触觉信息。例如GelSight和DIGIT传感器利用凝胶表面的变形图像来感知物体表面特性,应用广泛,尤其是在需要精细触觉信息的场景中。

-
多模态(Multi-modal)传感器:视觉触觉传感器和非视觉触觉传感器,模仿人类皮肤,整合压力、接近度、加速度和温度等多种信息,采用柔性材料设计,能够提供更加全面的触觉数据,提升智能体的适应性和灵活性。
多模态传感器是指能够同时采集和融合多种不同类型信息的传感器,模拟人类多感官整合的能力。它们常用于具身AI和机器人系统中,通过集成触觉、温度、压力、接近度等不同的感知模式,帮助智能体更全面地理解物体或环境特性。这类传感器的设计灵感源于人类皮肤,它们的应用可以有效提升机器人的感知能力,尤其在精细操作和动态环境下表现出色。
多模态传感器的主要类型和特点
- 压力和触觉组合:同时感知压力和表面触觉细节,这一组合通常采用柔性材料传感器,能够检测物体硬度、表面纹理和接触压力。典型应用包括抓取力控制和柔性操作。
- 接近度与触觉组合:可以在不直接接触物体的情况下检测其存在和距离(接近度),并在接触后感知表面细节。接近度传感器如电容式或红外式传感器,结合触觉传感器,广泛应用于避免碰撞和精细抓取。
- 温度与触觉组合:感知温度变化和表面特性,帮助机器人判断物体的材质和状态,如液体温度或表面湿度变化。常用于食品处理、医疗领域等温度敏感的任务。
- 压力、加速度与触觉组合:通过集成压力和加速度传感器,机器人不仅能感知表面信息,还能感知物体的运动和振动模式。该组合特别适合检测对象的振动、滑动和稳定性,提升操作的精确性。
多模态传感器的应用场景
• 人机交互:在机器人手指或表面上安装多模态传感器,可以帮助其识别手握物体的力道、温度变化等,提升人机协作的安全性和准确性。
• 复杂抓取与操作:在工业和服务机器人中,能确保机器人适应多种物体类型和不同操作环境,增强稳定性和适应性。
• 环境监测与适应:多模态传感器能帮助机器人更好地适应不同环境,例如识别火灾中的高温环境,或在湿滑环境中保持平衡。
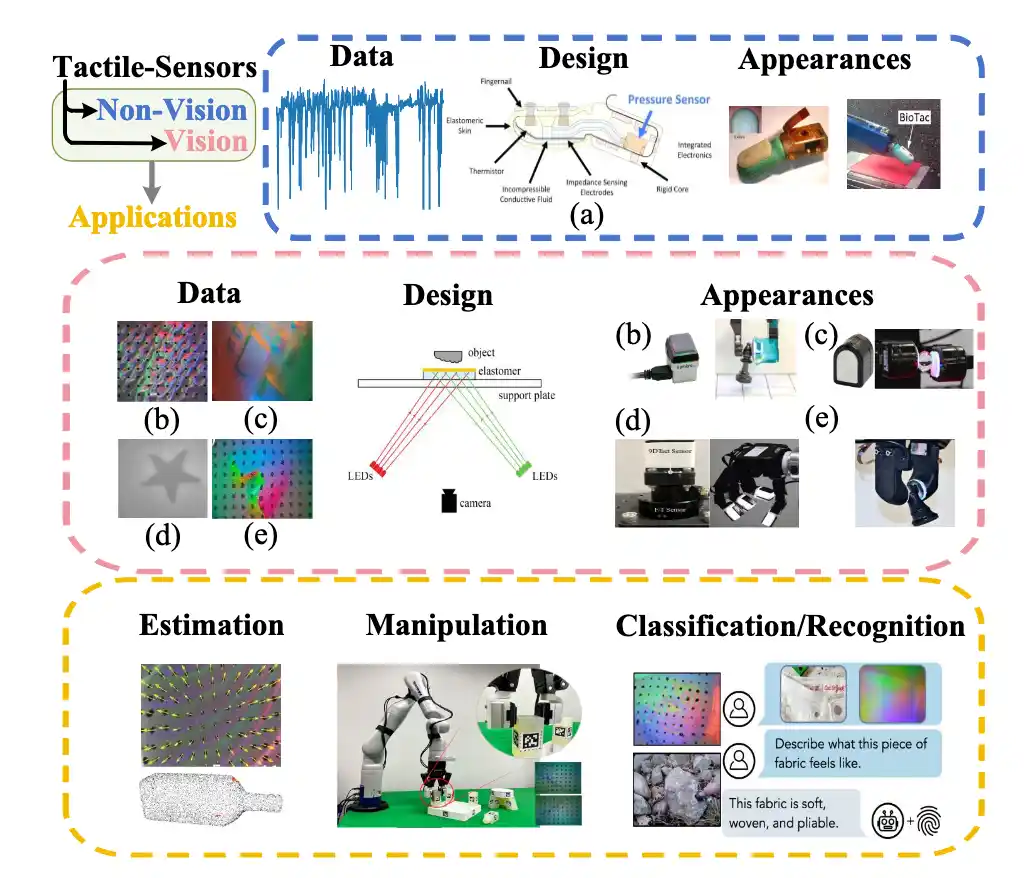
数据集则有如下几种:
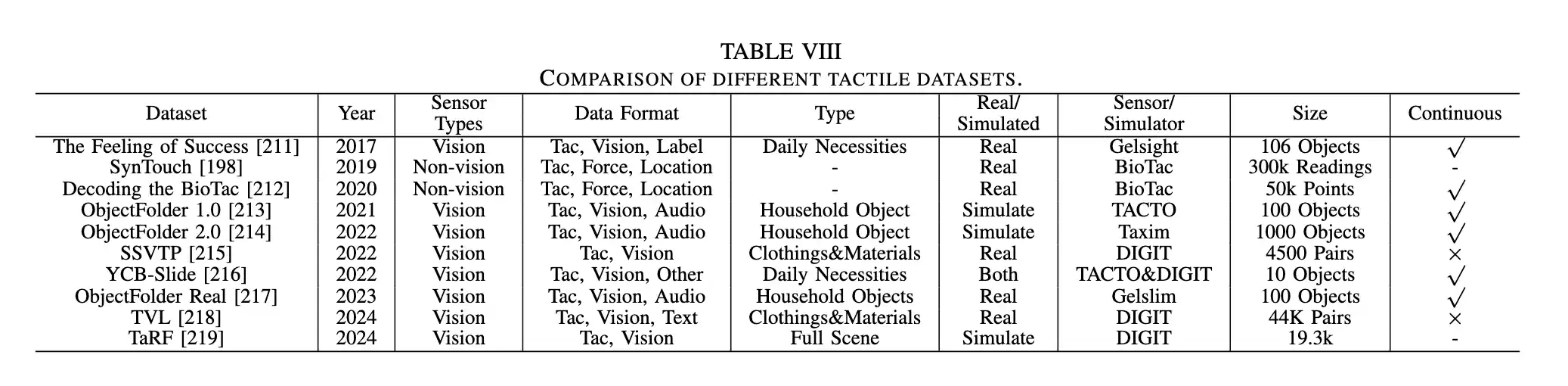
- 非视觉传感器数据集:主要由BioTac等传感器采集,包含电极值、力向量和接触位置,适用于力估计和抓取操作的研究。
- 视觉传感器数据集:采集凝胶变形的高分辨率图像,包含丰富的对象数据,如日常物品、自然环境、不同材料等。此类数据集可用于精细的纹理识别和操作任务。
触觉感知 方法 - 根据应用 讲 对应方法
触觉感知的应用被分为3类:触觉估计、机器人操作、多模态信息融合(分类、识别)。每种应用中都有一些方法。
触觉估计 Tactile Estimation
在触觉感知中的估计(Estimation)任务里,研究主要集中在物体的形状、力以及滑动检测的估计。以下是估计任务的主要方法和发展:
-
早期方法
研究人员最初通过简单的阈值方法或卷积神经网络(CNN)来处理形状、力和滑动测量。这些方法基于触觉图像的颜色变化和标记物分布的变化来推断物体信息。 -
触觉图像生成:
触觉图像生成是估计任务的重要组成部分,目标是将视觉数据转换为触觉图像。最初的研究使用RGB-D图像作为输入,通过深度学习模型输出触觉图像。近年来,随着图像生成技术的快速发展,Higuera等人和Yang等人应用扩散模型(Diffusion Model)生成触觉图像,效果显著提升。触觉图像的生成通常基于触觉传感器表面与物体接触时的变形或压痕,传感器通过内置的摄像头或压力分布图记录下变形情况,变形数据被处理为图像,可以进一步用于分析物体的特性,如表面纹理、硬度、接触力等。
-
物体重建:
物体重建任务分为二维和三维重建:
- 二维重建:主要关注物体的形状和分割。
- 三维重建:关注物体表面、姿态,甚至是整个场景的感知。早期方法多采用数学方法、自编码器和神经网络,将视觉和触觉特征(有时包括点云)结合,实现物体的重建。
机器操作 Robotic Manipulation
Robotic Manipulation中的触觉任务涉及通过触觉感知实现对物体的精细操作,其中弥合模拟到真实环境(Sim-to-Real)的差距至关重要。为了实现高精度、实时的操作任务。
有 基于强化学习 和 基于生成对抗网络(GAN) 两种主要方法。
强化学习方法
- Visuotactile-RL:为现有强化学习方法提出了改进,包括触觉门控、触觉数据增强和视觉降质处理等。这些改进措施使触觉感知在复杂环境中更具鲁棒性。
- Rotateit:这是一个基于多模态感知输入的指尖物体多轴旋转系统,利用了带特权信息的强化学习策略进行网络训练,并实现了在线推理。
- 基于触觉的目标设定:提出了一种基于深度强化学习的目标导向物体推动方法,完全依赖触觉感知,并采用了基于目标的模型无关和模型驱动强化学习策略,使机器人能够精确地将物体推动至目标位置。
- AnyRotate:关注手持物体的多轴旋转操作,该系统利用触觉密集特征构建了连续接触特征表示,提供触觉反馈以在模拟环境中训练策略,同时通过训练观测模型来实现零样本策略转移,有效地缩小了Sim-to-Real差距。
GAN-Based
- ACTNet 提出了一种无监督的对抗域适应方法来缩小像素级触觉感知任务的域差距。引入了自适应相关注意机制来改进生成器,该生成器能够利用全局信息并关注显着区域。然而,像素级域自适应会导致错误累积、性能下降、结构复杂性和训练成本增加。
- STR-Net 提出了一种用于触觉图像的特征级无监督框架,缩小了特征级触觉感知任务的sim-real gap
材料识别
触觉感知任务中的识别任务主要集中于材料分类和多模态理解。研究方法可以分为传统方法和基于大型语言模型(LLMs)与视觉语言模型(VLMs)的方法。
传统方法(Traditional Methods)
传统方法主要依赖于自动编码器、自监督学习以及联合训练,以提升触觉表示学习的效果。方法如下:
- 自动编码器(Autoencoder):用于生成简洁的触觉数据表示,减少数据维度以提升处理效率。
- Polic等人使用卷积神经网络自动编码器对光学触觉传感器图像进行降维。
- Gao等人设计了一个监督型递归自动编码器,处理异构传感器数据集。
- Cao等人提出了TacMAE,一个用于处理不完整触觉数据的掩码自动编码器。
- Zhang等人引入了MAE4GM,这是一种多模态自动编码器,能够整合视觉和触觉数据。
- 联合训练方法(Joint Training Methods):为了将触觉与其他模态相结合,联合训练方法在触觉表示学习中起到关键作用。
- Yuan等人训练了包含深度、视觉和触觉数据的卷积神经网络(CNNs)。
- Lee等人采用变分贝叶斯方法,整合了多模态传感器数据(如力传感器序列和末端执行器度量数据)。
- 自监督方法(Self-supervised Methods):自监督学习通过对比学习将不同模态数据结合,进一步增强触觉表示。
- Lin等人简单地将触觉输入与多种视觉输入配对。
- Yang等人使用视觉-触觉对比多视角特征。
