
轻量推理手记
目前的项目结构
1 | ├── bench.py |
离线推理时候 main函数实例化 LLMEngine 在rank0上init,init时候现在副卡init ModelRunner 然后进入loop 阻塞在 shm的read上。然后在rank0上init ModelRunner 不进入loop。在main中调用
LLMEngine的generate方法 在里面call run函数,call的时候卡0把run写进shm 副卡read读出输出不再阻塞 然后副卡根据shm读出的call什么 也调用call 所有卡一起推理。也就是执行CausalModel的forward得到logits 这时候分成几份在多个卡上,然后最后LMHead将 hiddenstate * 最后的分类头 得到每个token的分数 logits 然后 gather到卡0上。然后交给采样器跟觉策略进行采样。
待实现的功能
- [x] 实现 flash_attention @Triton
compute bound - [x] 实现 paged_attention_v1 @Triton 取所有kv
- [x] 实现 paged_attention_v2 @Triton 对kv做online softmax
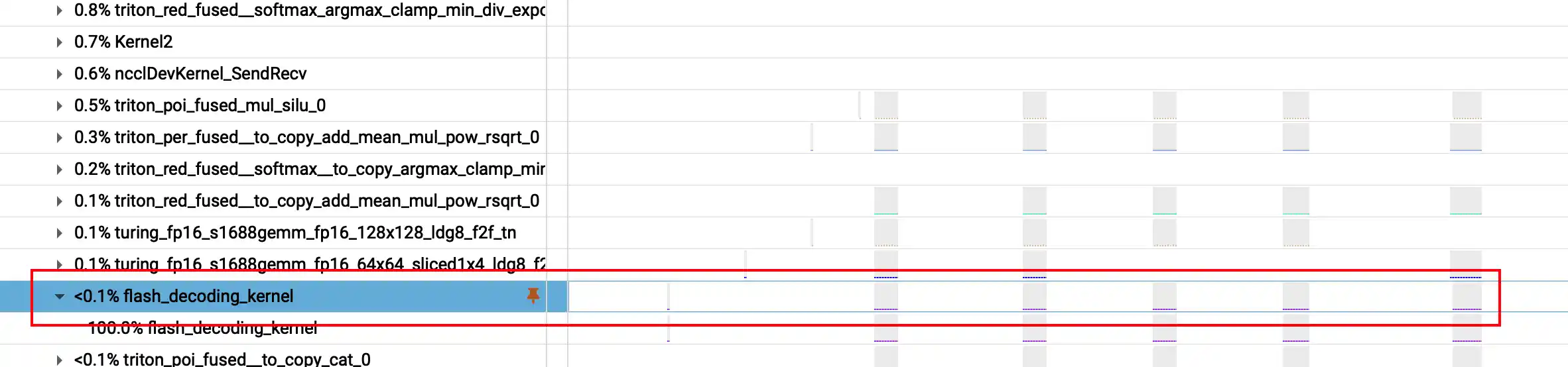
- [x] 实现 flash_decoding @Triton
@Triton 并行计算 m l acc 然后 @Triton reduction 但是要申请空间 最开始按照blockn 64做 OOM了
发现应该是按照split 对seq分块,split num 可以根据 context len 切换?
