
计算机高级系统结构
第一章 量化设计与分析基础
计算机分类类别

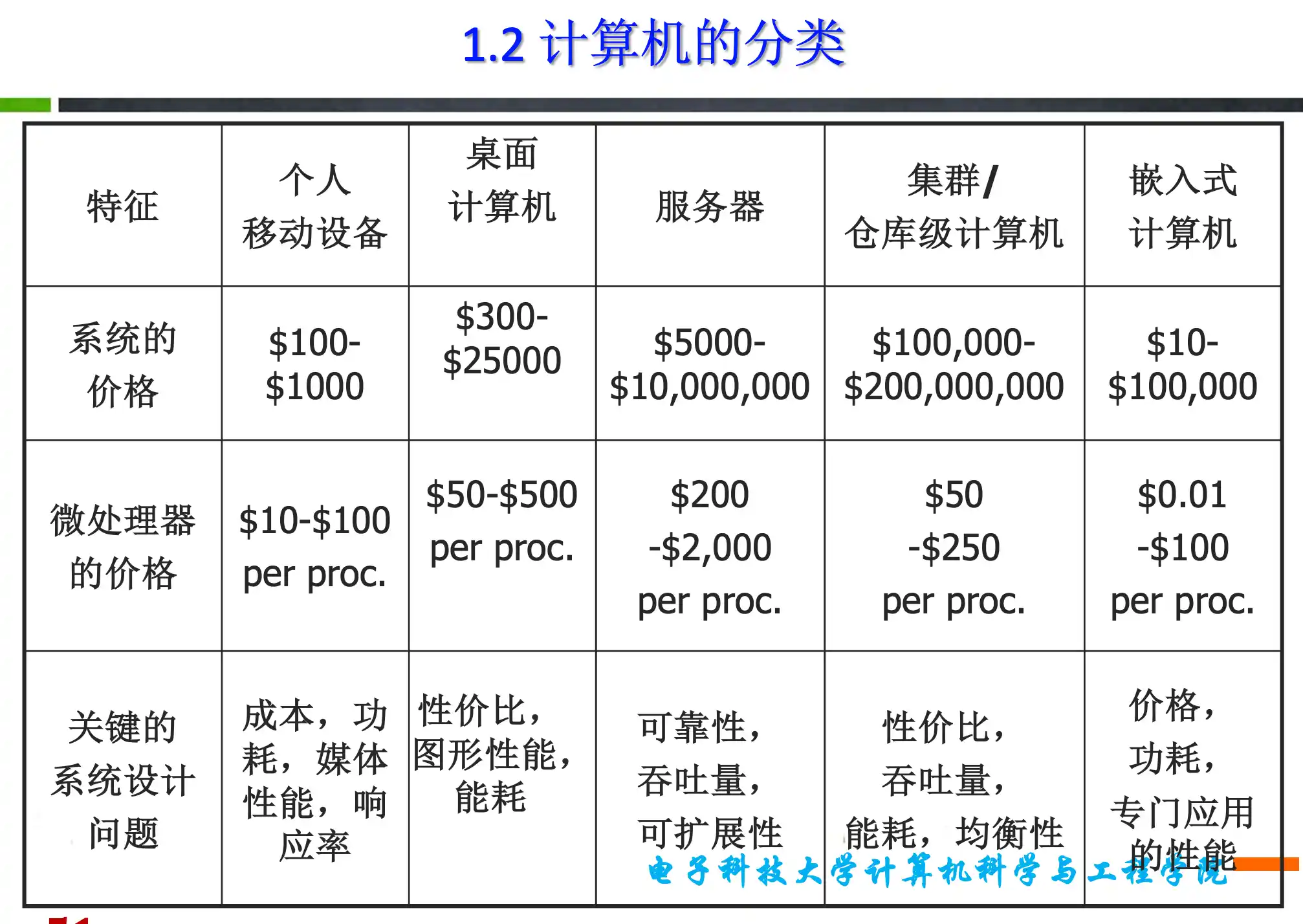
嵌入式作为一个系统的一部分,还应考虑其实时性
计算机系统结构定义和计算机的设计任务:指令集结构概念以及要素




实现的技术趋势:技术发展趋势


cache用的是sram 主存用的是dram



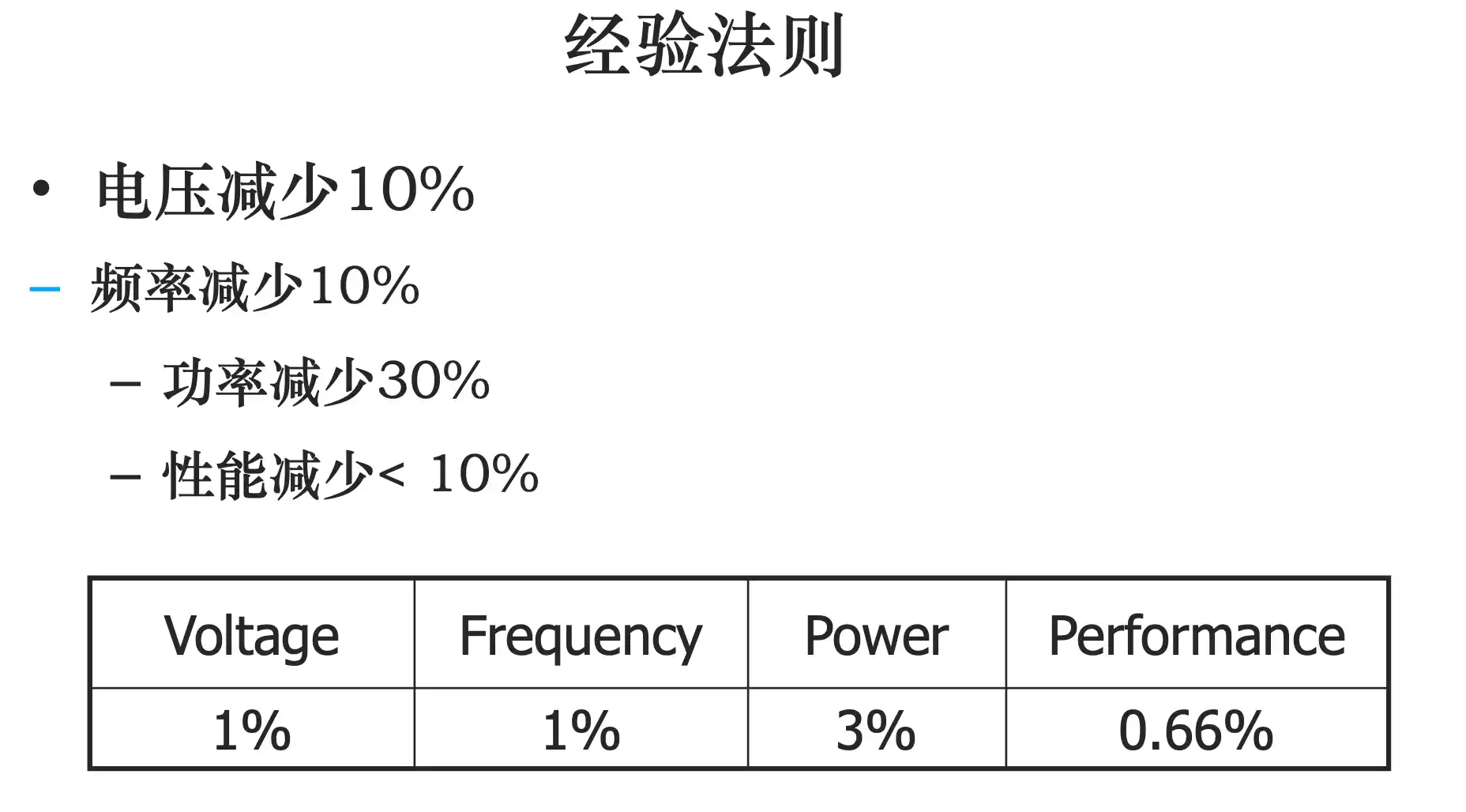
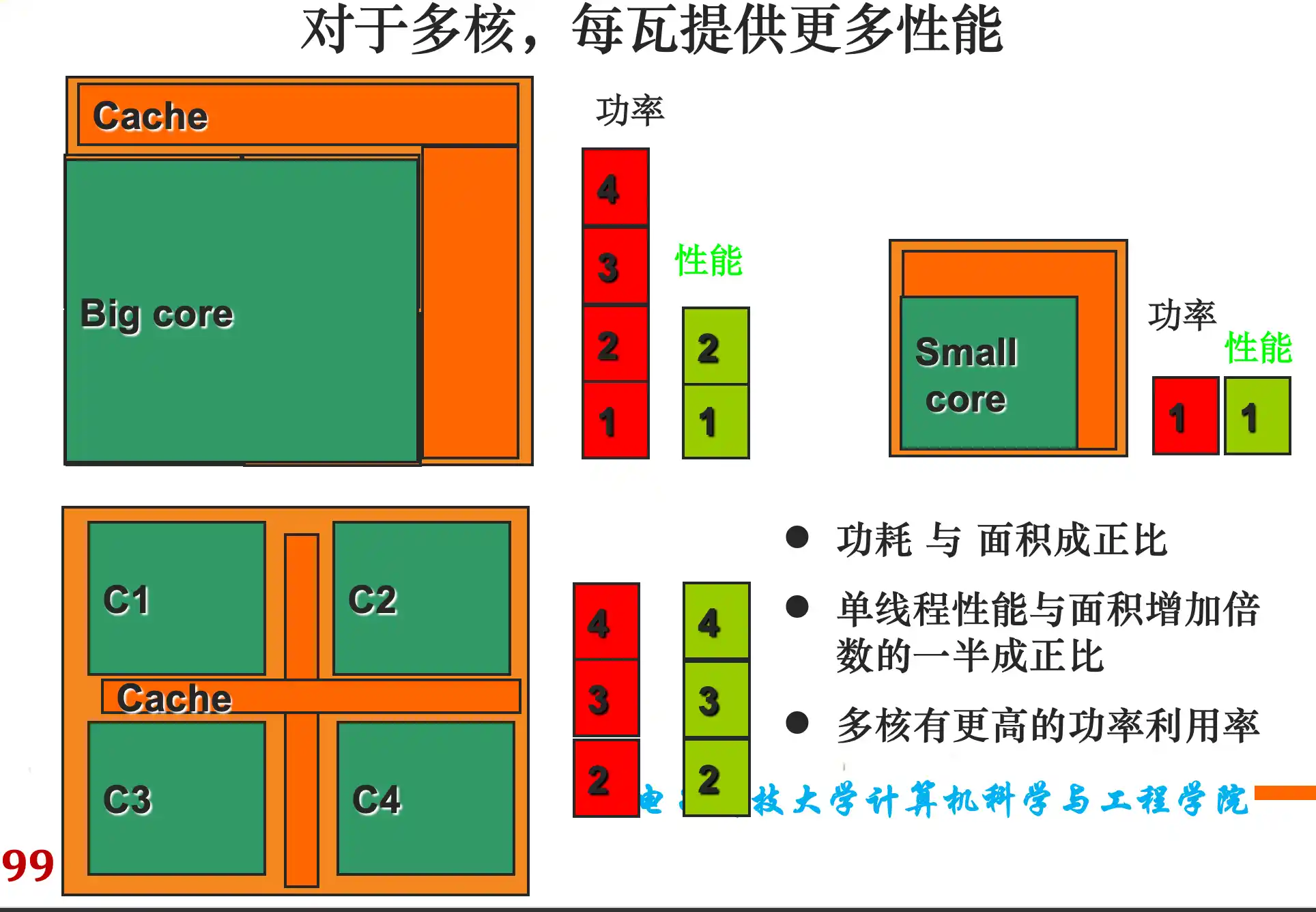
集成电路功耗的趋势:功耗的概念