- Kerr等人采用了InfoNCE损失,Guzey等人则使用了BYOL方法。这些对比学习方法在触觉表示学习中奠定了坚实基础。
基于LLMs和VLMs的方法
大型语言模型(LLM)和视觉语言模型(VLM)最近在跨模态理解和零样本学习方面表现出色。以下是其在触觉识别中的应用:
• 对比预训练(Contrastive Pretraining):研究者通过对比预训练方法,将触觉数据与视觉和语言模态对齐。
• Yang等人、Fu等人和Yu等人都采用了对比学习方法,将触觉数据编码并与视觉、语言模态对齐。
• 任务适配(Task Adaptation):通过如LLaMA等大型语言模型的微调,可以实现如触觉描述等具体任务。大型语言模型和视觉语言模型在理解触觉数据并跨模态生成描述上展示了优越性能,进一步推动了触觉表示学习的进展。
具身交互 Embodied Interaction
具身交互是指Agent在物理或者虚拟世界中与环境交互的任务场景。经典的具身交互任务有 Embodied问答 、 具身智能体抓取任务。
具身问答 Embodied Question Answering
在EQA(Embodied Question Answering)任务中,智能体需要从第一人称视角探索环境,以收集必要信息来回答指定问题。具备自主探索和决策能力的智能体不仅需要选择合适的行动来探索环境,还需判断何时停止探索以回答问题。现有研究关注不同类型的问题。
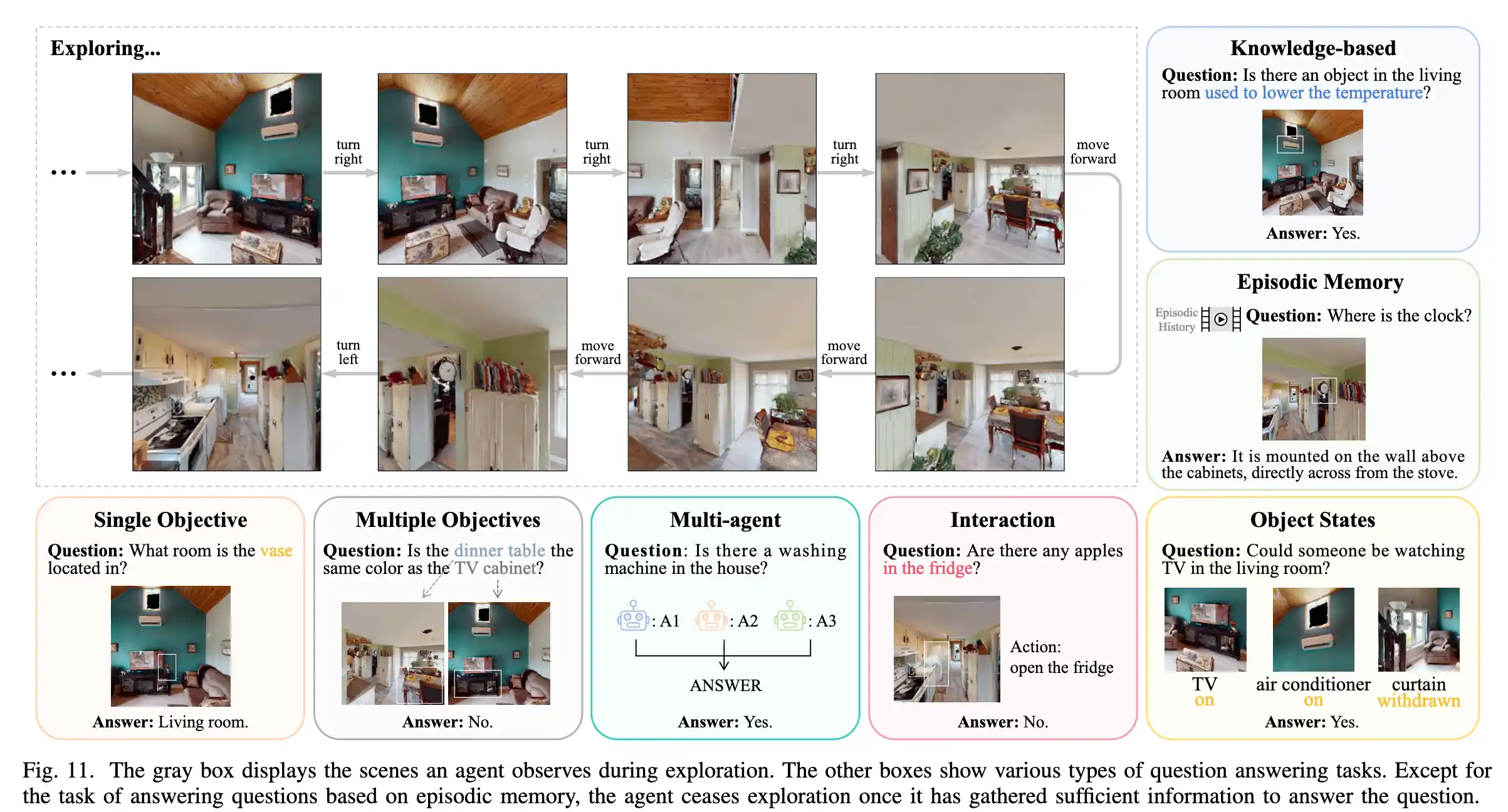
类型如下
-
Single Objective(单一目标):例如“花瓶在哪个房间?”这种问题类型要求智能体找到特定物体或位置的单一信息。智能体需要进行环境探索,定位到物品的具体位置才能回答问题。
-
Multiple Objectives(多重目标):例如“餐桌和电视柜的颜色是否相同?”这种类型的问题涉及多项物体之间的比较。智能体需要找到并观察多个物体的特性,并对比分析后得出答案。
-
Multi-agent(多智能体):例如“屋内是否有洗衣机?”这是一个多智能体协作的问题类型。多个智能体可以在不同区域独立探索,然后将各自的信息整合起来以得出答案。
-
Interaction(互动):例如“冰箱里有苹果吗?”这种类型要求智能体进行特定的互动行为(如打开冰箱)来获取答案。这种问题类型测试了智能体的交互能力。
-
Knowledge-based(基于知识):例如“客厅里有能降低温度的物品吗?”这种类型需要智能体结合已有的知识(如空调的用途)来解答问题,而不只是依赖视觉识别。
-
Episodic Memory(情景记忆):例如“钟在哪里?”这种问题类型需要智能体记住之前探索过程中的视觉信息,基于情景记忆来提供答案,避免重复探索。
-
Object States(物体状态):例如“有人可以在客厅看电视吗?”这种类型的问题关注环境中物体的当前状态(如电视是否打开、窗帘是否拉开),通过状态判断来推断可行性或答案。
数据集
由于实际环境中机器人实验受限于场景和硬件,模拟器作为虚拟实验平台,为构建EQA数据集提供了合适的环境条件。在模拟器中训练和测试模型显著降低了实验成本,并提高了模型在真实机器上部署的成功率。本文简要介绍了几个EQA数据集,如表IX所示。
• EQA v1:第一个设计用于EQA的数据集,基于SUNCG数据集中的合成3D室内场景,通过House3D模拟器生成,包含了四种类型的问题:位置、颜色、颜色房间和介词问题,分布在750多个环境中,共5000多个问题。
• MT-EQA:在House3D中构建,基于SUNCG,扩展至多物体设置,设计了包括颜色、距离和大小比较在内的六种问题类型,涵盖588个环境中的19287个问题。
• MP3D-EQA:基于Matterport3D数据集开发的模拟器MINOS,扩展了EQA任务到真实3D环境,生成了包含位置、颜色、颜色房间等问题的1136个问题,覆盖83个家庭环境。
• IQUAD V1:在AI2-THOR上构建,包含存在、计数和空间关系三种问题类型,通过预设模板生成了75000多个选择题,每个问题均有独特的场景配置,要求智能体具备较强的互动能力。
• VideoNavQA:将视觉推理与导航分离,生成了101000对视频和问题,问题分布在House3D环境中,涵盖存在、计数和定位等八大类28种问题。
• SQA3D:专注于场景理解,基于ScanNet场景数据提供6800个独特情境、20400个描述和33400个推理问题。
• K-EQA:在AI2Thor上构建,增加了逻辑关系和知识图谱,包含6000个不同环境中的60000个问题。
• OpenEQA:首个开放词汇EQA数据集,支持情节记忆(EM-EQA)和主动探索(A-EQA)两种任务,覆盖180多个真实环境中的1600多个问题。
• HM-EQA:利用GPT-4生成的问题数据集,包含500个问题,涵盖识别、计数、存在、状态和位置问题。
• S-EQA:利用GPT-4在VirtualHome中生成数据,基于余弦相似度筛选数据,增强了数据集的多样性,通过判断物体状态集合是否达到存在性”是/否”的结论来回答问题。
方法介绍
在EQA(Embodied Question Answering)任务中,主要涉及导航和问答子任务。实现方法可分为两类:基于神经网络的方法和基于LLMs(大规模语言模型)/VLMs(视觉语言模型)的方法。
神经网络方法
神经网络方法侧重于模块化设计和任务复杂度扩展
早期方法:最初,研究人员主要通过深度神经网络来解决EQA任务。这些模型使用模仿学习和强化学习等技术进行训练和微调。Das等人提出的EQA模型包含视觉、语言、导航和回答四个模块,主要通过卷积神经网络(CNN)和循环神经网络(RNN)构建,并采用两阶段训练:先利用自动生成的导航示范数据对导航和回答模块进行独立训练,再通过策略梯度法微调导航架构。
后续改进:后续研究在保持基本模块的基础上,通过将导航和问答模块整合至统一的随机梯度下降(SGD)训练流程中,以实现联合训练,避免深度强化学习的复杂性。
复杂性扩展:为增加任务的复杂性,有些研究扩展了多目标和多智能体任务。通过特征提取和场景重建等方法,模型能够整合智能体探索中获取的信息。
动态环境中的交互:为处理智能体与动态环境的交互,Gordon等人引入了分层交互记忆网络,结合任务选择的规划器和执行任务的低层控制器,并使用Egocentric Spatial GRU(esGRU)存储空间记忆。
外部知识的引入:针对之前模型在应对复杂问题时无法利用外部知识的缺陷,Tan等人提出了一个框架,利用神经程序合成方法和知识/3D场景图表,帮助智能体获取与对象相关的信息,并通过蒙特卡洛树搜索(MCTS)确定智能体的下一步移动位置。
LLMs/VLMs方法
LLMs/VLMs方法则利用其自然语言处理和视觉理解的强大能力,通过探索和语言描述等手段更高效地处理EQA任务。
• 任务应用:随着LLMs和VLMs的快速发展,研究人员尝试在EQA任务中应用这些模型,而不进行额外的微调。Majumdar等人探索了将LLMs和VLMs用于情景记忆EQA(EM-EQA)任务和主动EQA(A-EQA)任务。对于EM-EQA任务,他们使用盲LLM、带情景记忆语言描述的Socratic LLMs、场景图描述的Socratic LLMs以及处理多帧场景的VLM。