 reduce 的代价很高
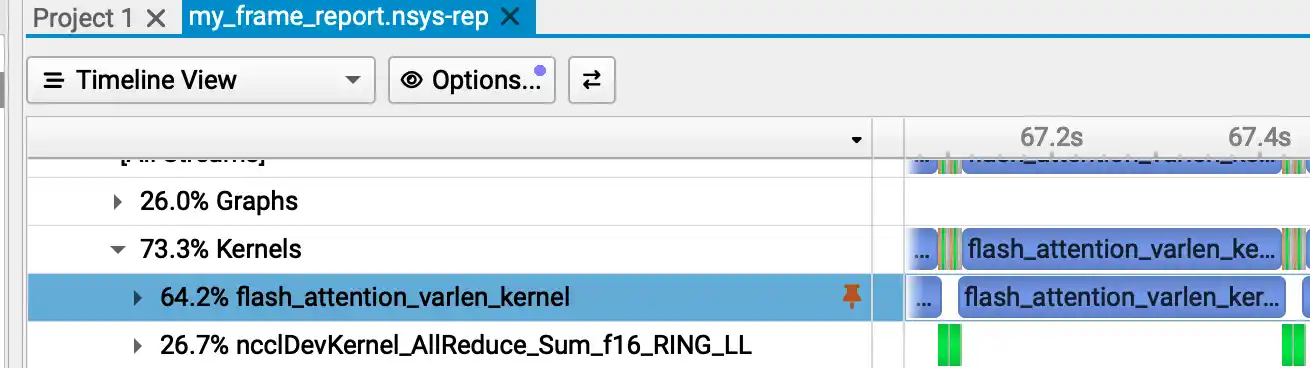
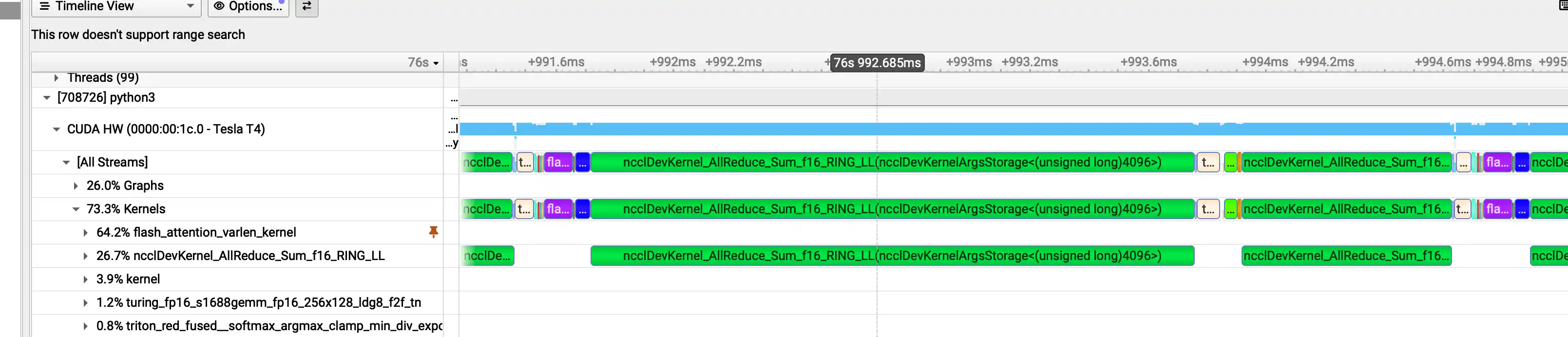
reduce 的代价很高 - [x] Nsight System 分析性能瓶颈
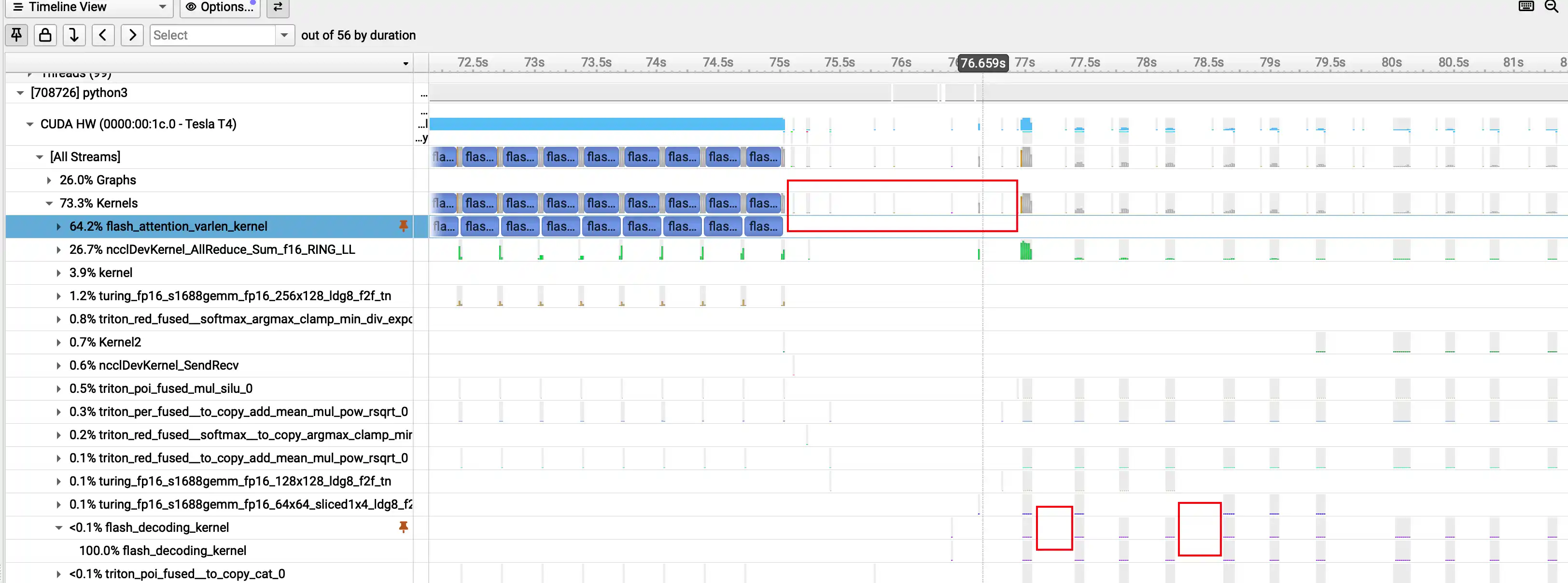
程序调度的代价很高 - [x] 实现 OnlineInfer、 Countinuous Batching
- [x] 实现 KV Cache量化
- [1] 实现 Chunked Prefill ,调度规则 (flash
- [x] RMSLayerNrom @Triton 还有什么用Triton写,分析一下 linear?