可靠性:计算可靠性的方法




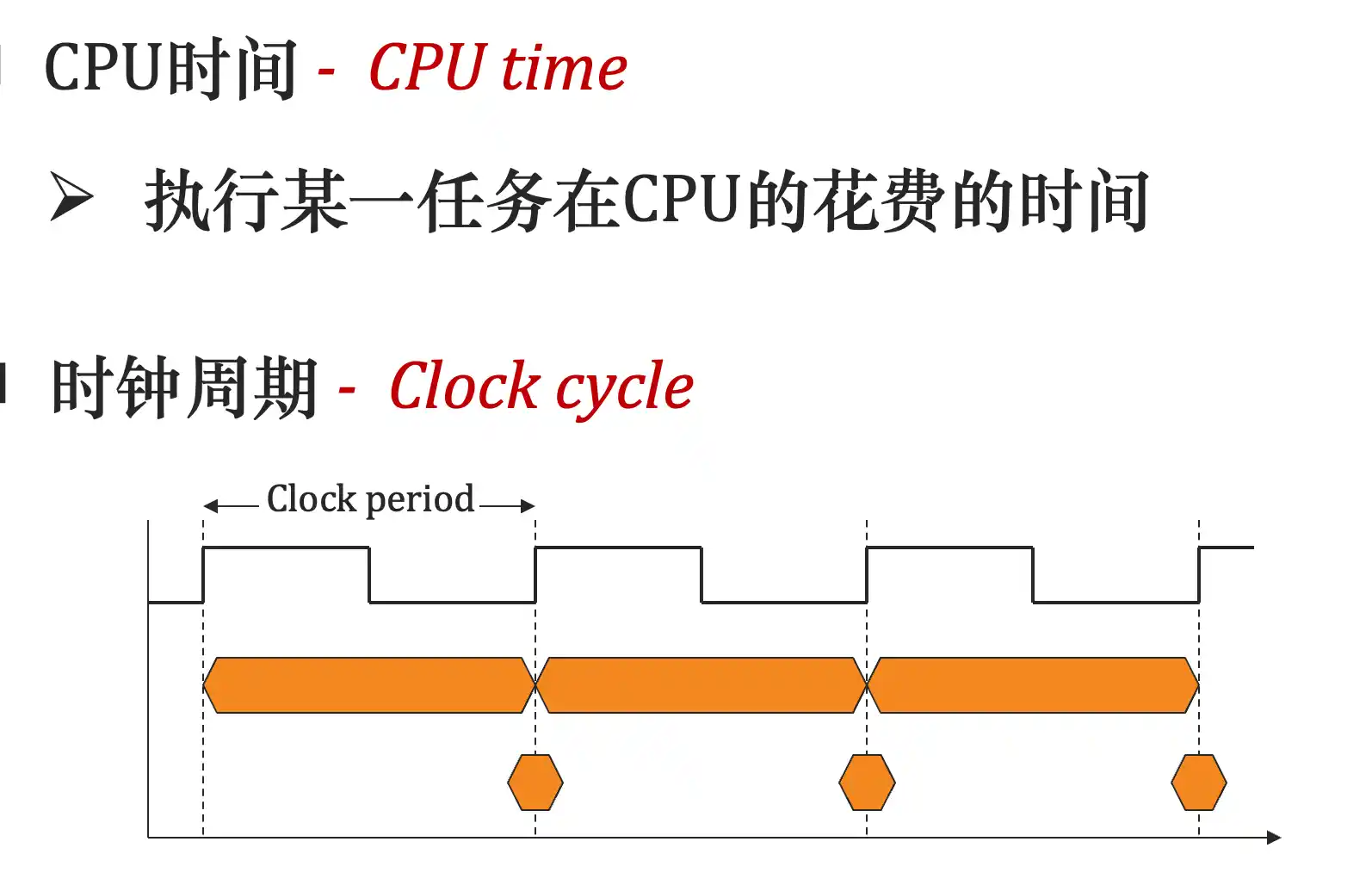
测量、报告和总结计算机性能:计算机主要性能指标



如果一个是RISC一个CISC这种MIPS的比较方法就不公平 (CPI可能不一样)
可以先算IPS每秒执行多少指令,然后再除1million(1后面6个0)