- EM-EQA
-
盲LLM(Blind LLM):这是指在没有视觉输入的情况下,仅通过语言输入来回答问题的LLM。这种模型只能依赖文本描述,因此在环境探索任务中具有明显的局限性,因为它无法“看到”周围环境。
-
带情景记忆语言描述的Socratic LLM(Socratic LLM with Episodic Memory Descriptions):这是指一种Socratic方法的LLM,这种方法通过文字描述来存储和传递情景记忆。智能体在探索环境的过程中会积累情景记忆,这些记忆被转换为语言描述输入到LLM中,帮助它回答基于历史探索信息的问题。
-
场景图描述的Socratic LLM(Socratic LLM with Scene Graph Descriptions):这种Socratic方法的LLM接收的是场景图的描述。场景图是一种结构化的图表,展示了环境中的对象及其关系,通过这种图表描述输入,LLM可以利用这些信息更好地理解环境中的空间和物体分布,从而回答问题。
-
处理多帧场景的VLM(VLM Processing Multiple Scene Frames):VLM(视觉语言模型)在这里用来处理多帧图像信息。它通过接收来自环境的多个视角或帧的图像输入,结合语言信息来推断和回答问题。多帧场景信息让VLM能够更全面地感知环境,增强其回答问题的准确性。
-
• 前沿探索方法:在A-EQA任务中,使用基于前沿探索(FBE)的方法以进行问题无关的环境探索,一些研究使用FBE识别待探索区域并构建语义地图。此外,采用一致性预测或图像-文本匹配等技术避免过度探索。
• 回答强化:Patel等人则重点关注问答任务,利用多智能体LLM探索环境,并独立给出“是”或“否”的回答,随后由中央回答模型汇总各智能体的反馈,生成更稳健的答案。
度量标准
在EQA任务中,模型的性能评估通常基于导航和问答两个方面:
-
评估指标:
导航指标:许多研究沿用Das等人提出的方法,采用以下指标来评估导航性能:• dT:导航完成时与目标物体的距离。
• d∆:从初始位置到最终位置的目标距离变化量。
• dmin:在整个导航过程中,智能体与目标的最小距离。
-
问答指标:问答性能评估主要包括:
• 平均排名(MR):正确答案在候选答案列表中的平均排名。
• 准确率:答案的准确率。
• LLM-Match:由Majumdar等人提出的指标,用于评估开放词汇答案的正确性,该指标结合了LLM的正确性评估。此外,他们通过将智能体路径的归一化长度作为权重,引入了路径效率的评估。
-
局限性:
• 数据集:构建数据集需要大量人力和资源,目前的大规模数据集仍然较少。此外,各个数据集的评估指标并不一致,这使得不同模型之间的测试和性能对比变得复杂。
• 模型:尽管LLM的进步提升了模型的表现,但与人类水平仍有显著差距。未来的研究可能更多地关注如何高效存储智能体探索的环境信息,指导智能体基于环境记忆和问题进行行动规划,同时增强其行为的可解释性。
具身抓取 Embodied Grasping
具身交互不仅涉及与人类的问答互动,还包括根据人类指令执行操作,如抓取和放置物体,从而完成机器人、人类和物体之间的交互。体感抓取要求智能体具备全面的语义理解、场景感知、决策能力以及稳健的控制规划。
具身抓取方法将传统的机器人运动学抓取技术与大规模模型(如LLMs和视觉-语言基础模型)相结合,使智能体能够在多感官感知下执行抓取任务,包括视觉主动感知、语言理解和推理等能力。这种整合使得智能体能够通过视觉、语言和语义的协同工作,更高效地完成复杂的抓取任务。
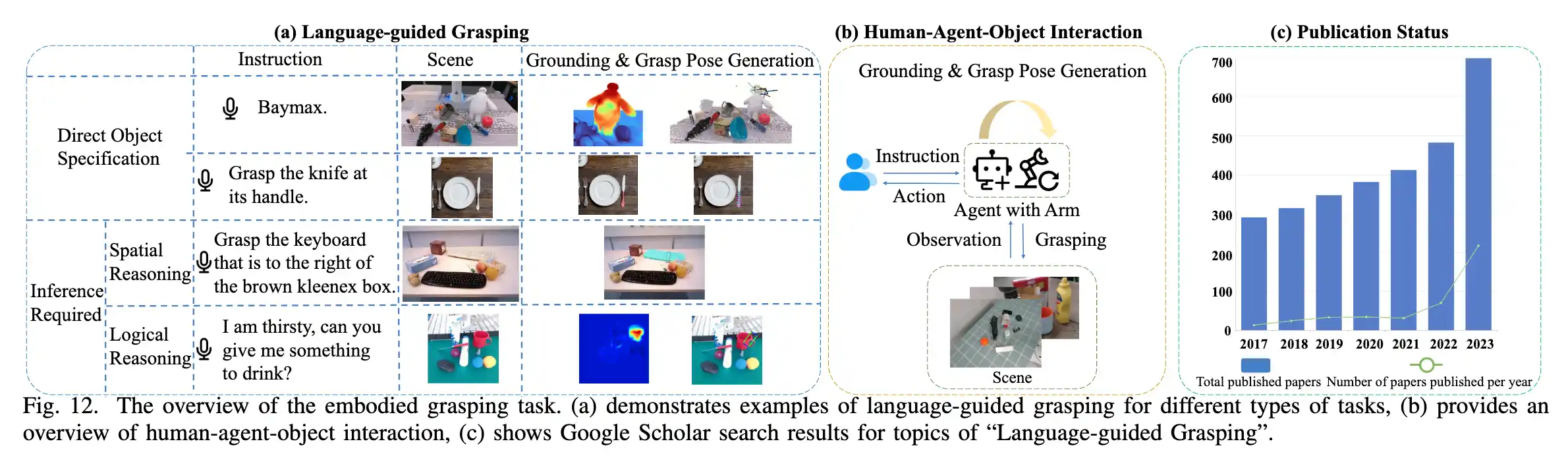
上图是这个Embodied Grasping任务的概述。
(a). 针对不同类型任务的语言引导抓取示例
(b).人-智能体-物体的交互概览,智能体在其中完成体感抓取任务,体现了智能体如何根据人类的指令与周围物体进行物理操作的能力。这种交互不仅增强了机器人在家用服务和工业环境中的实用性,还让机器人在多感官整合下对语义和场景理解的复杂任务中表现得更加智能。
©.显示“Language Guided Grasping”主题的谷歌学术搜索结果
抓取器
目前抓取器主要有以下两种:
-
两指平行夹爪:抓取姿态通常分为两种类型:
-
4-DOF(四自由度):通过三维位置和顶向手部方位(偏航角)来定义抓取姿态,通常称为“顶向抓取”。
-
6-DOF(六自由度):通过六维的位置和方向来定义抓取姿态,增加了灵活性,可以适应更复杂的抓取场景。
-
-
五指灵巧手:例如ShadowHand,是一种常用的五指机器人灵巧手,具有26个自由度。高自由度带来了生成有效抓取姿态和规划执行轨迹的复杂性,但也使其具备了更高的抓取灵活性,适合处理复杂的抓取任务。
数据集
为了支持具身抓取任务的研究,研究人员生成了大量的抓取数据集。这些数据集通常包含基于图像(RGB、深度)、点云或3D场景的抓取标注数据。随着多模态大模型(MLMs)和基础语言模型在机器人抓取领域的应用需求的增加,现有数据集也被扩展或重构为语义抓取数据集。这些数据集在研究基于语言的抓取模型时起到了关键作用,使智能体能够建立广泛的语义理解。
传统抓取数据集包括单一物体场景和复杂物体堆叠场景,提供符合运动学的稳定抓取标注(4-DOF或6-DOF)。这些数据可以从真实桌面环境中收集,通常包含RGB、深度和点云数据,或来自虚拟环境中的图像、点云或场景模型。这些数据集虽然对抓取模型有用,但缺乏语义信息。因此,这些数据集通过加入语义表达得到了扩展,使语言、视觉和抓取任务能够结合起来。通过加入语义信息,智能体可以更好地理解和执行抓取任务,这一增强使得发展更复杂、更具语义感知的抓取模型成为可能,促进了与环境的更直观和有效的交互。

度量标准
在具身抓取任务中,深度学习的损失函数(loss)或优化目标主要取决于任务的具体目标,包括抓取姿态生成、物体识别、语言指令理解等多个方面。以下是常见的优化目标:
1. 抓取姿态生成损失(Grasp Pose Generation Loss)
- 回归损失:如果模型需要预测抓取的位置和角度,则会使用回归损失(如均方误差 MSE)来优化预测姿态和目标姿态之间的差异。
- 分类损失:在多种抓取姿态可选的情况下,使用交叉熵损失(Cross-Entropy Loss)来优化抓取姿态的选择。通过将每个候选姿态作为一个类别,模型可以学习选择最合适的抓取姿态。
2. 视觉和语言对齐损失(Vision-Language Alignment Loss)
- 对比损失(Contrastive Loss):在视觉-语言模型(如CLIPORT)中,通过对比损失函数来优化视觉和语言的对齐。例如,图像和描述的特征在嵌入空间中的距离应最小化,而与其他描述的距离应最大化。
- 嵌入空间损失:利用L2范数或余弦相似度等距离度量方法,优化图像特征和语言特征在共享嵌入空间中的相似性,以确保语义上相关的视觉和语言信息保持一致。