- [x] 支持 llama
- [x] CUDAGraph
以后有时间了做
- [ ] KVCache 的卸载 和 Recomputation
- [ ] 实现 KV Cache 异步加载
- [ ] 实现 AWQ 量化支持
- [ ] 实现 投机采样
- [ ] 实现 PD 分离
- [ ] 支持 Deepseek
- [ ] 支持 Qwen3-MoE
- [ ] TP 之后实现 PP
flash_attention
输入是 QKV 计算 O 用 online softmax 更新 QKVO的维度是 seqlen,headnum,headdim
用triton并行的时候分为三个维度:
1. 对输入Q的seqlen按照BLOCKM分块
2. 对 Q 的头分块
在每个program里面的操作维度是 tl.arange(0,head_dim)
然后注意写triton是要 梳理 tensor的shape, 标注清楚 offset ,取两个维度时候注意标注 [None,:]
page_attention
按照 batch_size,head_num 两个维度 并行,并行的时候 对 context 中的 所有 kvcache 块 中的 token 逐个遍历 增量更新 O ,最开始的计算方式是想把所有context 中的kv全部中上下文中拿出来,但是这样设计的显存访问代价过高,所以更改设计方式,把 contextlen 按照 BLOCK_M 进行划分 然后对 BLOCKM中的每个token依次softmax 但是还是很慢。不如直接对BLOCKM中一个kv矩阵并行处理,计算QK 然后增量更新。
最开始是对每个token逐个online softmax 后来分块算
flash_decoding
在 pageAttn 基础上 对每个 decode token 的 context 分split 按 split 并行计算 o 然后最后 reduce
flash_decoding_kernel, flash_decoding_reduce_kernel, flash_decoding 最后集成进一个函数
问题:最开始 设计的时候遇到一个问题,split size 设置成了 64 目的是为了减少 对 L2 cache的访问,但是实现后发现,这样的虽然提高了 qk 计算 m l acc 的并行度,但是由于每个 layer 都要申请一段空间去存放临时结果,运行的时候如果保持 GPU 利用率 会导致 OOM 而且速度几乎没有提升,和预想的结果偏差较大。
分析原因发现,计算的并行度虽然提升了,但是 reduce 的代价会变高很多,因为临时结果有 max_context_len/BLOCK_N 个 reduce时候要依次遍历。而且由于BLOCKN很小,所以每个layer申请的内存空间较大。
解决办法:将 seqlen 按照 预设好的 split 划分成几个部分,然后每个program 处理 一个 split 所有kvcache 。这样做解决了 OOM 和 reduce 代价过大的问题。实现了真正的 flashdecoding。
没命中的 block 直接 把 attention 置为 0 当做无效块处理
遗留的问题 :
- split 是不是可以根据 contextlen 动态调整
- 在调度的时候是不是可以优先调度上下文长度均匀的seq 这样可以避免一些 kernel 在空转?