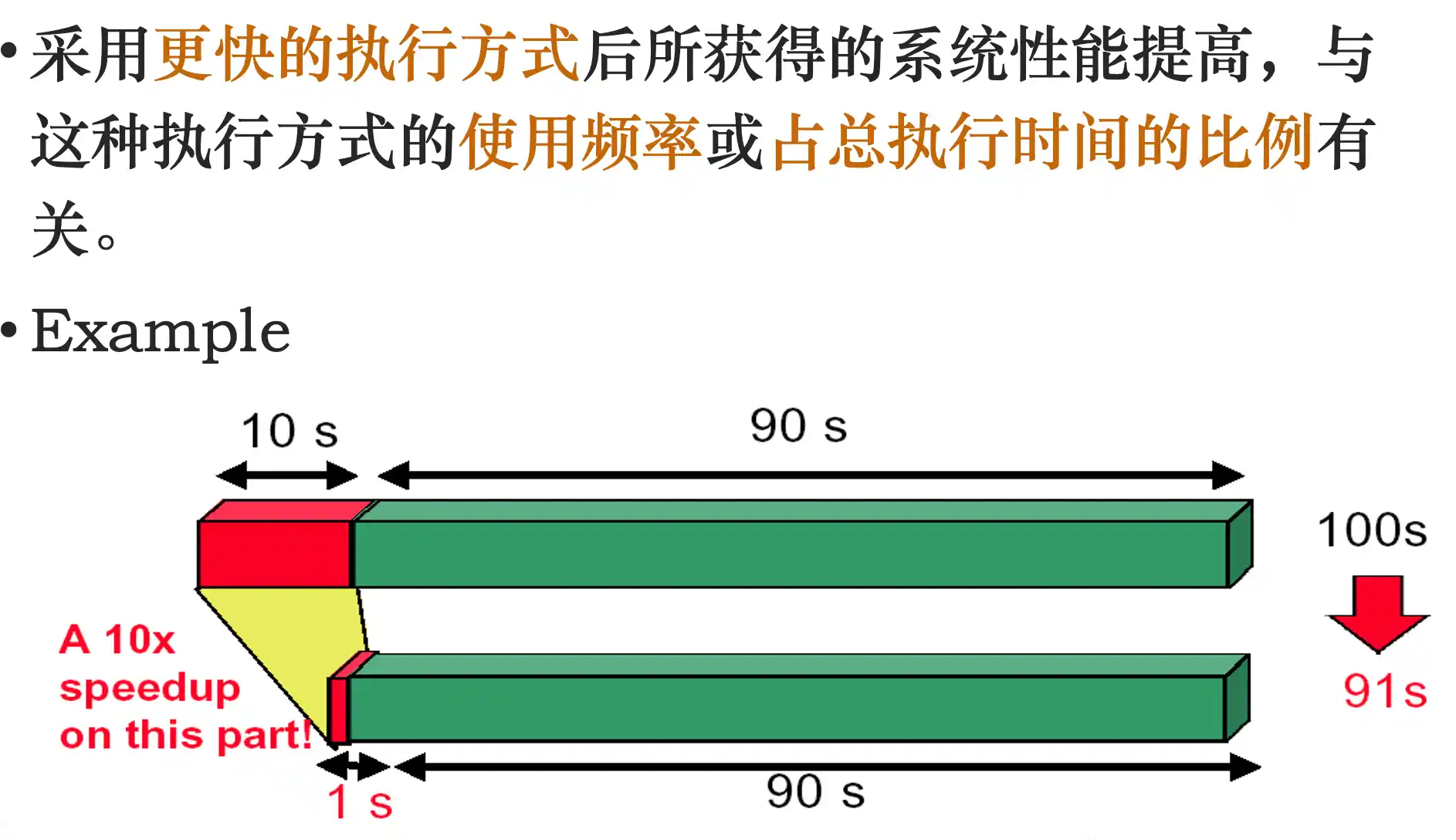
计算机设计的量化原则:Amdahl定律






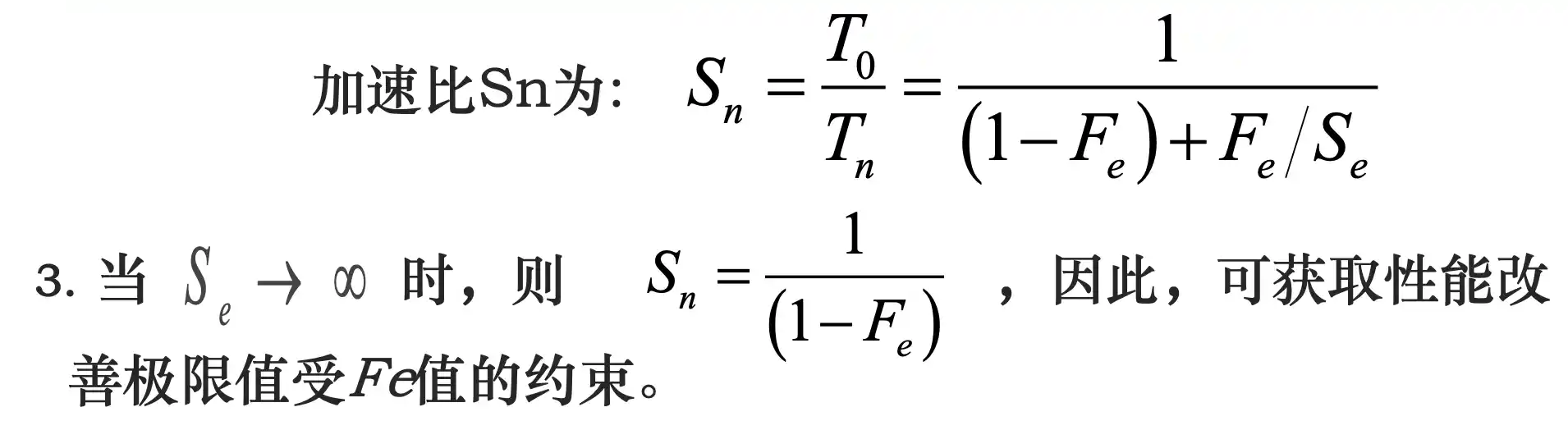



陷阱




第二章 指令系统原理与实例
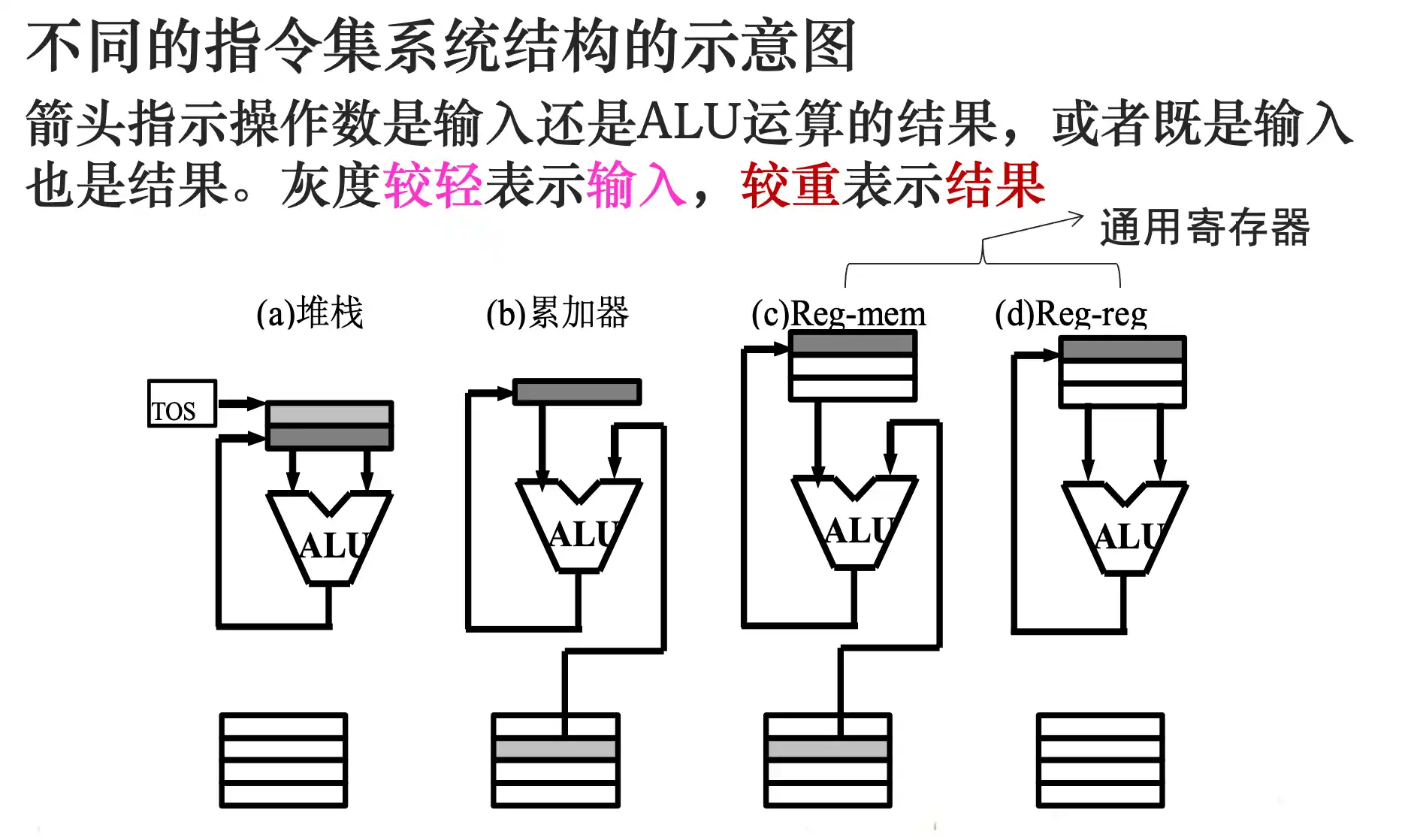
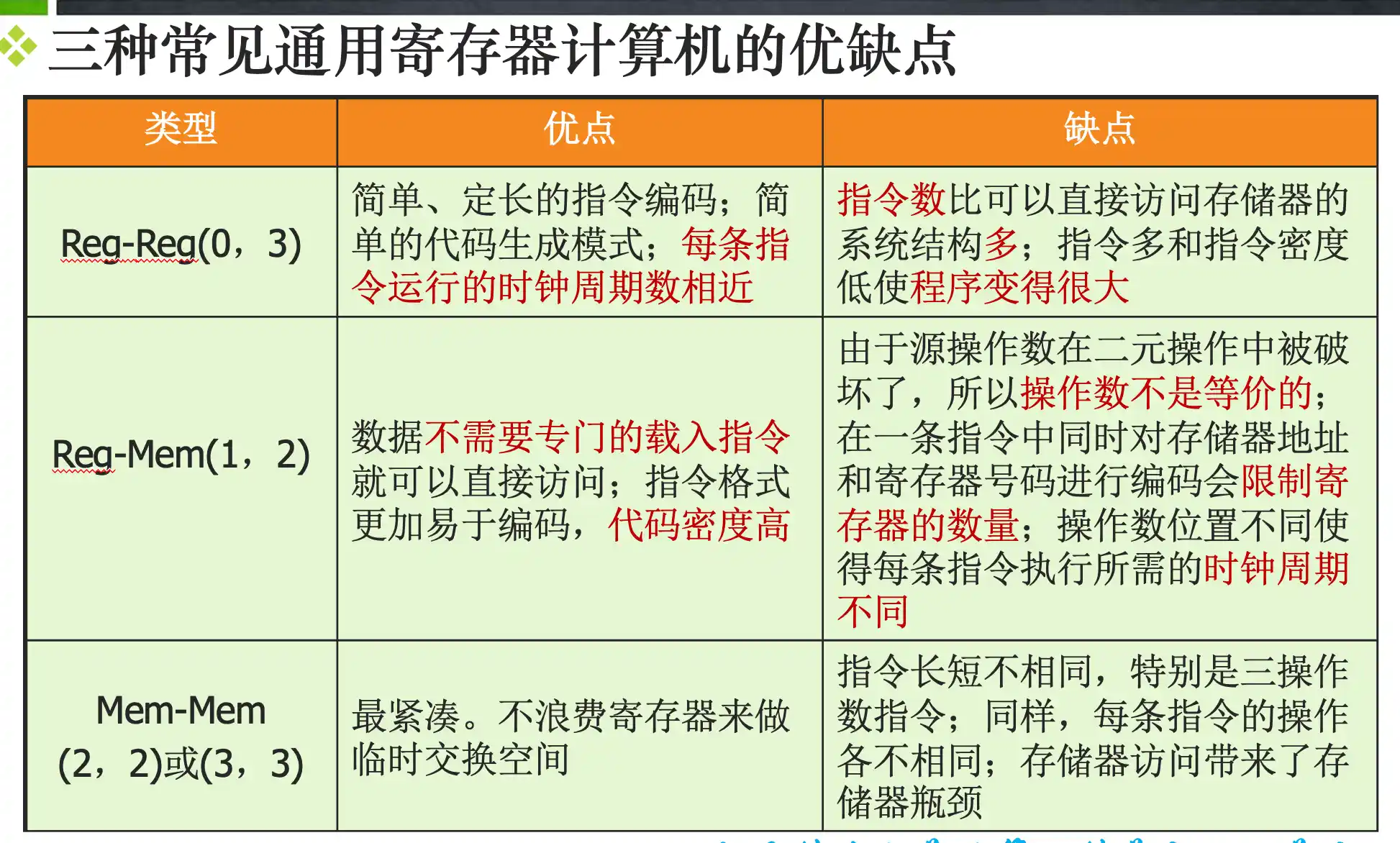
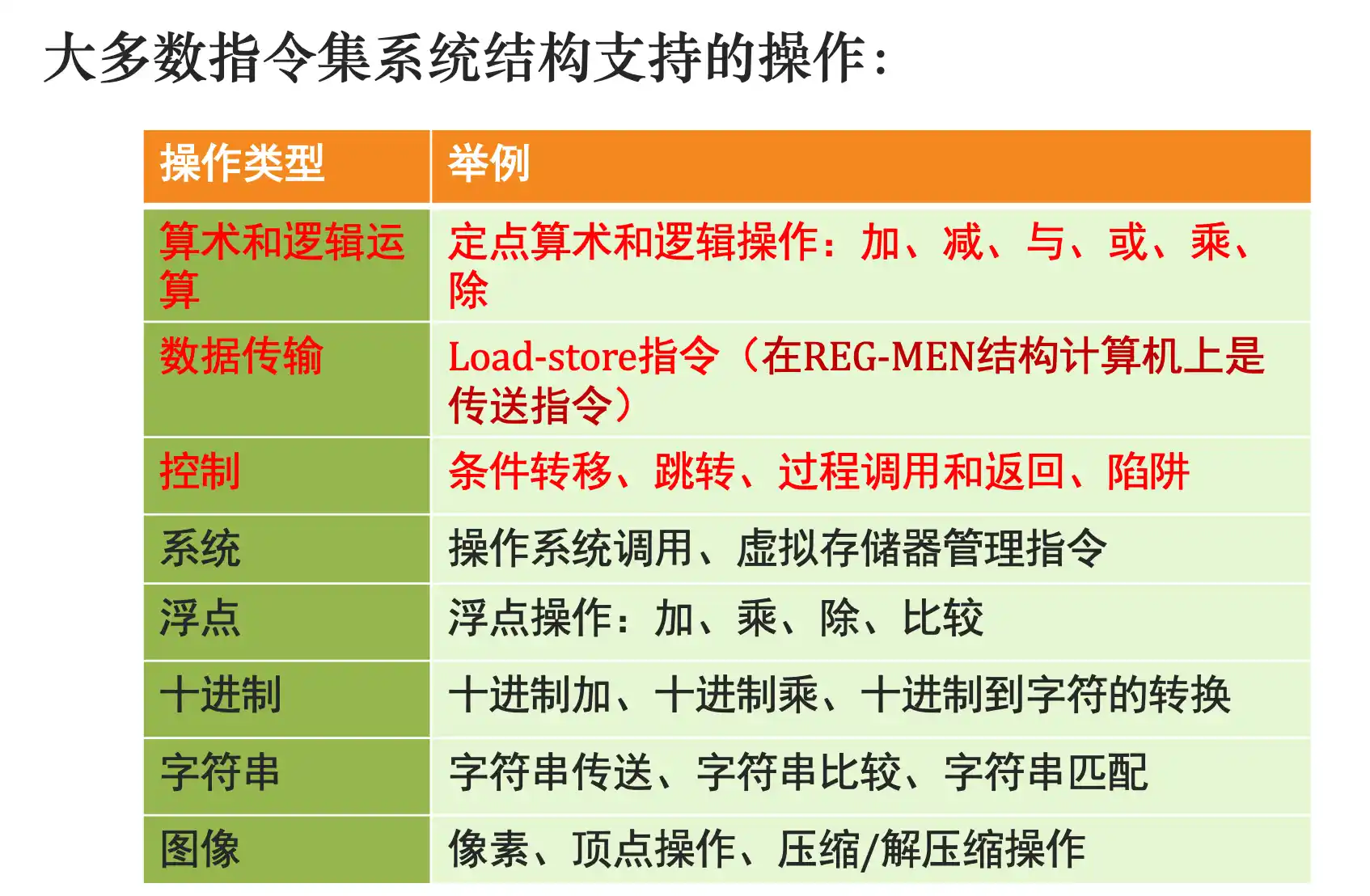
指令集系统结构的分类:指令集系统的不同结构