3. 多任务损失(Multi-task Loss)
- 具身抓取任务中可能包含多种子任务(如物体检测、抓取姿态选择、路径规划等),多任务损失会为每个子任务设置一个单独的损失函数,再通过加权的方式对所有损失进行优化。这样可以使模型在多个任务间取得平衡,提高任务的整体性能。
4. 物体检测与分割损失(Object Detection and Segmentation Loss)
-
分类损失:用于物体类别的识别,例如使用交叉熵损失来区分不同物体类别。
-
边界框回归损失(Bounding Box Regression Loss):用于预测物体的准确位置,通常使用平滑L1损失来最小化预测的边界框与真实边界框之间的差异。
-
分割损失:在需要精细分割的任务中,使用二值交叉熵损失或Dice系数损失来优化物体分割的准确性。
5. 抓取成功率损失(Grasp Success Loss)
- 为确保生成的抓取姿态能够成功抓取物体,许多具身抓取模型会定义一个二分类的成功率损失。该损失可以用二元交叉熵损失(Binary Cross-Entropy Loss)或对比损失等来衡量预测的抓取姿态是否能实现稳定抓取。
- 例如,在模拟器中标记每次抓取是否成功,然后训练模型最小化失败的概率,使得模型生成的姿态在真实环境中更具鲁棒性。
6. 强化学习奖励优化(Reinforcement Learning Reward Optimization)
- 在具身抓取中,如果使用了强化学习,优化目标会以奖励信号(reward)为核心。典型的奖励包括:
- 到达目标物体的奖励:智能体接近目标物体时给予正奖励。
- 完成抓取的奖励:成功抓取并保持物体不掉落给予高奖励。
- 路径优化:缩短到目标的路径长度或避免碰撞的奖励。
- 强化学习算法通过最大化累计奖励的方式优化抓取策略,例如策略梯度方法(如PPO)或Q-learning方法。
7. 场景重构和特征对齐损失(Scene Reconstruction and Feature Alignment Loss)
- 在模块化方法(如F3RM或GaussianGrasper)中,使用特征对齐或场景重构损失,优化模型对场景结构的理解。
- 重建损失:在3D场景中生成物体特征和空间结构时,可能会用到L2损失来最小化实际场景与重建场景之间的误差,以提高空间推理能力。
总结来看,具身抓取任务的深度学习优化目标通常涉及抓取姿态生成、视觉-语言对齐、多任务平衡、抓取成功率等多方面的损失,通过综合这些损失项,使得智能体能够在复杂环境中高效、准确地完成具身抓取任务。
语言引导抓取
语言引导抓取的概念从多模态模型的整合中演化而来,结合了多模态大模型(MLMs)以赋予智能体语义场景推理能力,使其能够根据人类的显式或隐式指令执行抓取操作。近年来,随着大规模语言模型(LLMs)的进步,研究人员对这一主题表现出越来越高的兴趣。
在当前的研究趋势中,抓取任务逐渐聚焦于开放世界场景,强调开放集泛化方法,通过MLMs的泛化能力,机器人能够在开放环境中更智能和高效地执行抓取任务。在语言引导抓取中,语义信息可以源自显式指令和隐式指令。
• 显式指令:指令明确指定要抓取的物体类别,例如“抓起香蕉”或“抓起苹果”。
• 隐式指令:需要推理来识别要抓取的物体或物体的某个部分,涉及空间推理和逻辑推理。
• 空间推理:指令可能包含物体或要抓取部分的空间关系,需要根据场景中物体的空间关系推断抓取姿态。例如,“抓取棕色纸巾盒右侧的键盘”需要智能体理解物体的空间排列并进行推理。
• 逻辑推理:指令可能包含需要推理的人类意图的逻辑关系,从而抓取目标。例如,“我渴了,你能给我点喝的吗?”这可能会促使智能体递上一杯水或一瓶饮料,智能体必须确保液体不会在传递过程中洒出,从而生成合理的抓取姿态。
通过将语义理解与空间和逻辑推理相结合,使得智能体能够高效准确地完成复杂的抓取任务。
端到端方法
端到端方法通过整合视觉和语言模型来完成从语义理解到抓取生成的全流程。
• CLIPORT:这是一个语言驱动的模仿学习智能体,结合了预训练视觉语言模型CLIP和Transporter Net,创建了一个端到端的双流架构,用于语义理解和抓取生成。该模型通过大量从虚拟环境中收集的专家示范数据进行训练,使智能体能够执行语义驱动的抓取任务。
• CROG:基于OCID数据集,提出了视觉-语言-抓取数据集,并引入了具有竞争力的端到端基准。它利用了CLIP的视觉基础能力,从图像-文本对中直接学习抓取合成。
• Reasoning Grasping:在GraspNet1 Billion数据集上首次引入推理抓取基准数据集,提出了一个结合多模态LLM与视觉抓取框架的模型,能够基于语义和视觉生成抓取姿态。
• SemGrasp:这是一种基于语义的抓取生成方法,将语义信息纳入抓取表示中,从而生成灵巧手的抓取姿态。引入了离散表示,将抓取空间与语义空间对齐,以根据语言指令生成抓取姿态。为了支持训练,还提出了一个大规模的抓取-文本对齐数据集CapGrasp。
模块化方法
模块化方法通过将语言和视觉特征分阶段处理,提升了模型的灵活性和可泛化能力。
• F3RM:此方法试图将CLIP的文本-图像先验扩展到3D空间,使用提取的特征进行语言定位,随后生成抓取姿态。它结合了精确的3D几何与2D基础模型中的丰富语义,利用CLIP提取的特征通过自然语言指定要操作的物体,展现了对未见表达和新物体类别的泛化能力。
• GaussianGrasper:利用3D高斯场实现语言引导抓取任务。该方法首先构建3D高斯场,然后进行特征提取,再基于提取的特征进行语言定位,最终通过最先进的预训练抓取网络生成抓取姿态。它结合了开放词汇语义和精确的几何特征,使得机器人能够根据语言指令执行抓取。
这些方法利用端到端和模块化框架,提升了机器人理解和执行复杂抓取任务的能力,借助自然语言指令,使得机器人能够完成更为复杂的任务。
具身智能体 Embodied Agent
Agent : 感知环境,采取行动,完成目标。(RL中的Agent)
多模态大模型将这个任务扩展到现实场景的应用上。变成具身Agent。
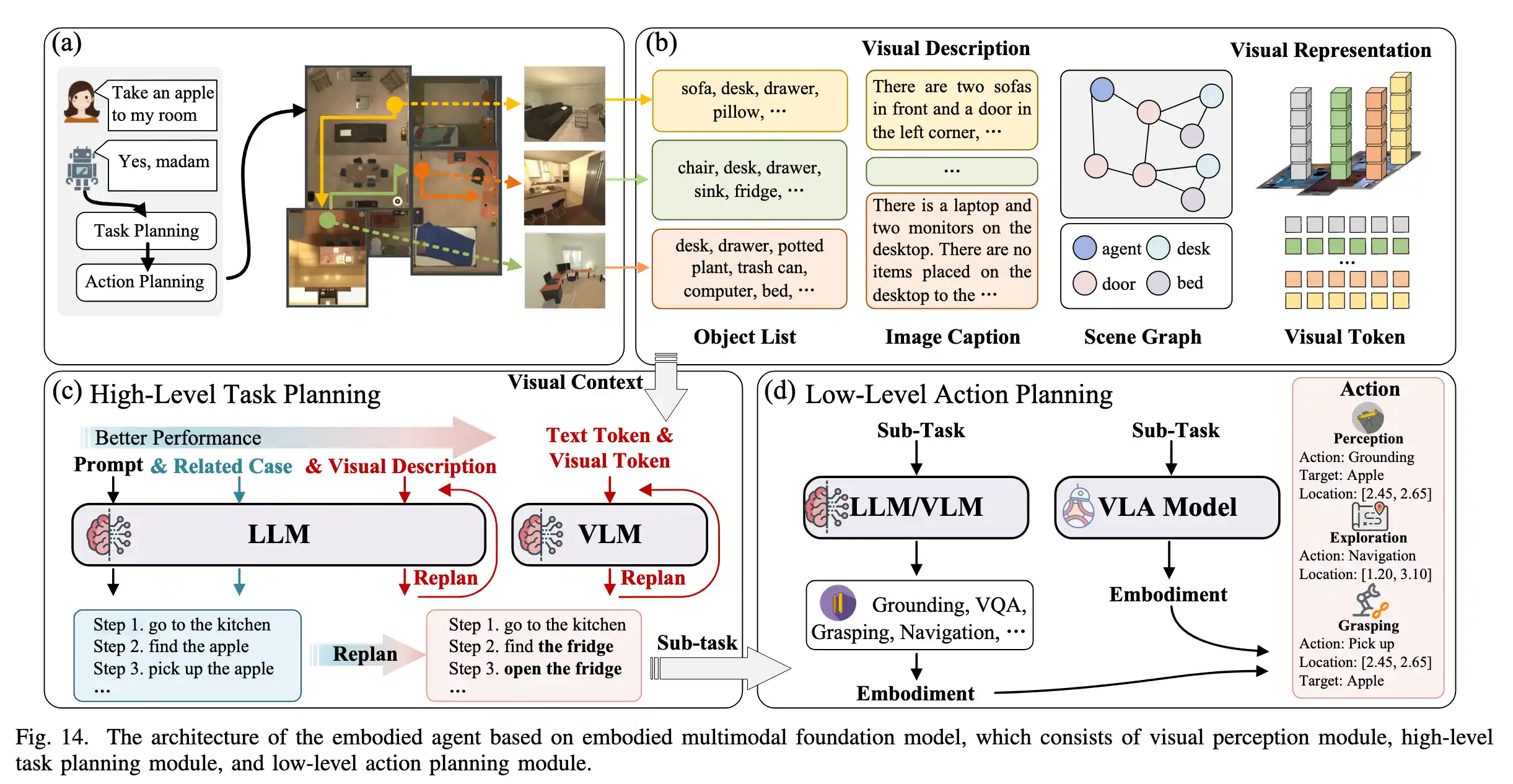
具身Agent一般具有强大的多模态感知、交互、规划能力。在多模态Embodied Agent在完成任务时,一般:
- 将复杂任务分解为sub task
- 有效利用具身感知和交互模型完成这些子任务
任务的规划不仅在行动之前,在行动开始之后,与环境产生交互中也需要将信息反馈给Planer调整规划。
具身Agent的研究方向有下面几个:多模态具身Agent、具身任务规划、具身行动规划
多模态具身Agent模型 Embodied Multimodal Foundation Model
具身智能体需要通过视觉识别环境、通过听觉理解指令,并对自身状态具备清晰的感知,以便执行复杂的交互与操作。为此,需要一个整合多模态感知与自然语言处理能力的模型来增强智能体的理解和决策能力,即“多模态具身基础模型”应运而生。
近期,Google DeepMind研究发现,利用基础模型及大规模多样化数据集是最佳策略。他们基于“机器人Transformer”(RT)开发了一系列工作,为具身智能体的未来研究提供了重要参考。