实现 online infer , Stream Infer
AsyncLLMEngine 是 llm engine 的一个 异步 wrapper
https://github.com/vllm-project/vllm/blob/main/vllm/v1/engine/async_llm.py
https://github.com/vllm-project/vllm/blob/main/vllm/v1/engine/llm_engine.py
为了能异步获取seqdecode出的结果,对Sequence类加一个asyncio.queue,每次step decode出结果就加进来
先实现 (异步生成器函数)streaming generate 输入和 LLMEngine 保持同步,主要逻辑是这样:
1 | 1. seq = await add_request 异步添加请求 简化模型 一个req 一个seq |
之后遍历这个就可以得到流式结果了,对于非流式的generate 其实就是流式的generate 最后把结果join起来。
现在addReq逻辑实则是同步的,虽然写成了一个协程函数 但是不async也可以。addReq会确认模型的运行循环是开着的。
还有需要注意的是,每次addreq时候,需要确认 主事件(engine的step) 还在 这样加入的请求才能被 不断的 schedule。但是现在的schedule策略是 prefill优先,之后可以调整一下。
Continuous Batching 就是 模型 每次step后 都要 调度 主要是为了结束 finish 的 seq(也就是decode完成的 seq)的生命周期,不要占着batch空转
Chunked Prefill 调度规则
vllm中的 scheduler
https://github.com/vllm-project/vllm/blob/main/vllm/v1/core/sched/scheduler.py
1 | # NOTE(woosuk) on the scheduling algorithm: |
无阶段调度不分PD,先塞decode 再塞prefill 与 Chunked Prefill