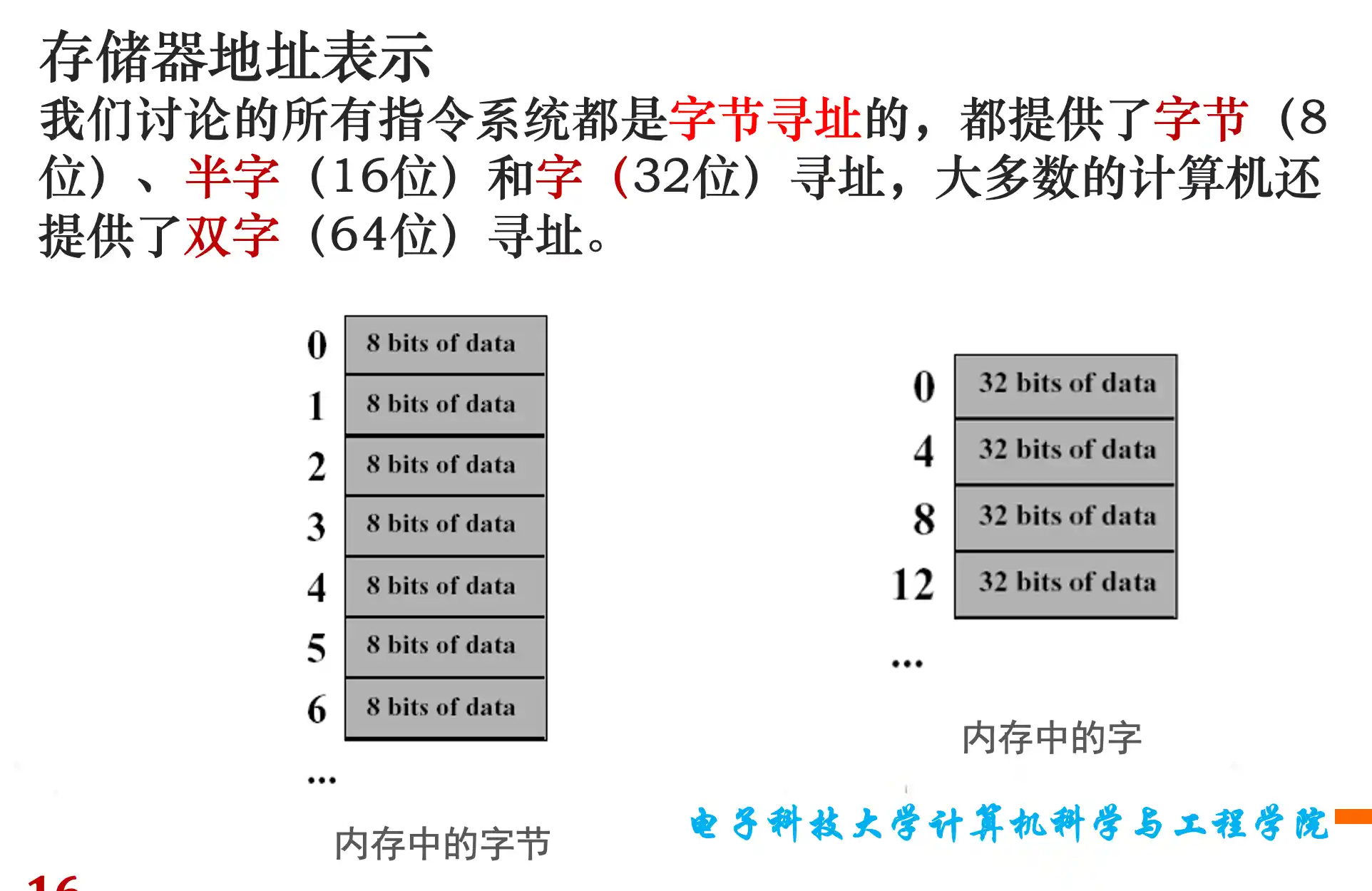
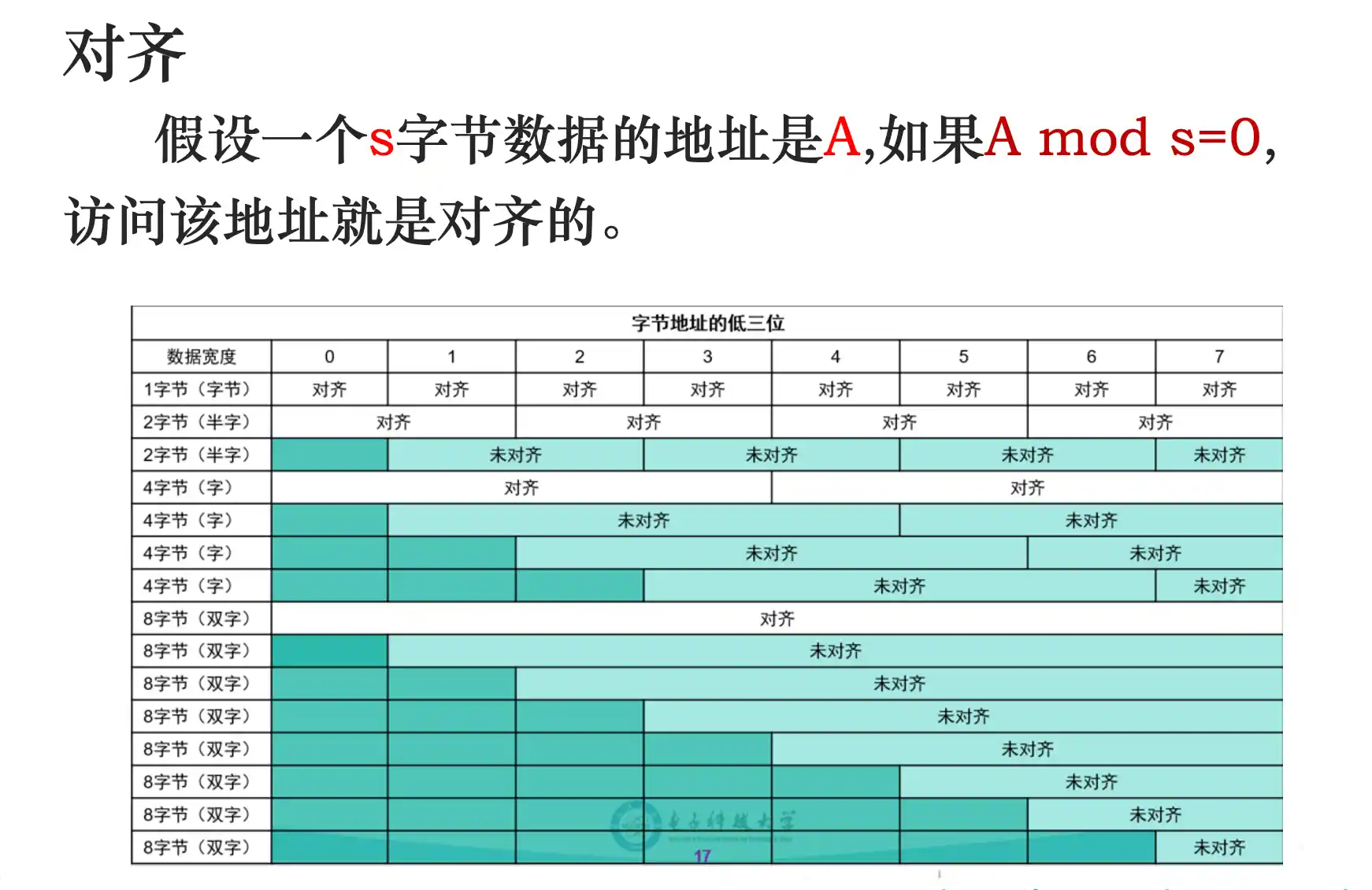
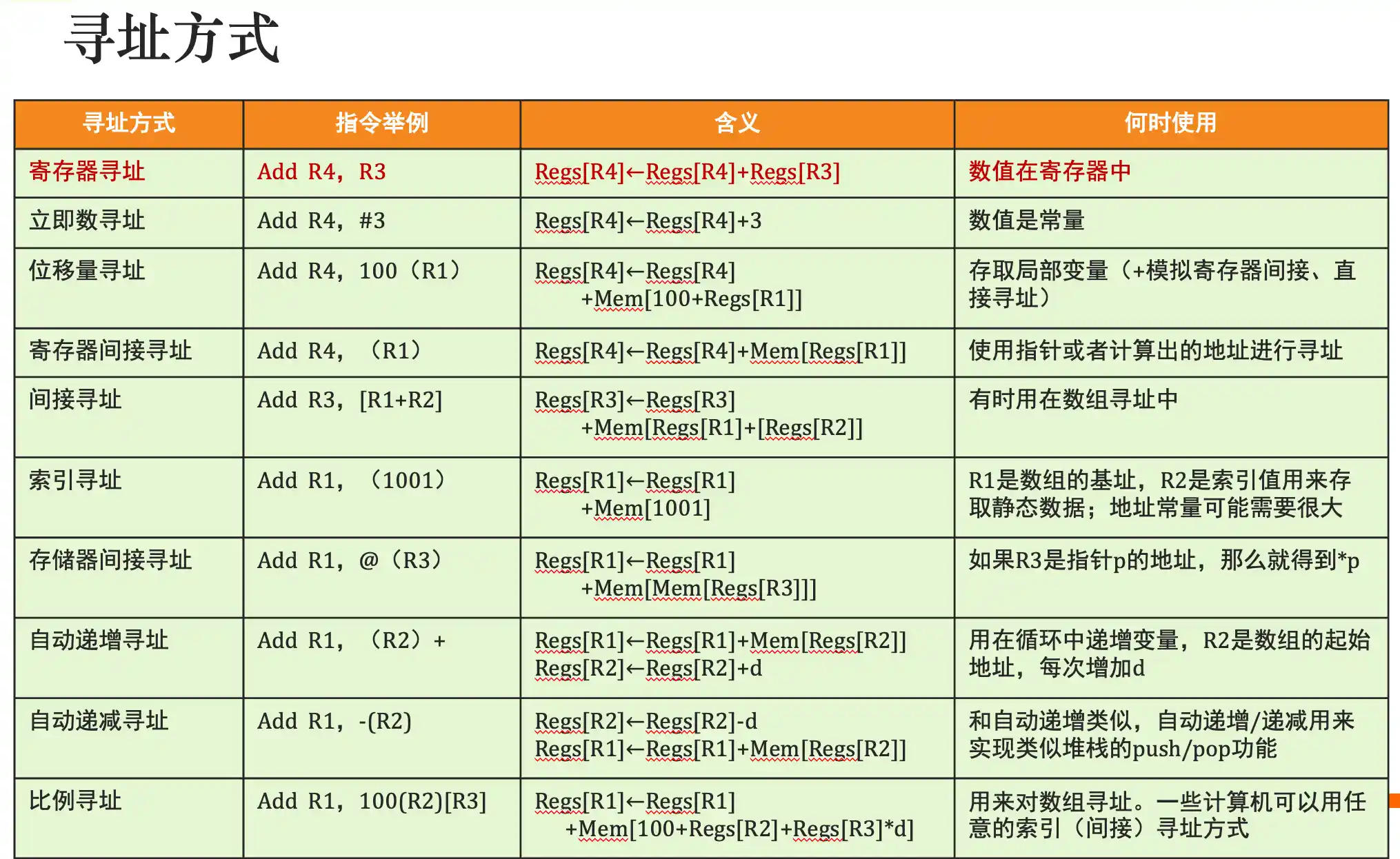
存储器寻址:大小端模式及地址对齐