模型进展
在基础机器人模型的发展上,已经从最早的SayCan模型进化为RT系列:
• SayCan模型:采用了三个独立模型,分别用于计划、可行性判断和低级策略。
• Q-Transformer:统一了可行性判断与低级策略,
• PaLM-E:整合了计划与可行性判断。
• RT-2:在此基础上进一步进展,将计划、可行性和低级策略整合为单一模型,使得各个部分之间的正向传递和协同放大成为可能。
RT-2引入了“视觉-语言-行动”(VLA)模型,具备“连贯思维”推理能力,能够在多个步骤中进行语义推理,例如在不同语境下选择替代工具或饮料。随后,RT-H(RT Hierarchy)通过层次化的动作规划实现了端到端的机器人变换模型,能够在更细粒度上对任务规划进行推理。
数据集与模型开放
为了应对具身模型的泛化问题,Google与33家学术机构合作,创建了包含22种不同数据类型的综合Open X-Embodiment数据集,并基于该数据集训练了通用大型模型RT-X。Open X-Embodiment推动了更多开源视觉语言模型(VLM)的应用,例如基于LLaVA的EmbodiedGPT和基于Flamingo的RoboFlamingo。尽管Open X-Embodiment提供了大量数据集,构建数据集仍然是具身机器人平台快速演进中的一大挑战。AutoRT为此创建了一个系统,能在新环境中部署机器人以收集训练数据,借助LLM提升学习能力,通过更全面和多样的数据来扩展学习。
性能和效率优化
具身模型中基于Transformer的架构需要处理大量上下文数据,包括视觉、语言和具身状态等信息,以及当前任务的记忆,因而在效率上存在一定问题。例如,RT-2的推理频率仅为1-3Hz。为解决这一问题,研究者尝试通过量化和蒸馏模型来提升效率,同时改进模型框架是另一种可行方案。SARA-RT采用了更高效的线性注意力,而RoboMamba则利用了适合长序列任务的mamba架构,推理速度比现有机器人多模态模型快七倍。
高层次任务规划与低层次行动执行的协作
基于生成模型的RT在高层任务理解与规划方面表现出色,但在低层次行动规划上有所限制。为此,Google提出了RT-Trajectory,通过自动添加机器人的轨迹,提供低层视觉线索以学习机器人控制策略。在RT-2的基础上,RT-H引入了分层的动作框架,通过中间的语言动作将高层任务描述与低层机器人运动关联起来。
尽管VLA模型在高层次规划和可行性任务上展示了能力,但在低层物理交互中表现出新技能的能力较弱,且受限于数据集中技能类别,导致执行操作时动作不够灵活。未来的研究应当将强化学习引入大型模型的训练框架,以提升模型在真实环境中的低层物理交互策略学习与优化能力,从而使其更灵活、精确地执行多样化的物理动作。
具身任务规划 Embodied Task Planning
在具身任务规划中,如“将苹果放在盘子上”这类任务通常会被分解为若干子任务,例如“找到苹果,拾起苹果”,“找到盘子”,“放下苹果”。找到物体(导航任务)或拾取/放下操作(抓取任务)并不在任务规划的范围内,这些动作通常在模拟器中被预定义,或在真实世界中使用预训练策略模型执行,例如使用CLIPort完成抓取任务。传统的具身任务规划方法通常基于显式规则和逻辑推理,例如使用符号规划算法(如STRIPS和PDDL)或搜索算法(如MCTS和A*)生成计划。然而,这些方法依赖于预定义规则、约束和启发式信息,难以适应环境中的动态变化或不可预见的情况。
1)基于LLM的规划方法:利用大规模语言模型的生成能力
在自然语言模型扩展之前,任务规划通常通过在具身指令数据集上训练模型实现。例如FILM利用BERT在Alfred和Alfworld数据集上实现了此功能。然而,这种方法受到训练集示例的限制,难以有效对应物理世界的实际情况。随着LLM具备的突现能力,现在可以利用其内在的世界知识和连贯思维推理,将抽象任务分解为多个步骤并合理规划。例如,Translated LM和Inner Monologue可以在不额外训练的情况下,将复杂任务分解为可管理的步骤,并利用其内部逻辑和知识体系生成解决方案。ReAd则作为多智能体协作框架,通过不同提示实现高效的计划自我优化。
此外,部分方法将过去成功的例子抽象为记忆库中的技能,在推理过程中参考这些技能以提高任务规划成功率。一些研究还通过代码而非自然语言进行推理,使任务规划以代码的形式基于可用的API库生成。此外,多轮推理也可以有效地纠正计划中的潜在错误,这是许多基于LLM的智能体研究的重点。例如Socratic Models和Socratic Planner使用提问法来推导可靠的计划。
在任务规划过程中,由于任务复杂性或真实环境的动态性,潜在的失败可能发生。通常情况下,这种失败源于规划器未能全面考虑实际场景中的细节。由于缺乏视觉信息,规划出的子任务可能与实际情境不符,导致任务失败。因此,在规划或执行过程中整合视觉信息是必要的,这可以显著提升任务规划的准确性和可行性,更好地应对真实环境中的挑战。
2)利用具身感知模型的视觉信息进行规划
基于以上讨论,将视觉信息进一步融入任务规划(或重新规划)显得尤为重要。在此过程中,视觉输入提供的对象标签、位置或描述可以为LLM分解任务和执行任务提供关键参考。通过视觉信息,LLM可以更准确地识别当前环境中的目标对象和障碍物,从而优化任务步骤或调整子任务目标。一些研究使用对象检测器在任务执行过程中查询环境中存在的对象,并将这些信息反馈给LLM,以修正当前计划中的不合理步骤。例如,RoboGPT考虑同一任务中类似对象的不同命名,从而提高重新规划的合理性。
然而,标签提供的信息仍然有限,是否可以提供更全面的场景信息?SayPlan提出使用分层3D场景图表示环境,有效缓解了在多楼层和多房间大型环境中的任务规划挑战。ConceptGraphs同样采用3D场景图向LLM提供环境信息,与SayPlan相比,它还具备开放世界的对象检测功能,且任务规划以代码格式呈现,更高效并更符合复杂任务需求。
尽管提供视觉提示,LLM仍可能难以捕捉环境的复杂性和动态变化,导致理解错误和任务失败。例如,如果毛巾锁在浴室柜里,智能体可能会不断在浴室中搜索,而未考虑这一可能性。为了解决这一问题,需要开发更鲁棒的算法以整合多种感官数据,增强智能体对环境的理解。此外,即使视觉信息有限,历史数据和上下文推理也可帮助智能体做出合理的判断和决策。这种多模态整合和基于上下文的推理方法不仅能提高任务执行成功率,还为具身人工智能的进步提供了新视角。
3)利用视觉语言模型(VLMs)进行规划
与通过外部视觉模型将环境信息转化为文本描述不同,视觉语言模型(VLMs)可以在潜在空间中捕捉视觉细节,尤其是难以用对象标签表示的上下文信息。VLMs能够辨识视觉现象背后的规则,例如即使环境中没有看到毛巾,也可以推测毛巾可能被放在柜子里。这一过程展示了抽象视觉特征与结构化文本特征如何在潜在空间中更有效地对齐。