为什么要chunked prefill? 在没有实现 PD 分离 的情况下,如果来了一个很长的prompt ,prefill的耗时太高,会到时decode请求的latency增大。而且现有的 scheduler 的 结构 是 PD 分阶段完成,导致在decoding时候的计算资源利用率很低。所以将 请求 prefill 的prompt 拆分成chunk 然后 按照 decode优先,然后prefill chunk的顺序塞满 一个 batch。而且如果来了两个 一长一短的prompt 拆分成chunk也会提高短序列TTFT速度。 也可以理解成充分利用decode时候未被充分利用的计算资源
- 先实现了 schedule 的调度策略 调度完一个seq的最后一个chunk 就把它放到running队列了有问题
- blockmanager 中 对 chunk的 allocate
- llmengine 中的 chunkstep 函数
- modelrunner的run函数
- run 调用的 prepare mixed batch函数 因为应用了对话模板 默认 prefill的请求长度不可能是1
- attention的计算不分开 怎么做一个 unified attention ,flashattention with KVcache
- LMHead 对于混合batch 要进行特殊的处理 decode+最后一个chunk的token
对context的组织也很难,还有一个seq传输序列化的时候忘记往getstate里面写status属性了
先把两种请求留在一个batch里面但是分开做 attention 吧,分成两种Attn和合成一种有什么区别?
先分开做的:prefill的部分用flashAttnwithKVCache 然后 decode的部分用 flashdecoding
这两个block manager 很不一样 chunkedprefill因为在 prefill 的时候要用到cache 所以 seq的num cached tokens 要在post process里面更新。
这个和PD 分阶段计算的时候blockmanager分配的策略不一样,分阶段的时候,是在allocate直接就给seq的numcachedtoken加好,但是用了chunkedprefill的话会导致,inputids直接变成0
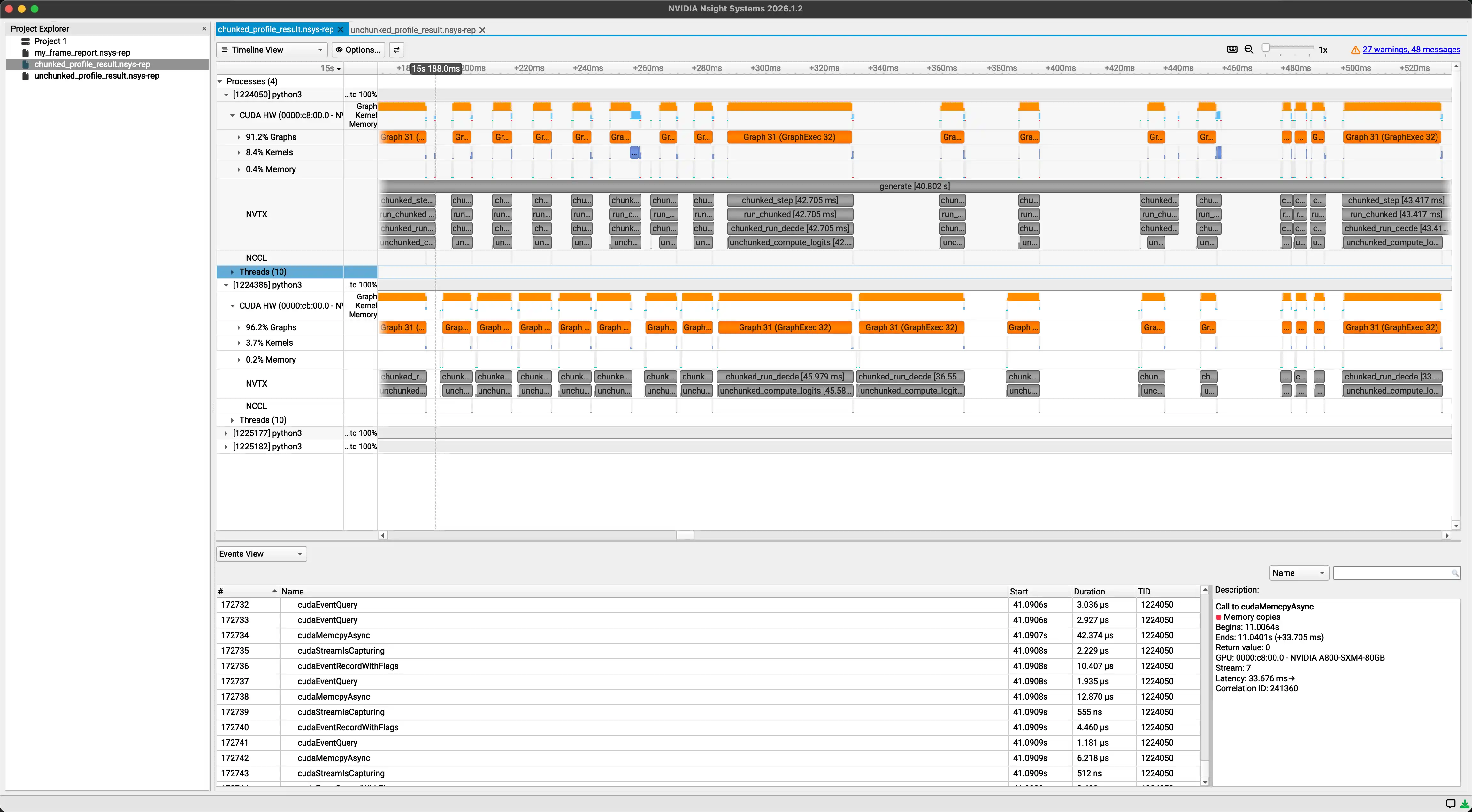
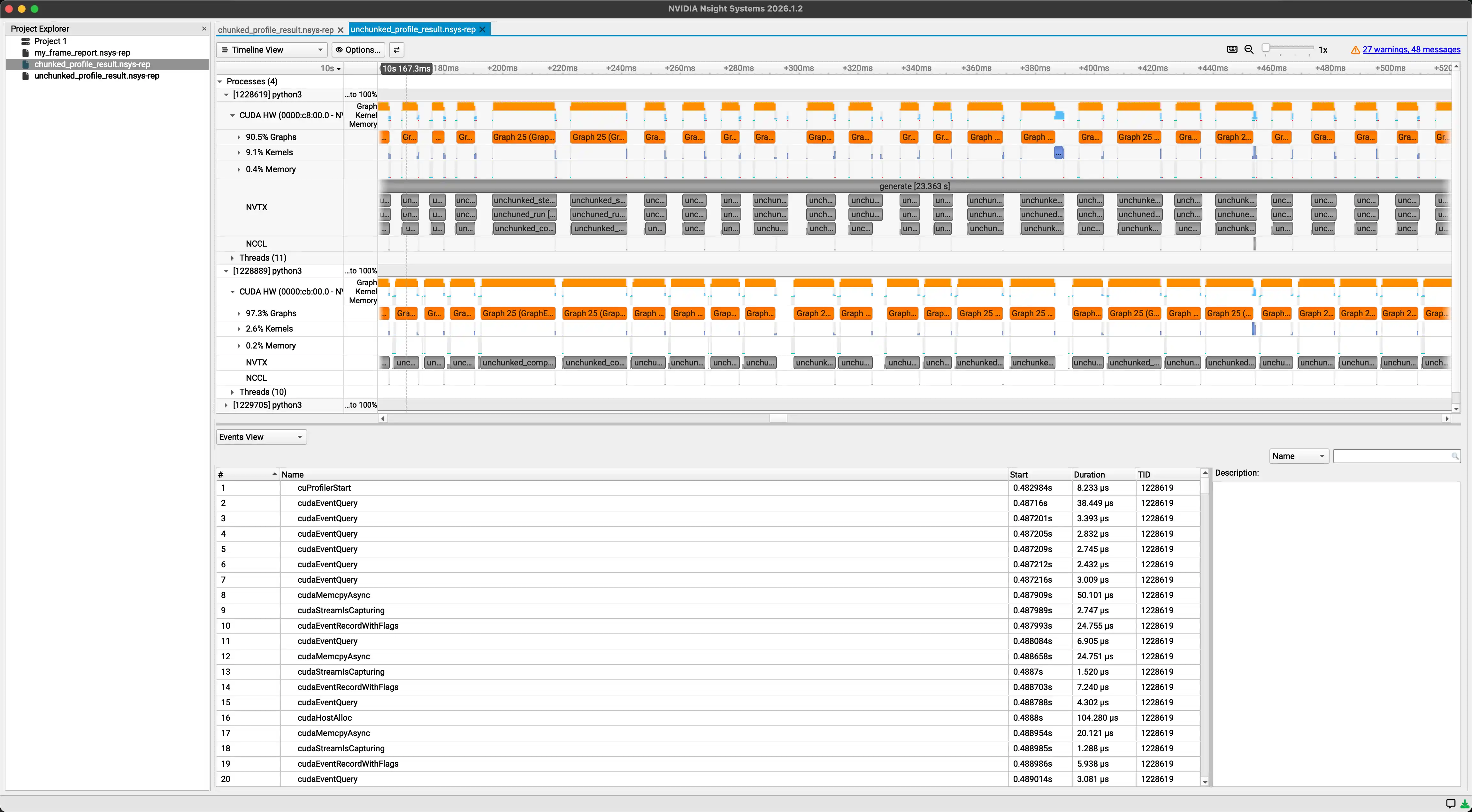
cpu调度代价太高
KVCache量化 int 8
在前向时候 把每个kv 量化存入cache int8 : -127 127