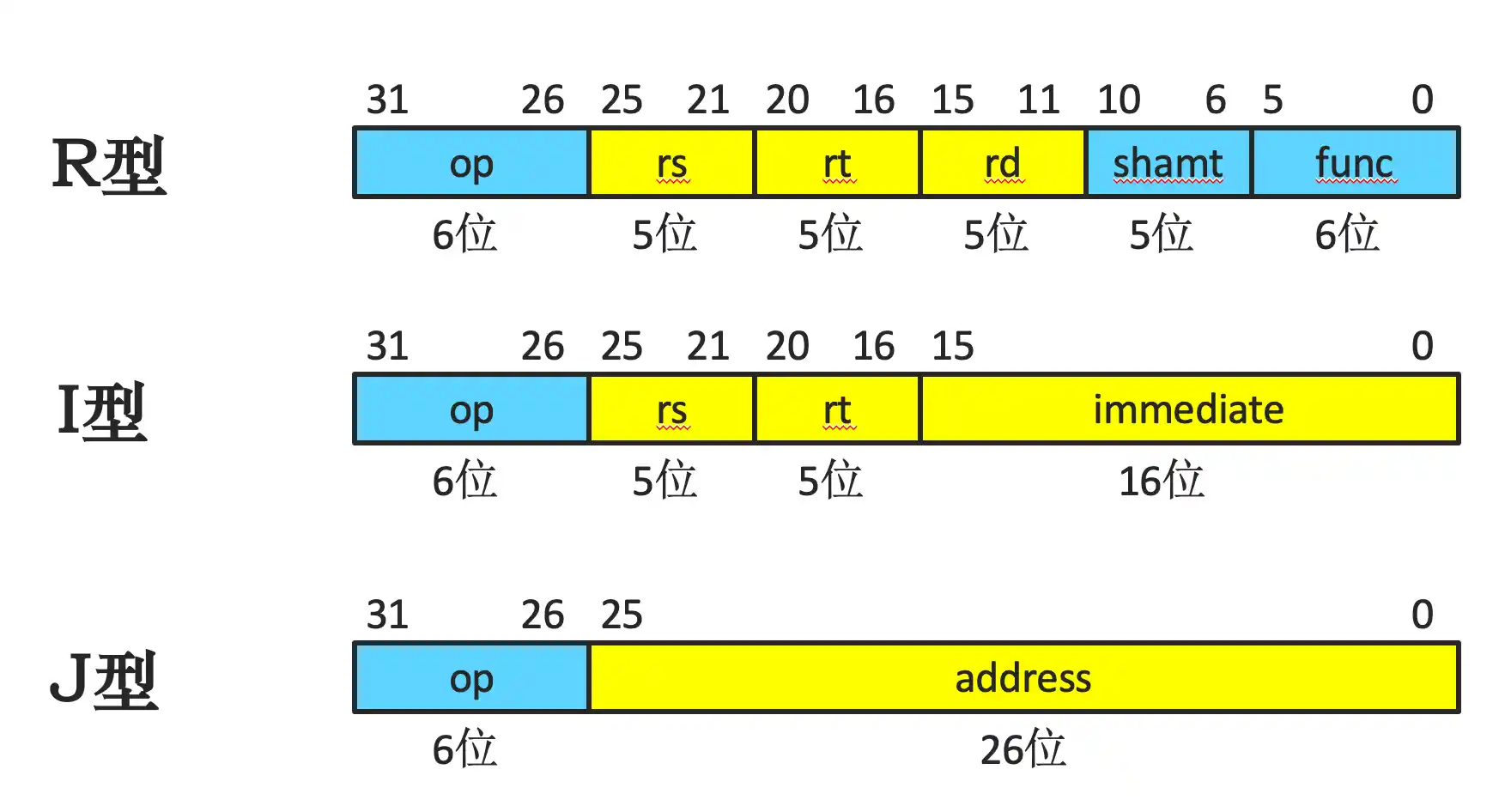
MIPS系统结构:MIPS指令集结构






其他



所以跳转指令中imm 在sign后要<<2 因为表示的是指令个数,一个指令4字节

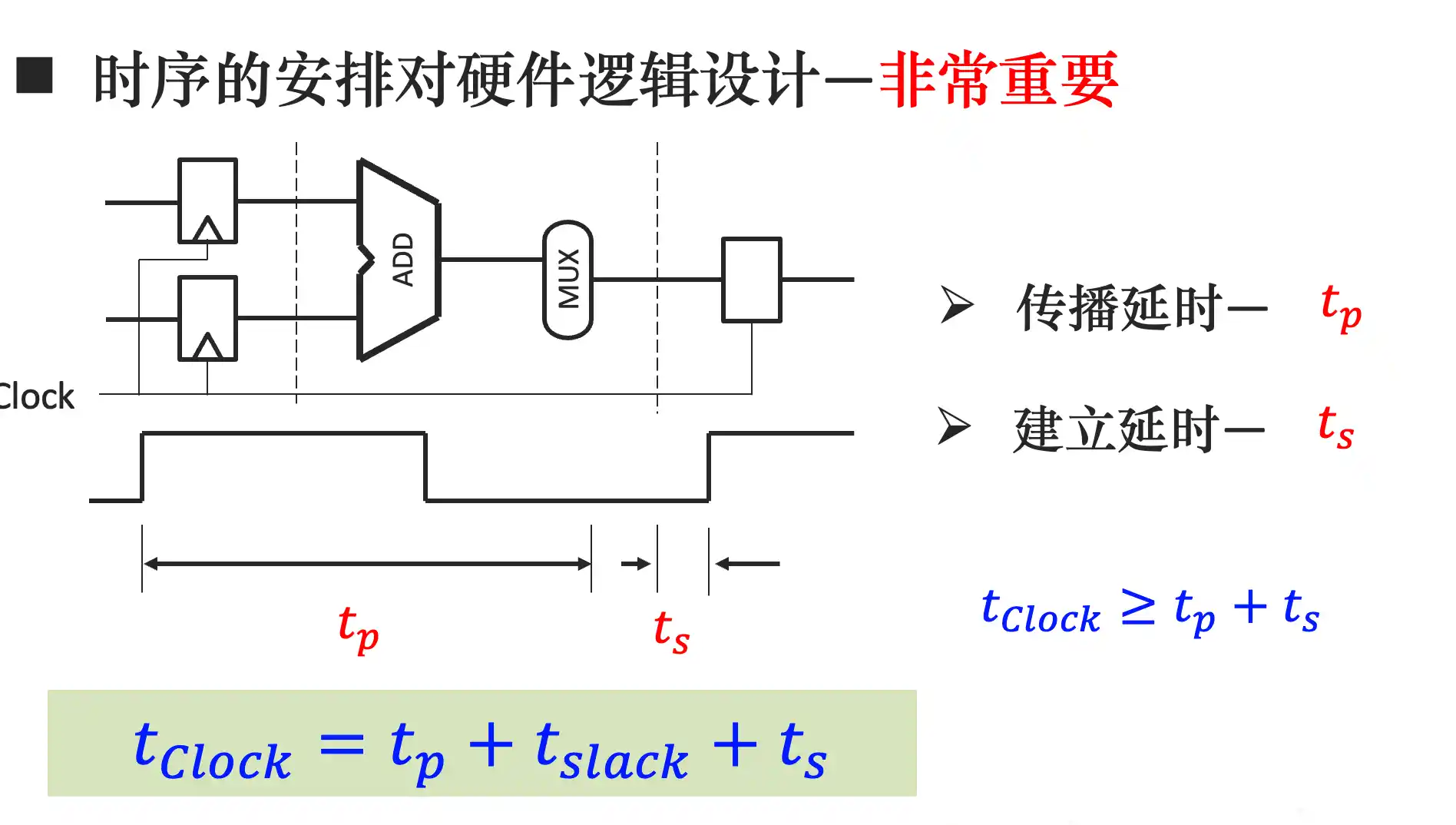
第三章 单周期MIPS处理器的设计
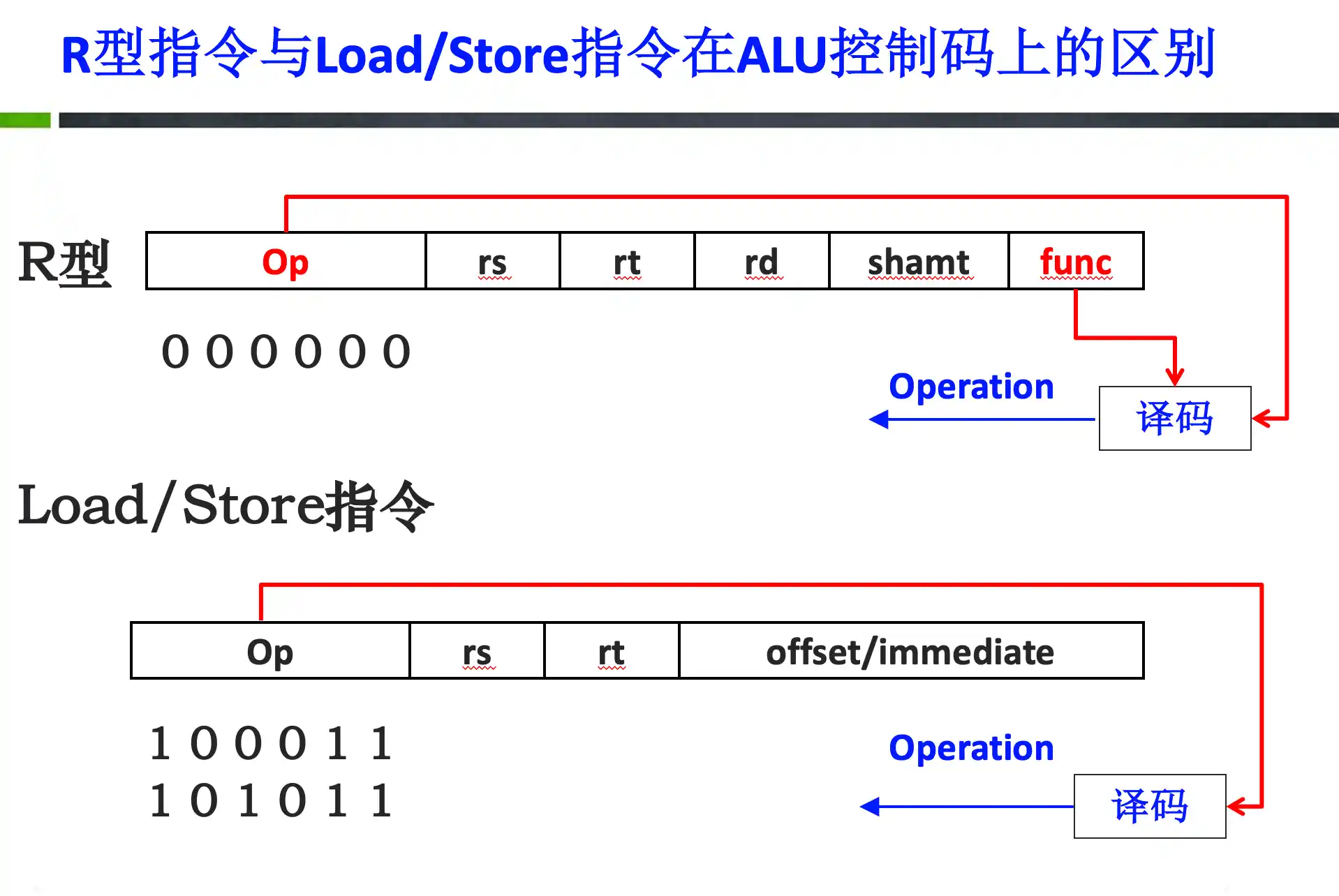
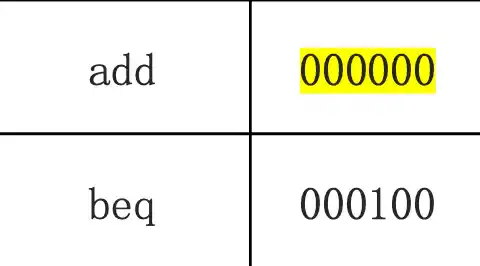
add, sub, addi, subi, lw, sw, beq, j 每条指令在单周期处理器中的执行逻辑以及 上述指令的指令编码、代码、功能以及在单周期中的数据通路,条件分支指令的地址计算、单周期各功能部件的控制信号值判断