在EmbodiedGPT中,Embodied-Former模块将具身信息、视觉信息和文本信息对齐,有效地在任务规划中考虑智能体的状态和环境信息。与直接使用第三人称视角图像的EmbodiedGPT不同,LEO将2D自我视角图像和3D场景编码为视觉tokens,从而能够更全面地感知3D世界信息并执行任务。类似地,EIF-Unknow模型利用从体素特征提取的语义特征图作为视觉tokens,与文本tokens一同输入到经过训练的LLaVA模型中进行任务规划。
此外,具身多模态基础模型或VLA模型在RT系列、PaLM-E和Matcha等研究中通过大量数据集进行训练,实现了具身场景中视觉和文本特征的对齐。然而,任务规划只是智能体完成指令任务的第一步,后续的动作规划决定了任务能否真正完成。
在RoboGPT的实验中,任务规划的准确率达到了96%,但整体任务完成率仅为60%,受限于低级规划器的性能。因此,具身智能体能否从“想象任务如何完成”的网络空间过渡到“与环境互动并完成任务”的物理世界,关键在于有效的动作规划。
具身动作规划 Embodied Action Planning
在任务规划与动作规划的定义和区别中可以看到,动作规划必须应对现实世界的不确定性,因为任务规划所提供的子任务的粒度不足以指导智能体与环境交互。通常,智能体可以通过以下两种方式实现动作规划:
- 使用预训练的具身感知和具身干预模型作为工具,通过API逐步完成任务规划指定的子任务;
- 利用VLA模型的内在能力来推导动作规划。
此外,动作规划的执行结果会反馈给任务规划器,以调整和改进任务规划。
1)利用API进行动作规划
典型的方法是将各种训练良好的策略模型的定义和描述作为上下文提供给LLMs,使其理解这些工具并确定何时以及如何调用它们来执行特定任务。此外,通过生成代码,可以将更细化的工具抽象为一个函数库进行调用,而不是直接将子任务的参数传递给导航和抓取模型。面对环境的不确定性,Reflexion可以在执行过程中进一步调整这些工具,以实现更好的泛化效果。
优化这些工具可以增强智能体的稳健性,同时可能需要新的工具来完成未知任务。DEPS在零样本学习的前提下,为LLMs赋予各种角色设置,使其在与环境交互时学习多样技能。在后续交互中,LLMs可以学会选择和组合这些技能,以开发出新的技能。这种分层规划范式使智能体能够专注于高级任务规划和决策,而将具体的动作执行委托给策略模型,从而简化了开发过程。
任务规划器与动作规划器的模块化设计实现了独立开发、测试和优化,提升了系统的灵活性和可维护性。这一方法使智能体能够通过调用不同的动作规划器适应各种任务和环境,便于修改,而无需大幅调整智能体的结构。然而,调用外部策略模型可能引入延迟,影响响应时间和效率,特别是在实时任务中。智能体的表现严重依赖于策略模型的质量,如果策略模型效果不佳,整体表现也会受到影响。
2)利用VLA模型进行动作规划
与传统方法不同,VLA模型在同一系统内实现任务规划和动作执行,减少了通信延迟,提高了系统响应速度和效率。在VLA模型中,感知、决策和执行模块的紧密整合使系统能够更高效地处理复杂任务,并适应动态环境的变化。这种整合还便于实时反馈,使智能体能够自主调整策略,从而增强任务执行的鲁棒性和适应性。
然而,这一模式显然更加复杂且成本较高,特别是在处理复杂或长期任务时。此外,关键问题在于,缺乏具身世界模型的动作规划器,仅依靠LLM的内部知识难以模拟物理规律。这一限制阻碍了智能体在物理世界中准确高效地完成任务,难以实现从网络空间向物理世界的无缝迁移。
模拟到现实中的迁移 Sim-to-Real Adaptation
在具身AI中,Sim-to-Real适应指的是将智能体在模拟环境中(网络空间)学习的能力或行为迁移到真实世界场景(物理世界)的过程。其目的是验证并提升在模拟环境中开发的算法、模型和控制策略在真实环境中的稳健性和可靠性。为了实现Sim-to-Real适应,需要具身世界模型、数据收集与训练方法、以及具身控制算法这三大关键要素。
具身世界模型 Embodied World Model
Sim-to-Real适应的关键之一在于创建尽可能接近真实世界的模拟环境模型,使算法在迁移时能够更好地泛化。世界模型旨在构建一个从感知到动作的端到端模型,或通过预测方式从输入到输出的映射关系。与VLA模型不同,VLA模型首先在大规模互联网数据集上训练以获得高层次的能力,再通过真实世界数据进行微调。而世界模型从零开始基于物理世界数据进行训练,随着数据量增加逐步积累高层能力,更类似人类神经反射系统,更适合在输入输出结构化的场景中使用,如自动驾驶(输入:视觉,输出:油门、刹车、方向盘)或对象分类任务。
学习世界模型为物理仿真领域带来了重大进展。与传统仿真方法相比,世界模型能够在信息不完全的情况下进行推理、满足实时计算需求,并随着时间提高预测精度。这种预测能力让机器人逐步发展出物理直觉,以便在现实世界中更好地运行。根据不同的学习流程,世界模型分为生成型方法、预测型方法和知识驱动型方法,具体方法详见表XI。
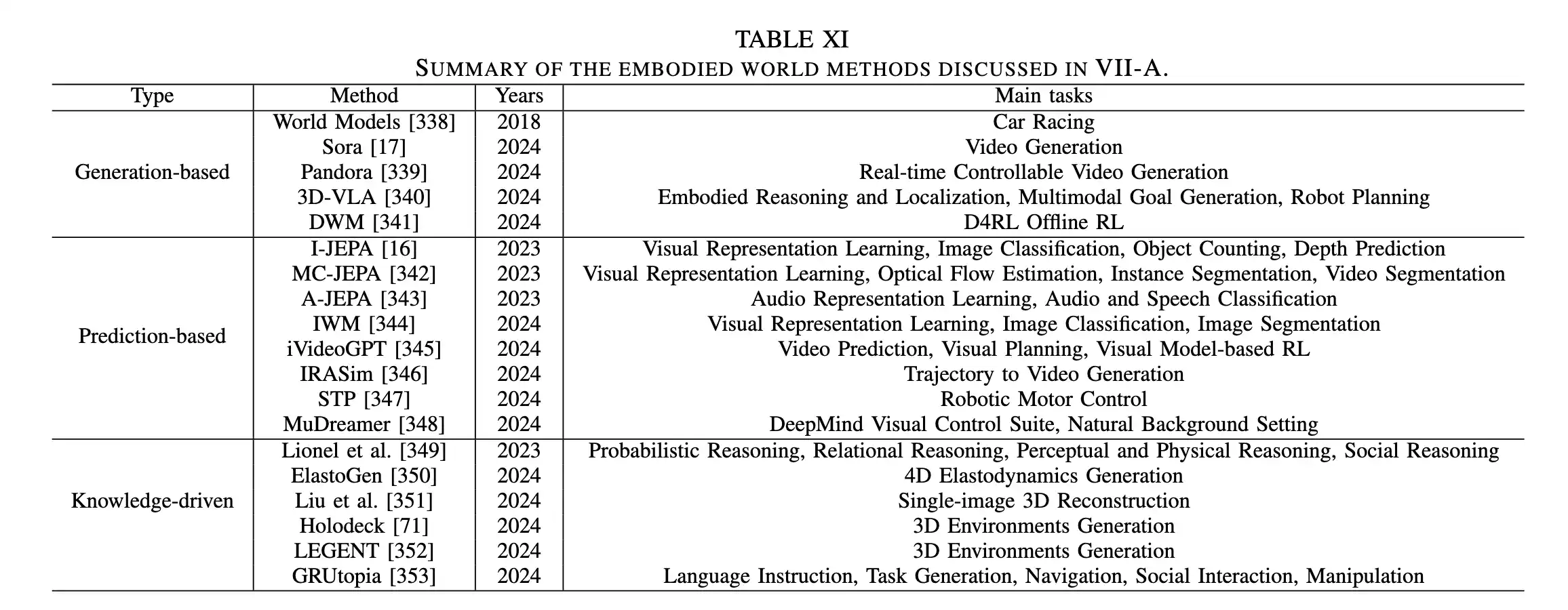
1)生成型方法 Generation-based Methods
随着模型和数据规模的不断扩大,生成型模型已展现出理解和生成符合物理规律的图像(如World Models)、视频(如Sora、Pandora)、点云(如3D-VLA)等数据的能力。这表明生成型模型不仅能捕捉数据的统计特性,还能通过内在结构和机制模拟现实世界的物理与因果关系。由于其内嵌的世界知识,生成型模型不仅仅是识别工具,还具备一定的世界模型特征,这种特性可以用于提升其他模型的表现。通过挖掘生成模型中的世界知识,可以增强模型的泛化性与鲁棒性,使其更适应新环境,提高对未知数据的预测精度。
然而,生成型模型也存在一些限制。当数据分布显著偏斜或训练数据不足时,生成模型可能产生不准确或扭曲的输出。其训练过程通常需要大量计算资源和时间,且缺乏解释性,使其在实际应用中面临挑战。当前的研究致力于提升生成模型的效率、增强解释性,并处理数据偏差等问题。随着研究的不断深入,生成模型在未来应用中有望展现更大的潜力和价值。
2)预测型方法 Prediction-based Methods
预测型世界模型通过构建内部表示来预测和理解环境,基于提供的条件重构潜在空间中的特征,从而捕捉更深层次的语义与世界知识。这种模型将输入映射到潜在空间中,通过该空间提取并利用高层语义信息,使机器人能更准确地进行具身下游任务(如iVideoGPT、IRASim、STP、MuDreamer)。相比像素级信息,潜在特征可以抽象化并解耦不同类型知识,使模型在处理复杂任务和场景时表现更好,提升了泛化能力。
在时空建模中,世界模型需要根据对象的当前状态和交互方式预测其后续状态,并将此信息与内在知识结合。具身世界模型通过整合感知信息与先验知识,对环境进行动态预测。这一方法不仅依赖于感知数据,还依靠世界知识来推断环境变化,从而生成更准确的时空预测。与像素级处理相比,基于潜在空间的操作能以较低成本保持不同环境中的高性能。然而,模型在处理未见过的环境和情况时可能表现出一定的局限性和不稳定性,且解耦的世界知识在潜在空间中可能存在解释性问题。
3)知识驱动型方法 Knowledge-driven Methods