vec / max(|vec|) * 127 这个量化方法就是把原本的数放缩到 int8 的全部空间,然后记录scale 就是 max值
最开始将全部kvcache进行反量化,但是发现可能会OOM 而且计算速度特别慢 增大了memoryAccess的负担。所以将反量化的过程融合进 flashdecoding内,尽可能的保证了速度。
这个在做的时候 发现,一开始是全量 dequant出来,既不省内存 而且非常耗时。所以改成在flashdecoding时候再dequant出来
RMSnorm 用triton实现
原本使用torch.compile 然后自己实现triton的时候
x = x + residual 按行分块做 把x给view 最后总吞吐反而下降了,分析之后发现,x+res访存太耗时了,
所以 应该写融合算子 读 add 写 res的操作都在里面实现。
但是现在并行度是整个 输入的第一个维度(view(-1,x.shape[-1]))如果尝试分块会不会效果更好?
对输入向量的最后一个维度。但是并行度有点高,kernel launch overhead 会不会有点高? 解决这个可以靠 融合算子,cudaGraph等烧录
支持llama
gate_up_proj 等有几个要在 modelforCausalLLM里面写进一个字典里。否则load会出错
Attention里面的头数是一个卡的头数!!!!!!!!!发现单卡没问题 多卡报错
basemodel就是纯自回归补全 instructmodel 才应该应用对话模板
Thinking
Decode 时候因为要访问全部的上下文 所以Decode的时间复杂度应该是On,但是有以下面对办法:
- Sliding Window Attention 只看最近W个token前面的扔了
- KV Compression / Pooling 把前面的多个kv 进行压缩
- Sparse Attention 稀疏注意力 只关注部分token
- Linear Attention(核方法)、Retrieval / Memory 模型
为什么用triton \ CUDA 而不是torck的张量广播?
Triton 能精准控制 GPU 硬件层级的内存访问和计算调度,把注意力计算的核心逻辑「塞进 L1/L2 Cache」完成,彻底降低对高延迟 HBM(显存)的访问;而 PyTorch 张量广播的并行是「逻辑层」的,无法精细控制硬件缓存,最终仍会导致大量低效的 HBM 访问。
 微信
微信 支付宝
支付宝