只有位运算 & j是0拓展

中断和异常的处理时机






第四章 流水线技术及指令级并行
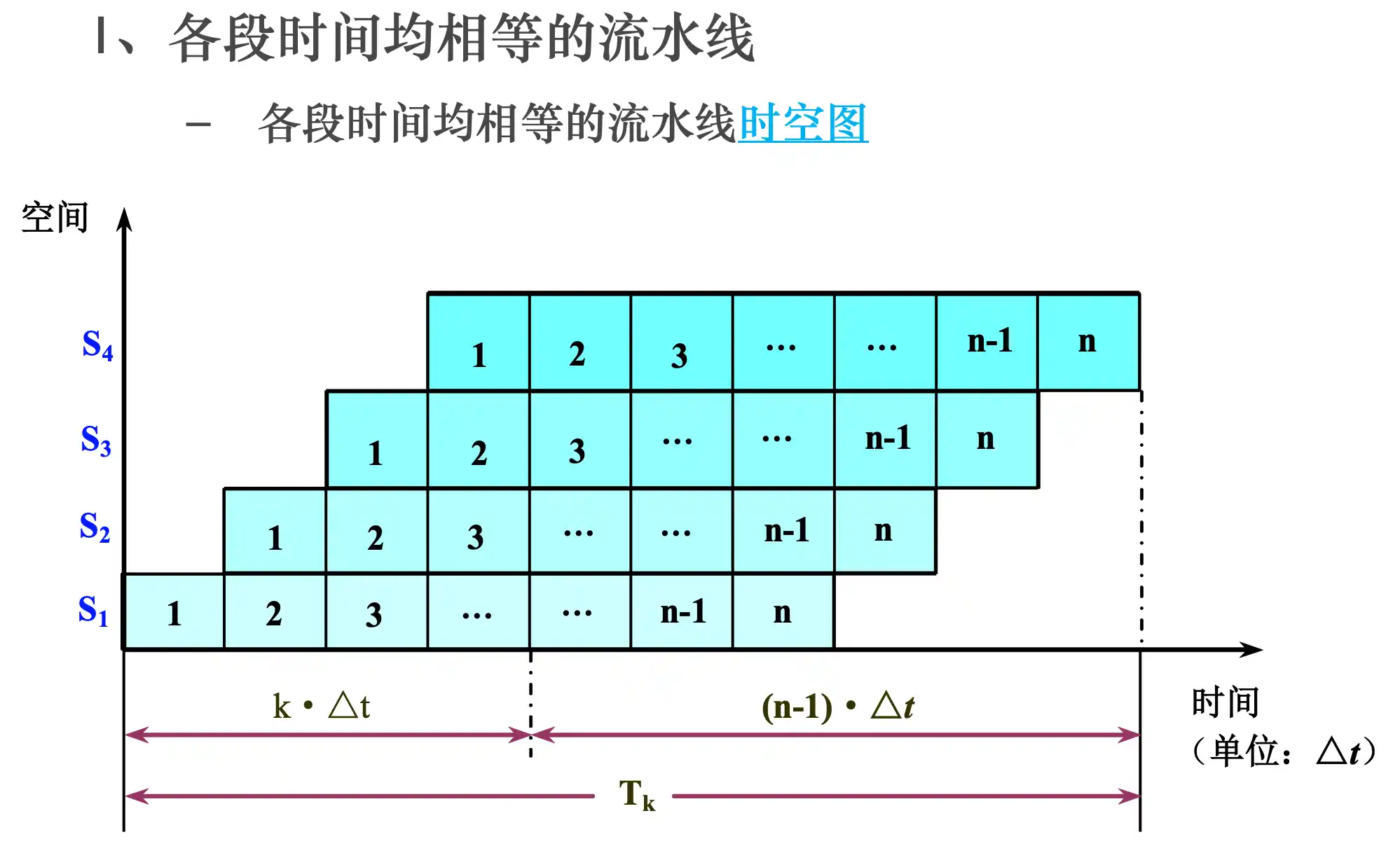
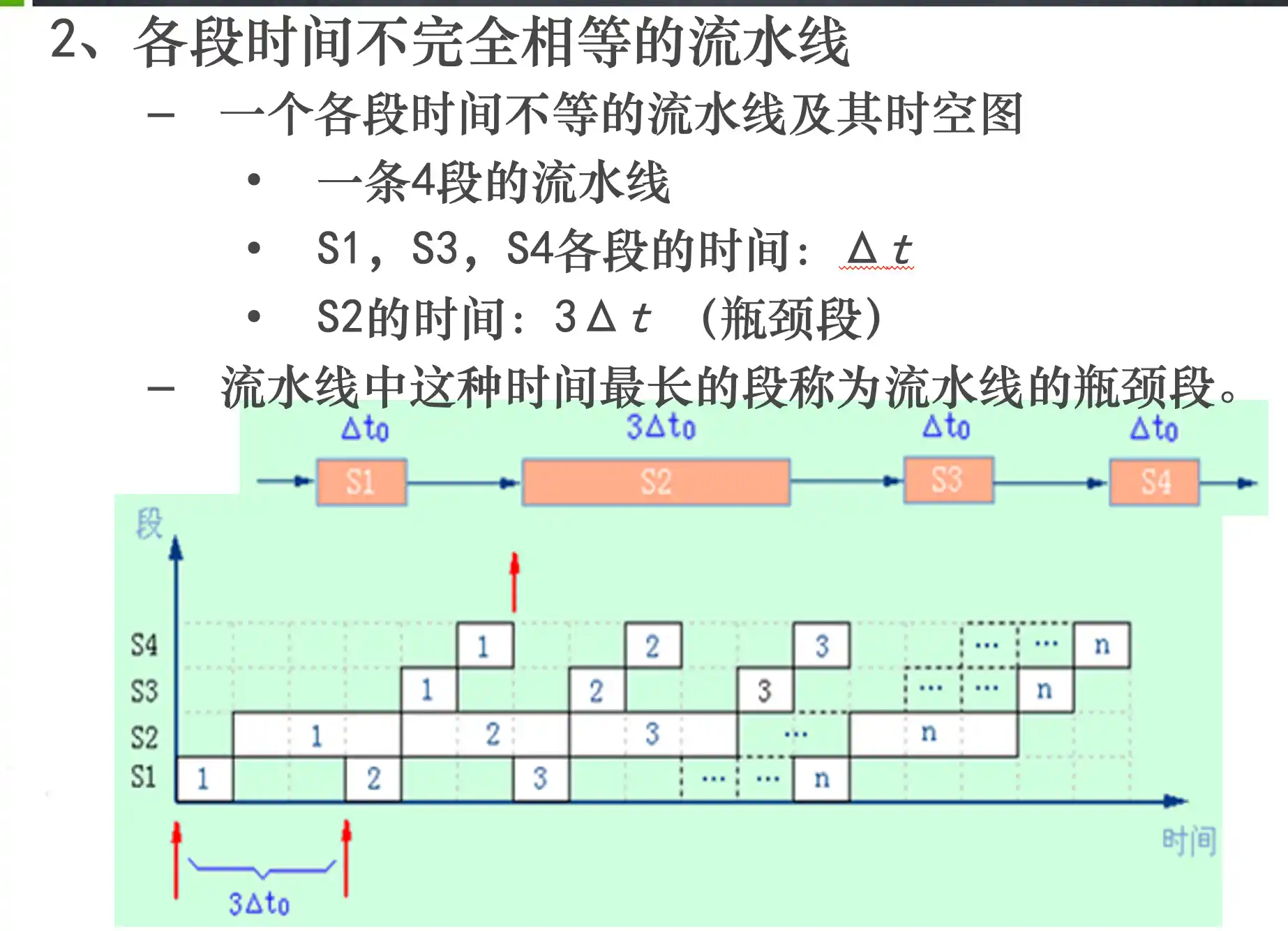
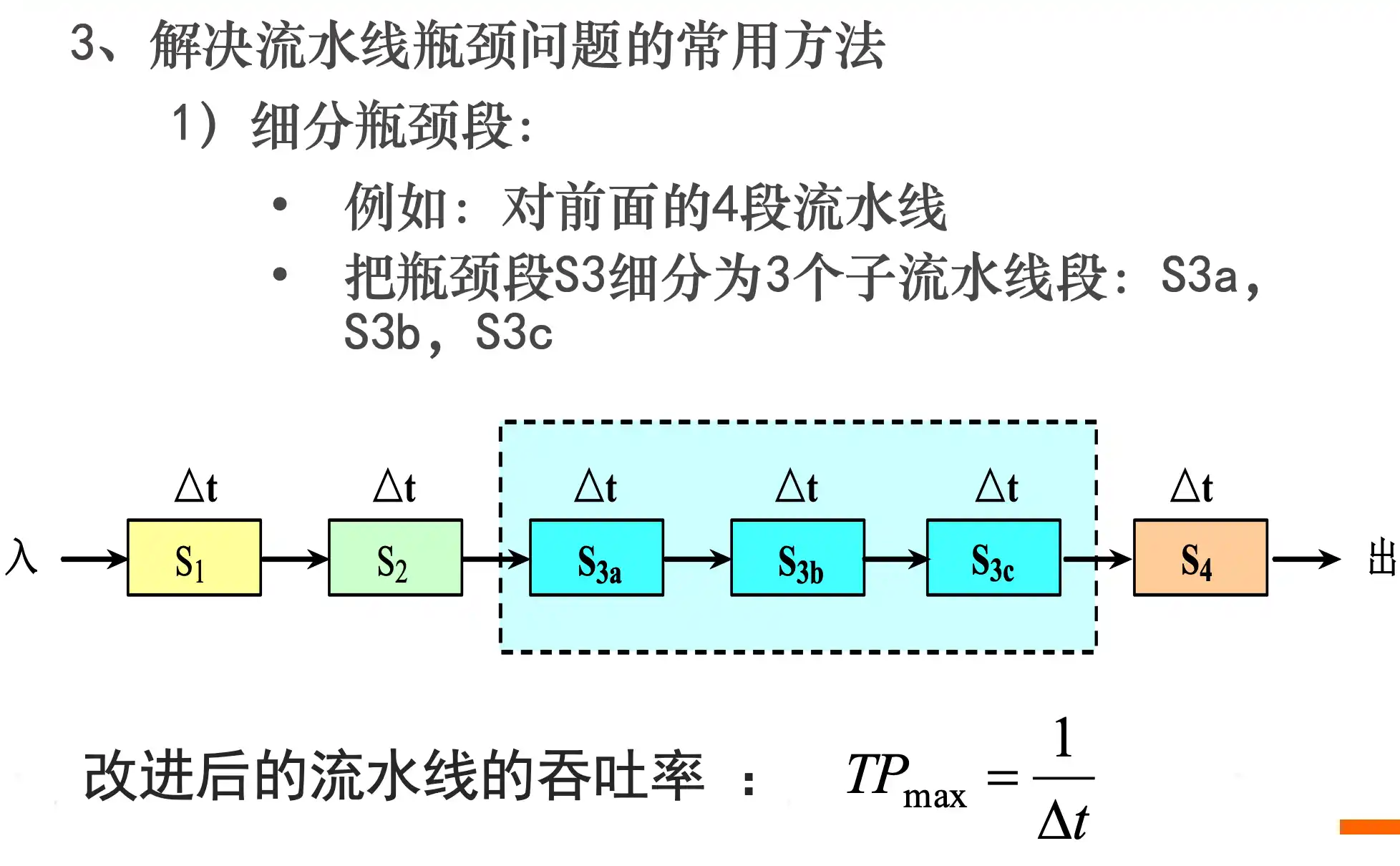
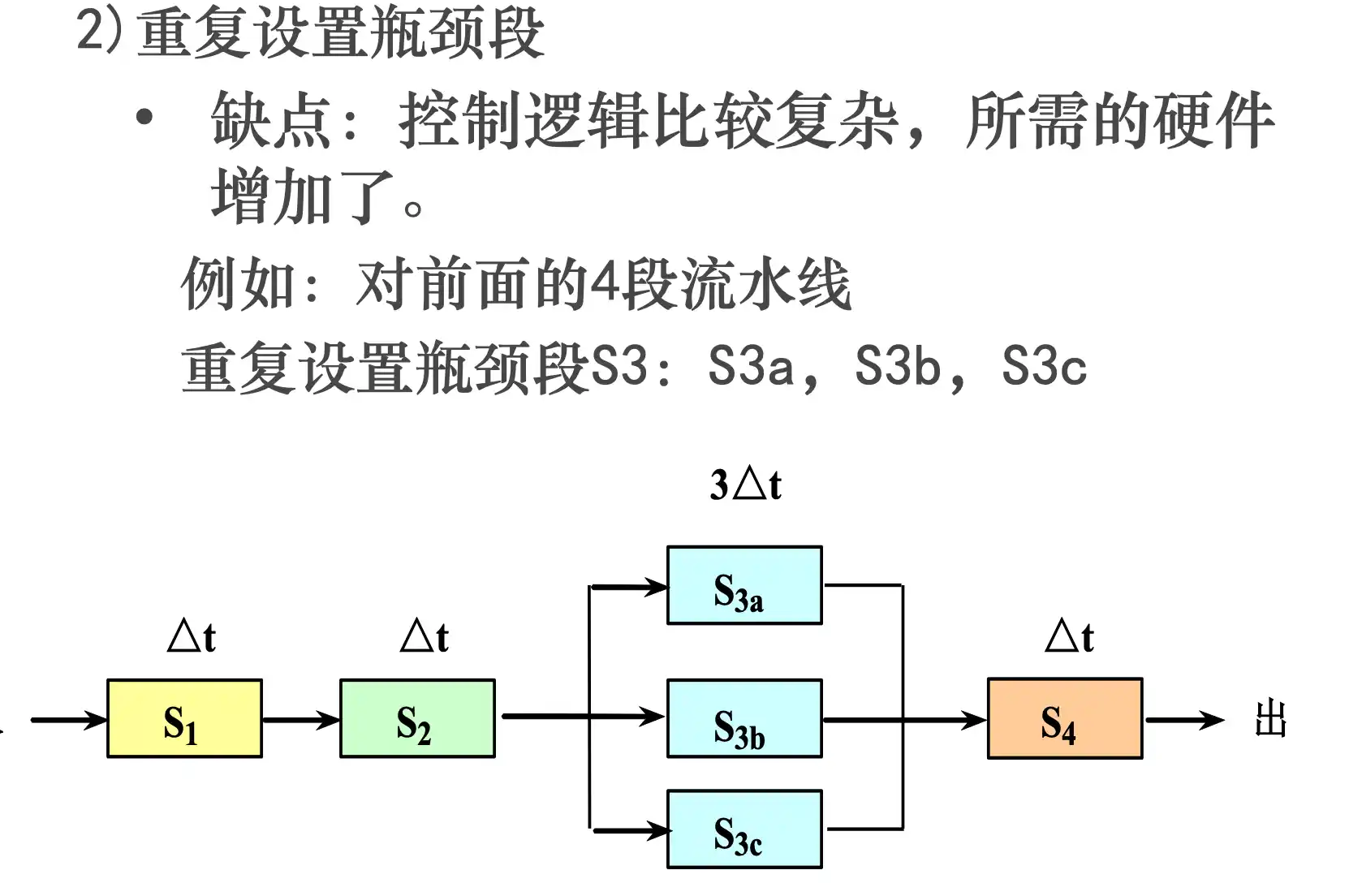
流水线的概念、分类