知识驱动型世界模型通过人工构建的知识注入模型,使其具备世界知识。在真实-仿真-真实(real2sim2real)方法中,利用现实世界的知识来构建符合物理规律的模拟器,对机器人进行训练,从而提高模型的鲁棒性和泛化能力。此外,人工构建的常识或符合物理的知识也常用于生成模型或模拟器,例如ElastoGen、One-2-3-45和PLoT等。这种方法在模型中加入物理约束,提升了生成任务的准确性和解释性。这些物理约束确保模型知识的准确性和一致性,减少训练和应用中的不确定性。
一些方法将人工创建的物理规则与LLMs或MLMs结合,利用其常识能力生成多样化且语义丰富的场景。例如,Holodeck、LEGENT和GRUtopia通过自动优化空间布局实现丰富的场景生成,为具身智能体提供多样化的环境,从而促进通用具身智能体的发展。
数据收集与训练 Data Collection and Training
在Sim-to-Real适应中,高质量数据至关重要。传统的数据收集方法往往依赖昂贵的设备和精确操作,过程耗时且劳动密集,且灵活性不足。近期,已经提出了多种高效且低成本的数据收集和训练方法,用于高质量的示例数据收集。以下总结了在现实和模拟环境中进行数据收集的多种方法(见图16中的示例数据)。
1)现实世界数据 Real-World Data
在大量、丰富的数据集上训练高容量模型已展现出强大的能力,并在下游应用中取得了显著成功。例如,LLMs如ChatGPT、GPT-4和LLaMA在自然语言处理领域表现出色,并在下游任务中提供了强大的问题解决能力。类似地,是否可以在机器人领域训练一个具身大模型,使其具备较强的泛化能力并能适应新的场景和机器人任务?实现这一目标需要大量具身数据集为模型提供训练数据。
例如,Open X-Embodiment是一个具身数据集,来源于22种不同的机器人,包含527种技能和160,266个任务。收集的数据是机器人执行操作过程中的真实示例数据,主要关注家庭和厨房场景,涉及家具、食物和餐具等物品,操作以拾取和放置任务为主,部分任务涉及更复杂的操作。在该数据集上训练的高容量模型RT-X表现出优异的迁移能力。
此外,UMI提出了一个数据收集与策略学习框架,设计了一款便携式手持夹持器和简洁界面,以实现便携、低成本和信息丰富的数据收集,尤其适用于双手和动态操作示例的数据收集。通过简单地修改训练数据,机器人可以实现零样本的双手精准任务的泛化能力。
另一个低成本的全身移动操作系统Mobile ALOHA,用于在全身移动条件下收集双手操作的数据,如煎虾和上菜等任务。通过该系统和静态ALOHA收集的数据训练智能体,可显著提升移动操作任务的表现,这类智能体可以用于家庭助手或工作助手。此外,人类-智能体协作数据收集中,人类和智能体在数据收集时共同学习,减少人类工作量,加速数据采集并提高数据质量。在具身场景中,收集数据时由人类提供初始动作输入,随后智能体通过迭代扰动和去噪过程优化这些动作,从而生成高质量的操作示例。
2)模拟数据 Simulated Data
现实世界的数据收集方法常需大量人力、物力和时间,因此大多数情况下,研究者可以选择在模拟环境中收集数据集以进行模型训练。模拟环境中的数据收集不需要大量资源,且通常可以通过程序自动化,节省大量时间。例如,CLIPORT和Transporter Networks使用Pybullet模拟器收集示例数据进行端到端网络模型训练,成功将模型从模拟迁移到现实。GAPartNet构建了一个大规模的以部件为中心的交互数据集,提供丰富的部件级别标注,用于感知和交互任务。SemGrasp创建了一个大规模的抓取文本对齐数据集CapGrasp,用于虚拟环境中的灵巧抓取任务。
3)Sim-to-Real迁移范式 Sim-to-Real Paradigms
近期,多个Sim-to-Real迁移范式被提出,通过在模拟环境中进行大量学习,再将其迁移到现实中,以减少昂贵的现实示例数据需求。以下列出五种Sim-to-Real迁移范式:
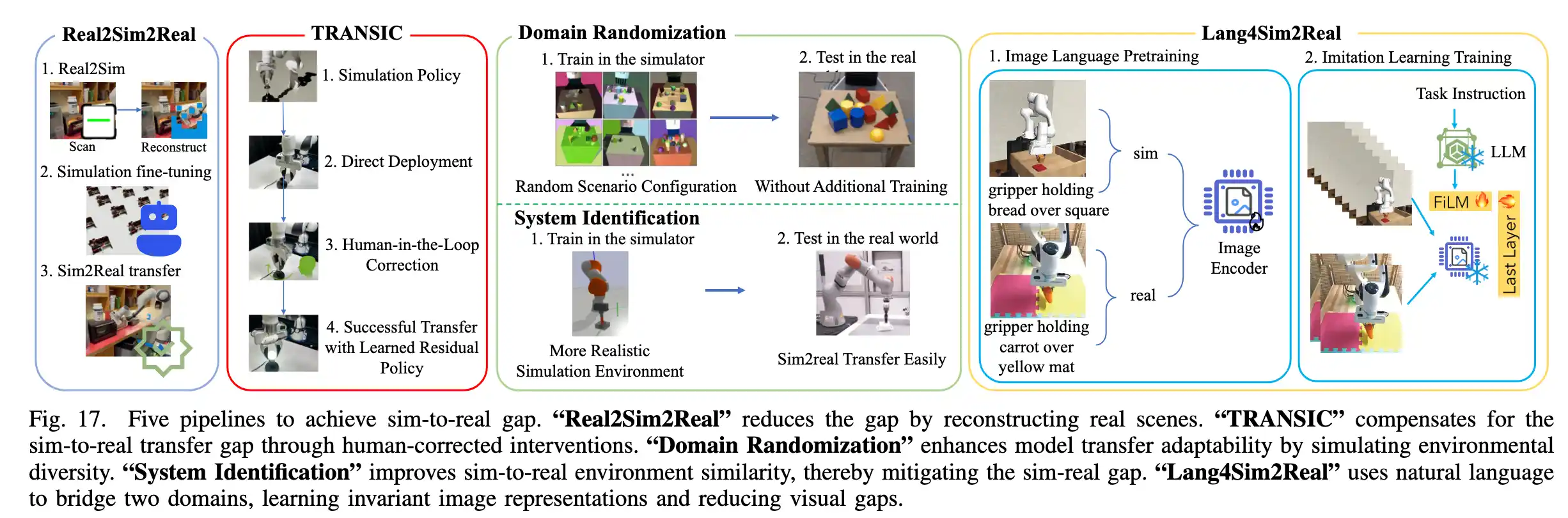
• Real2Sim2Real:利用强化学习(RL)在“数字孪生”仿真环境中增强模仿学习。首先使用NeRF和VR对场景进行扫描和重建,将构建的场景导入模拟器以实现从真实到仿真的精度,接着在模拟中对专家示例策略进行细化,最后将策略迁移到现实环境中执行。
• TRANSIC:通过实时人类干预矫正机器人在现实场景中的行为,以缩小Sim-to-Real差距。首先,机器人在模拟中通过RL建立基础策略,随后将这些策略应用于真实机器人,错误时由人类通过远程控制实时纠正行为。干预数据用于训练残差策略,整合基础和残差策略以确保真实应用中的顺畅轨迹。
• 域随机化 Domain Randomization:在模拟训练期间通过参数随机化来增强模型的泛化能力。在仿真中通过随机化参数覆盖多种条件,提高了模型的鲁棒性,使其能够从模拟环境部署到现实环境。
• 系统辨识 System Identification:通过构建现实环境中物理场景的精确数学模型,涵盖动力学和视觉渲染等参数,使模拟环境更接近现实场景,从而促进从模拟到现实的顺利迁移。
• Lang4sim2real:使用自然语言作为桥梁,以图像的文本描述作为跨域统一信号。先用带有跨域语言描述的图像数据预训练编码器,再使用域不变表示进行多任务语言条件行为克隆策略的训练。该方法通过模拟数据中的丰富信息弥补了现实数据的不足,增强了Sim-to-Real迁移能力。
具身控制 Embodied Control
具身控制通过与环境的交互学习并使用奖励机制优化行为,以获得最优策略,从而避免传统物理建模方法的局限性。具身控制方法主要分为两类:
1)深度强化学习(DRL)
深度强化学习(DRL)可以处理高维数据并学习复杂行为模式,适合用于决策与控制任务。例如,混合动态策略梯度(HDPG)被应用于双足机器人行走控制,使得控制策略可以根据多个标准动态优化。另一个例子DeepGait,是一种针对地形的步态控制网络,结合了基于模型的运动规划和强化学习方法。它包括一个地形感知规划器,用于生成步态序列和基座运动,以指导机器人朝向目标方向前进。还包含一个步态与基座控制器,用于在执行这些序列时保持平衡。规划器和控制器都通过神经网络参数化,并通过深度强化学习算法优化。
2)模仿学习(Imitation Learning)
深度强化学习的一个主要缺点是需要大量数据进行多次尝试。为了解决这个问题,模仿学习通过高质量的示例数据来减少数据使用。为提高数据效率,提出了离线RL + 在线RL的组合方法,旨在降低交互成本并确保安全性。首先,离线RL从静态的、预收集的大数据集中学习策略,随后将这些策略部署到真实环境中,进行实时交互和探索,并根据反馈进行调整。代表性的模仿学习方法有ALOHA和Mobile ALOHA,这两种方法均通过人类示例提升了数据效率。
尽管具身AI涵盖了高层次的算法、模型和规划模块,其最基础的组成部分仍然是具身控制。因此,如何控制物理实体并赋予其“物理智能”成为关键问题。具身控制直接涉及硬件,如控制关节运动、末端执行器位置以及行走速度。例如,对于机械臂,了解末端执行器的位置后,如何规划关节的运动以到达目标位置?对于类人机器人,如何在掌握运动模式的前提下控制关节以达到预期姿势?这些都是控制领域需要解决的关键问题。