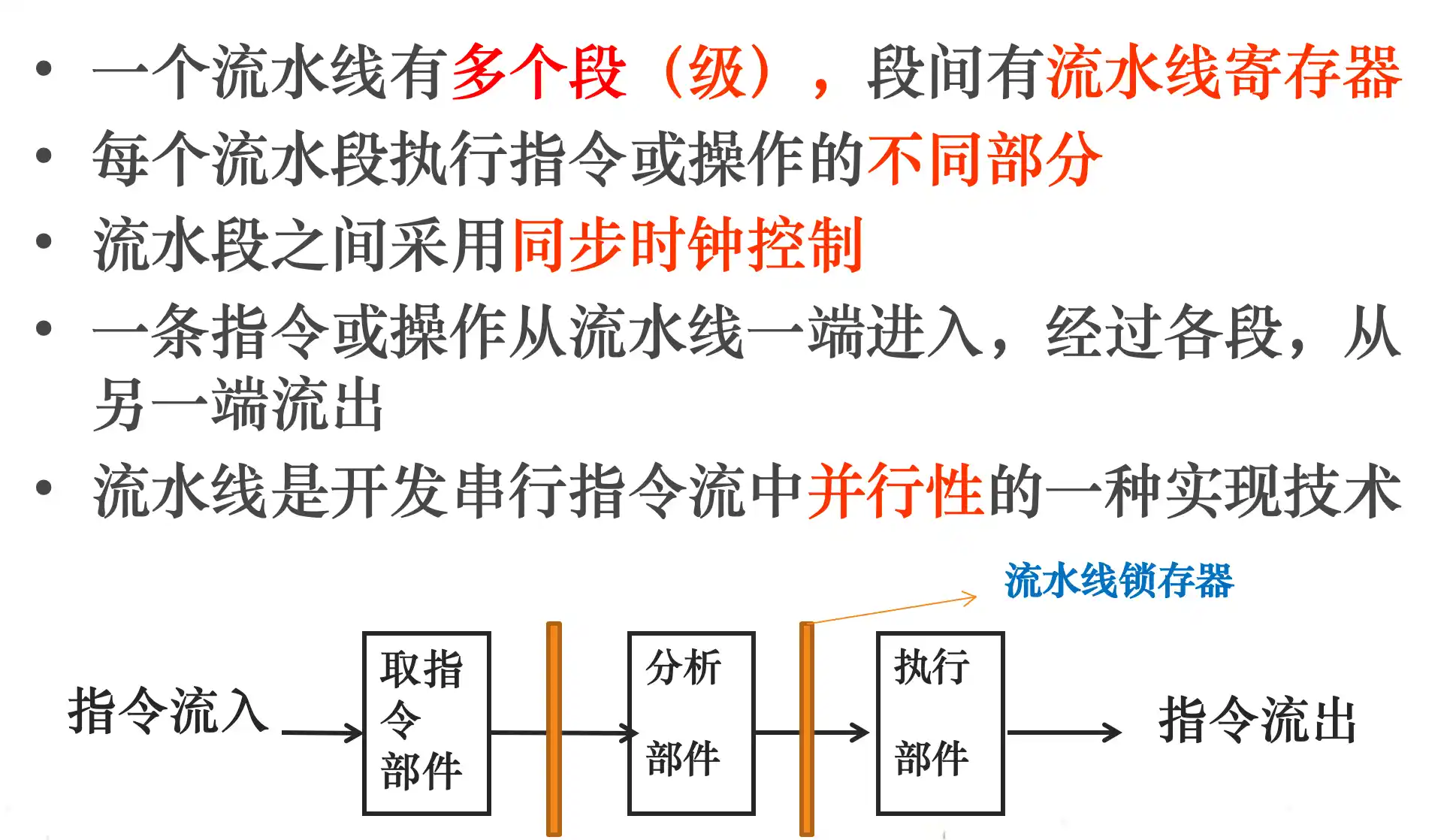




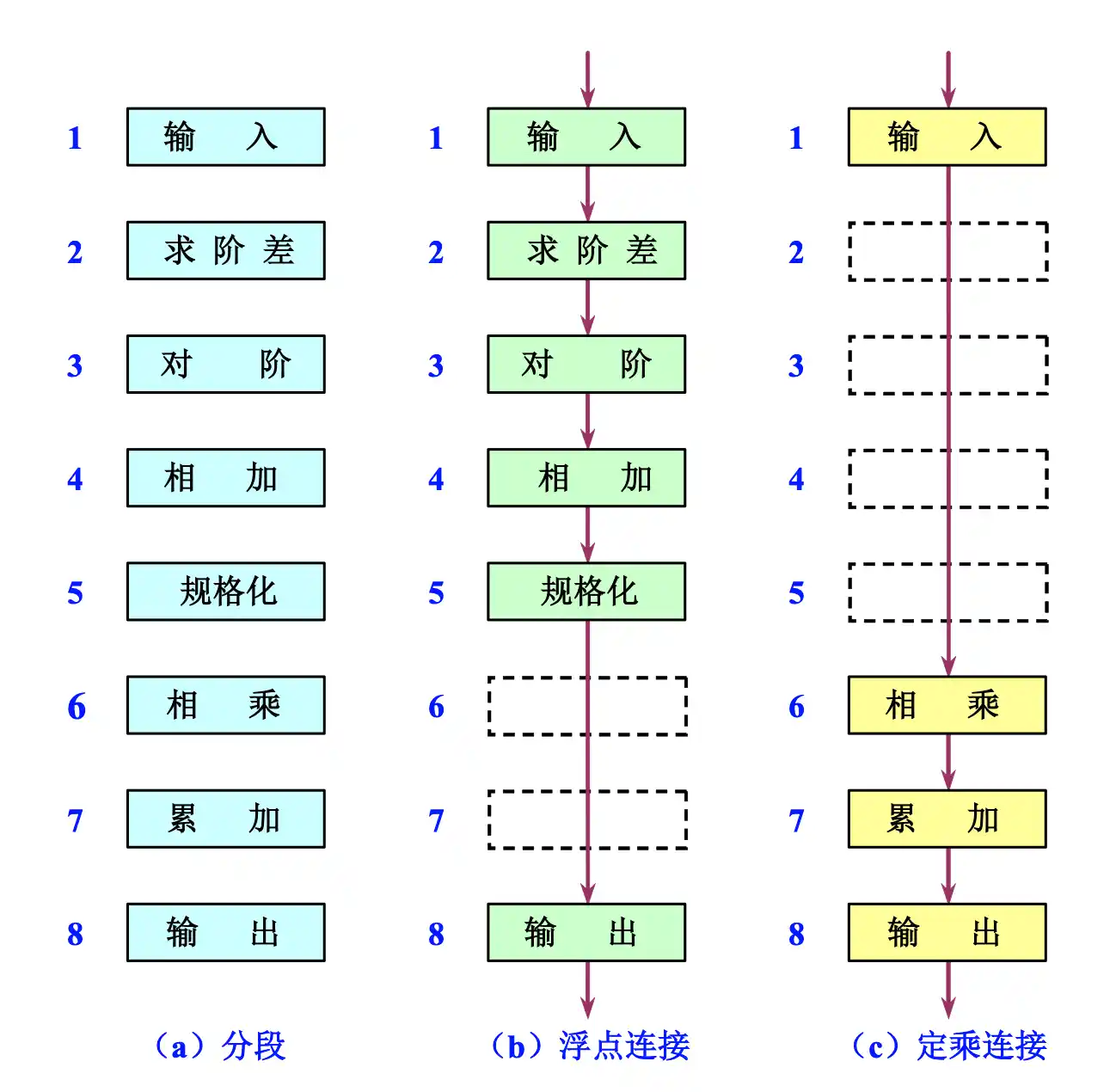

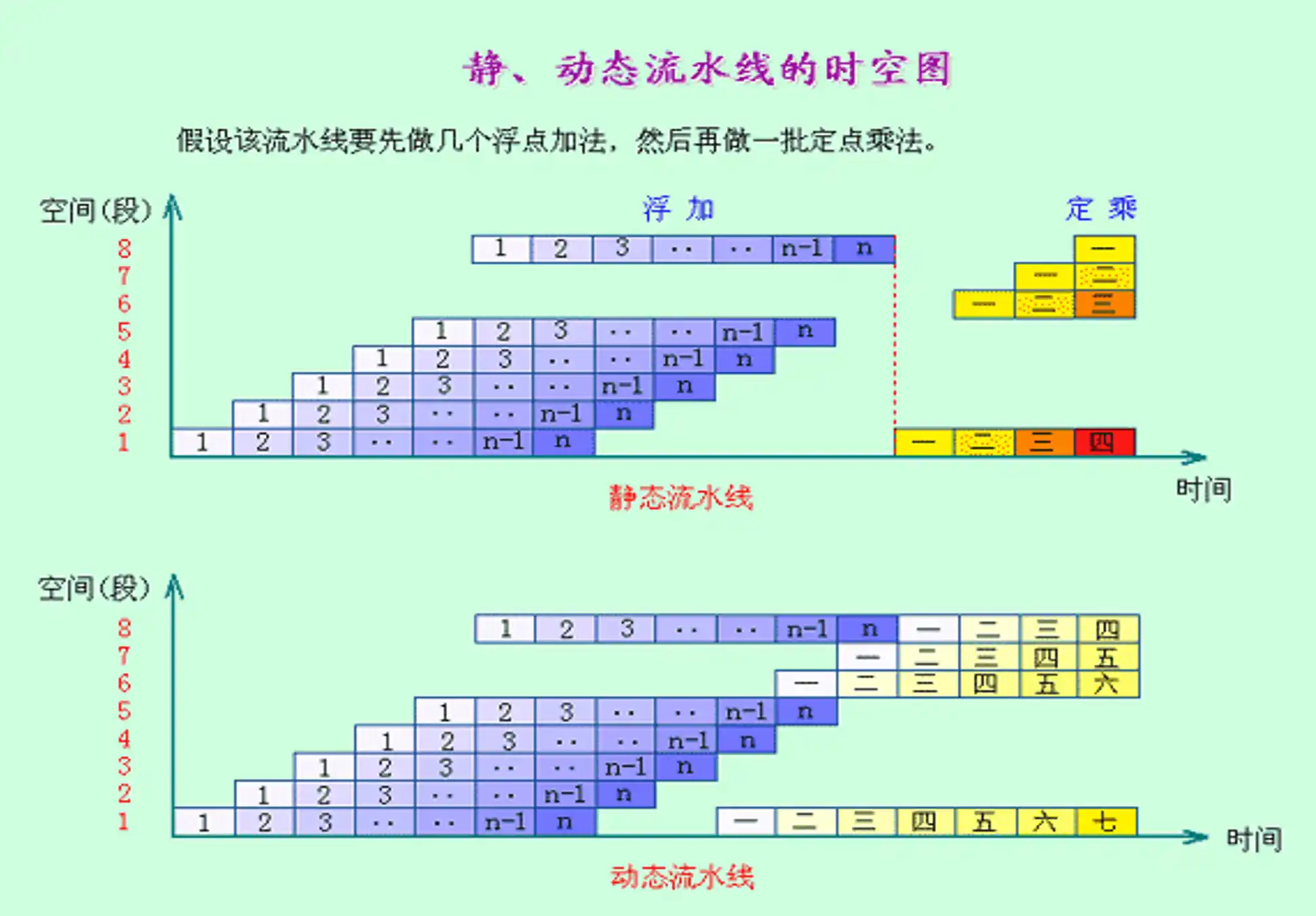