具身控制的其他应用
一些研究工作专注于机器人控制以提升动作的灵活性。例如,一种基于视觉的全身控制框架连接了机器人手臂和机器人狗,利用12个腿部关节、6个手臂关节和1个夹持器,通过追踪机器狗的速度和手臂末端执行器的位置实现更灵活的控制。此外,一些研究利用传统方法控制双足机器人行走,诸如MIT的Cheetah 3、ANYmal和Atlas等机器人,配备稳健的行走控制器,可执行跳跃和跨越障碍等敏捷运动任务。
另外,其他研究聚焦于类人机器人控制,使其可以模仿人类动作和行为,以适应各种人类行为模拟任务。

具身控制的整合:RL与Sim-to-Real
具身控制将RL与Sim-to-Real技术相结合,通过与环境的交互来优化策略,使机器人能够探索未知领域,甚至超越人类能力,并适应非结构化环境。尽管机器人可以模仿许多人的行为,完成任务仍然需要基于环境反馈的RL训练。最具挑战性的场景是接触密集型任务,这些任务需要实时调整以响应操作对象的状态、变形、材质和受力等反馈信息,这时RL变得不可或缺。
在多模态语言模型(MLMs)的时代,MLMs具备对场景语义的广泛理解,可为RL提供稳健的奖励函数。此外,RL对于大模型的任务对齐也至关重要。未来,在经过预训练和微调之后,RL仍然需要与物理世界对齐,以确保模型在真实环境中的有效部署。
全机器人整合 All Robots in One
尽管已有数据集(如Open X-Embodiment)为预训练具身智能体提供了统一结构,但当前数据级别的限制仍然阻碍着通用型具身智能体的发展,主要问题包括:缺乏标准化格式、多样性不足以及数据量不足。特定任务的数据集无法满足训练通用型智能体的需求。现有数据集在多模态感知方面也不够全面——目前没有任何一个数据集能够同时整合图像、3D视觉、文本、触觉和听觉输入。此外,多机器人数据集中缺乏统一格式,这使得数据处理和加载变得复杂,不同机器人平台之间的控制对象表示不兼容,数据量不足以支撑大规模预训练,缺少结合模拟和现实数据的数据集,难以有效解决模拟到现实的迁移问题。
ARIO标准的提出

为了应对这些挑战,ARIO(All Robots In One)被引入,作为一种新的数据集标准,优化了现有数据集并促进了更通用的具身AI智能体的发展。ARIO标准采用统一格式记录了不同形态机器人之间的控制和运动数据,具有以下主要特性:
-
时间戳机制:通过时间戳标准化数据收集,解决了机器人动作频率和传感器帧率的差异问题。ARIO的统一格式能够适应多种机器人类型的可变数据,确保时间戳的精准性。
-
多样数据集成:ARIO标准支持集成多机器人数据,便于开发高性能、具备良好泛化能力的具身AI模型,为具身AI数据集提供了理想格式。
ARIO大规模数据集的构建
在ARIO标准基础上,开发了一个统一的大规模ARIO数据集,包含约300万个情境,涵盖258个系列和321,064个任务。此数据集的构建方式多样化,包括:
- 现实世界数据收集:通过自定义平台收集了3,662个情境,涵盖了105种以上的任务;
- 基于模拟的数据生成:利用如Habitat、MuJoCo和SeaWave等平台生成数据,涵盖1,198个任务,共收集了703,088个情境;
- 开源数据集的标准转换:将现有的开源数据集转换为ARIO标准,为数据集增加了2,326,438个情境,涉及319,761个任务。
ARIO数据集不仅解决了现有数据集的限制,还通过提供一个连贯的框架支持数据收集和表示,促进了更强大、通用的具身AI智能体的研发。借助ARIO标准的统一格式和多样数据,未来的具身AI智能体将能更灵活地导航和与物理世界互动,适应日益复杂和多样的任务场景。
面对的挑战
1)高质量机器人数据集
获取足够的现实机器人数据仍是重大挑战。收集这些数据不仅耗时且资源密集,单靠模拟数据会加剧模拟到现实的差距问题。构建多样的现实机器人数据集需要机构间的紧密合作。此外,为提高模拟数据质量,需开发更真实且高效的模拟器。当前的RT-1通过机器人图像和自然语言指令的预训练模型在导航和抓取任务中取得了良好效果,但获取现实机器人数据集仍然困难。为了构建跨场景、跨任务的具身通用模型,需构建大规模数据集,结合高质量模拟环境数据辅助现实数据。
2)高效利用人类示例数据
高效利用人类示例数据需要通过人类的行为和动作示例来训练和改进机器人系统,包括收集、处理和学习人类执行的任务。现有的R3M方法使用动作标签和人类示例数据来学习可泛化的表示,但对于复杂任务的效率仍需提升。有效利用非结构化、多标签和多模态的人类示例数据,结合动作标签数据,将提高具身模型在动态环境中的表现和适应能力,使其更好地执行复杂任务。
3)复杂环境认知
复杂环境认知是指具身智能体在物理或虚拟环境中感知、理解和导航复杂现实环境的能力。当前的Say-Can模型基于大规模常识知识,通过预训练LLM模型的任务分解机制来进行简单任务规划,但在理解复杂环境中的长期任务上有所欠缺。为了使机器人系统更具通用性,具身智能体需具备跨场景的知识迁移和泛化能力。这要求构建适应性强且可扩展的具身智能体架构,以处理复杂场景和多样化任务。
4)长期任务执行
对于机器人而言,执行单个指令往往意味着长期任务,例如“清洁厨房”涉及多个低层次行动(如重新排列物体、清扫地板、擦拭桌子等)。成功完成此类任务需要机器人能够规划并执行一系列长时间跨度的行动。当前的高层任务规划器在特定场景中取得了初步成功,但在具身任务中仍显不足。应开发具备强大感知能力和常识知识的高效规划器,以应对复杂的长期任务需求。
5)因果关系发现
现有的数据驱动具身智能体依赖于数据内在的相关性做出决策,无法真正理解知识、行为与环境之间的因果关系。这种模型方式会导致策略偏差,难以在现实环境中以可解释、稳健且可靠的方式运行。因此,具身智能体需具备世界知识,能够自主进行因果推理。通过交互了解世界并利用溯因推理学习其运作规律,可进一步增强多模态具身智能体在复杂环境中的适应性和决策可靠性。
6)持续学习
在机器人应用中,持续学习对于在多样环境中部署机器人学习策略至关重要,但目前仍是一个未充分探索的领域。虽然近期一些研究探讨了持续学习的子主题(如增量学习、快速运动适应和人类在环学习),但这些方案多针对单一任务或平台,尚未应用于基础模型。未来的研究方向包括:
• 在微调最新数据时混合使用不同比例的先前数据分布,以减轻灾难性遗忘;
• 从先前分布中开发高效原型或课程用于任务推理;
• 提高在线学习算法的训练稳定性和样本效率;
• 将大容量模型无缝集成到控制框架中,以实现实时推理,可通过分层学习或慢-快控制实现。
7)统一评估基准
虽然有许多基准可评估低层次控制策略,但它们在评估的技能方面差异较大,且对象和场景往往受限于模拟器的约束。为全面评估具身模型,需要采用包含多种技能的基准,使用真实模拟器进行评估。在高层任务规划器方面,许多基准主要通过问答任务评估规划能力。然而,理想的评估方式是结合高层任务规划器和低层次控制策略来执行长期任务并测量成功率,而不仅依赖于对规划器的孤立评估。这种综合方法提供了对具身AI系统能力的更全面的评估。
 微信
微信 支付宝
支付宝