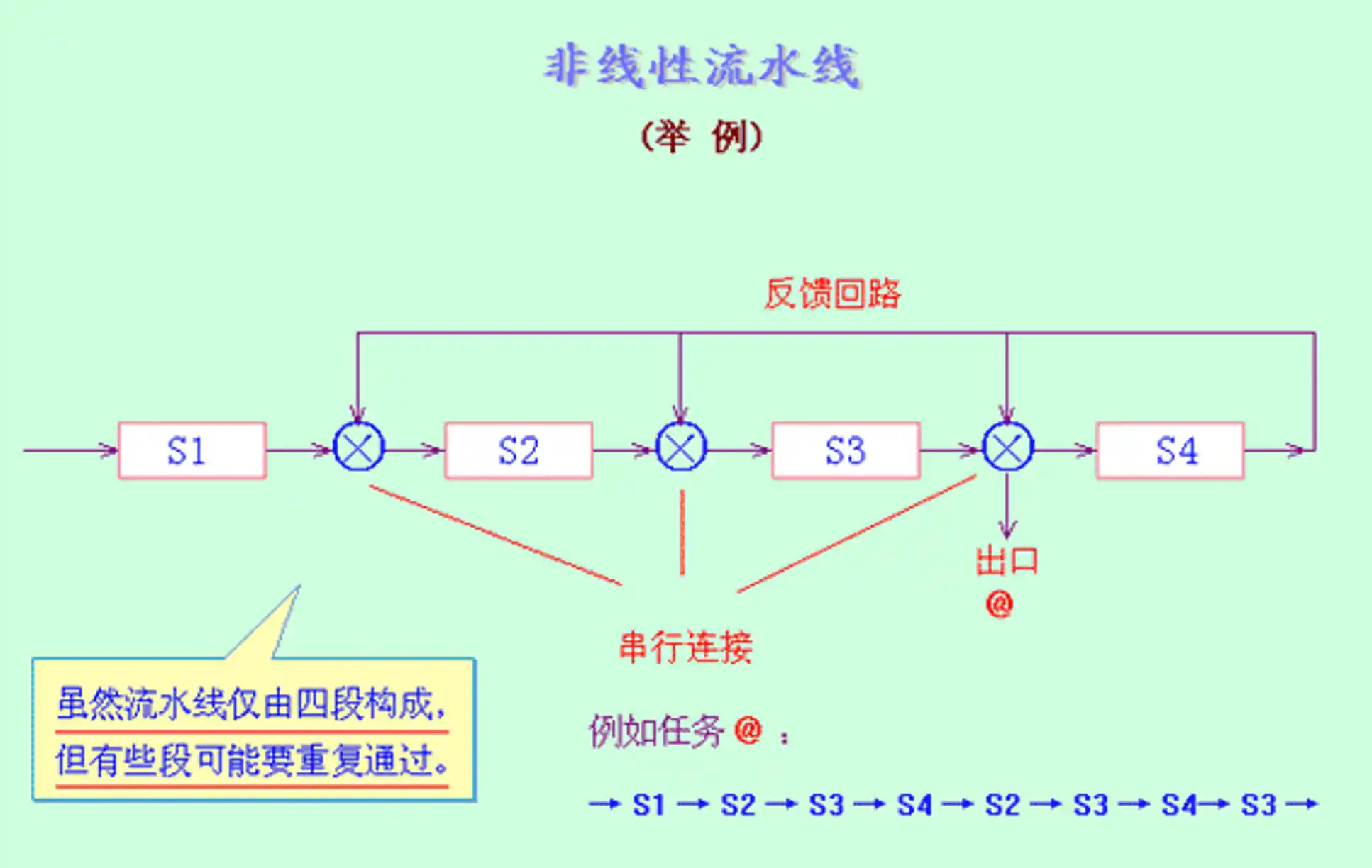


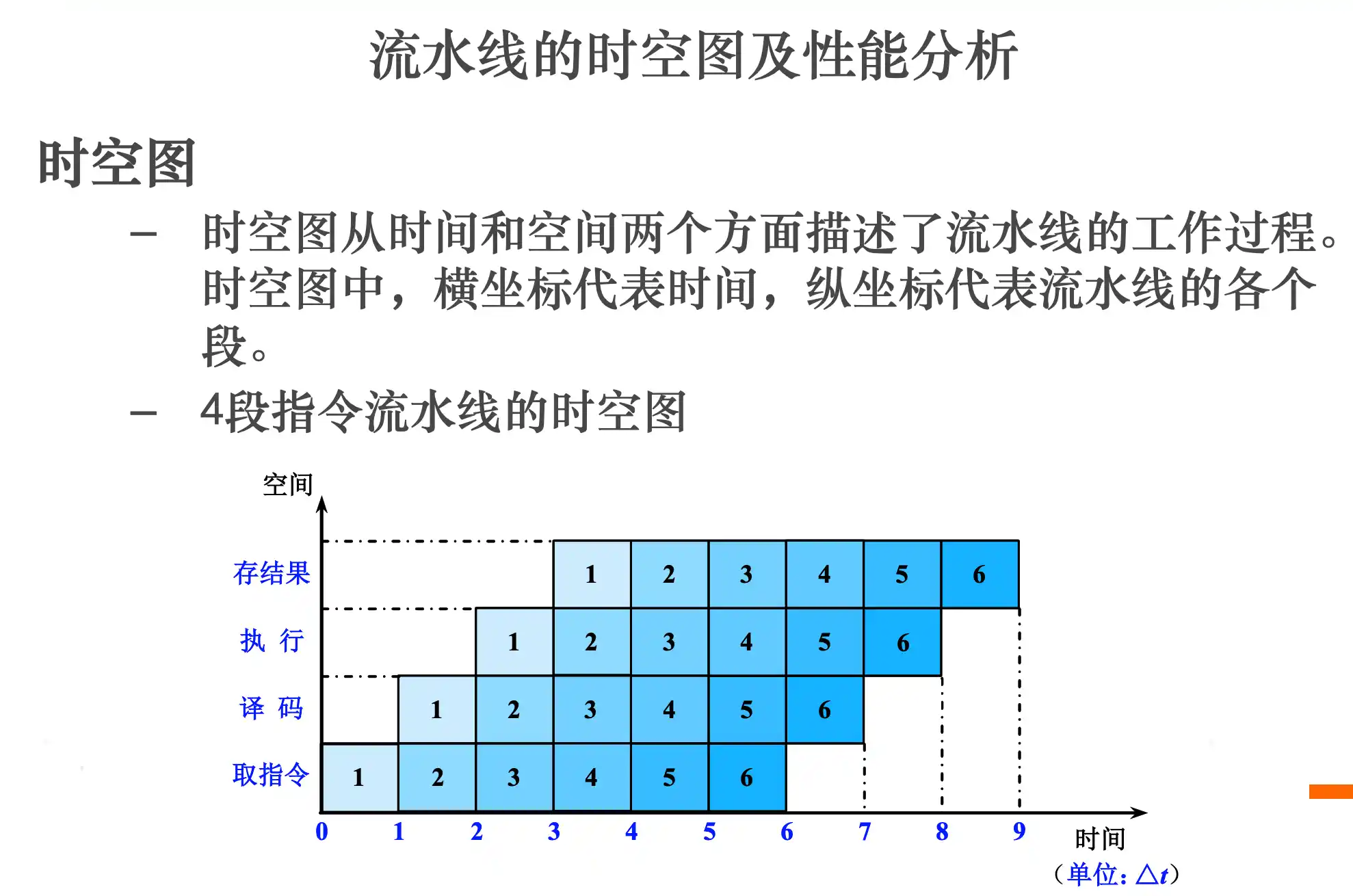
流水线的时空图及性能指标计算



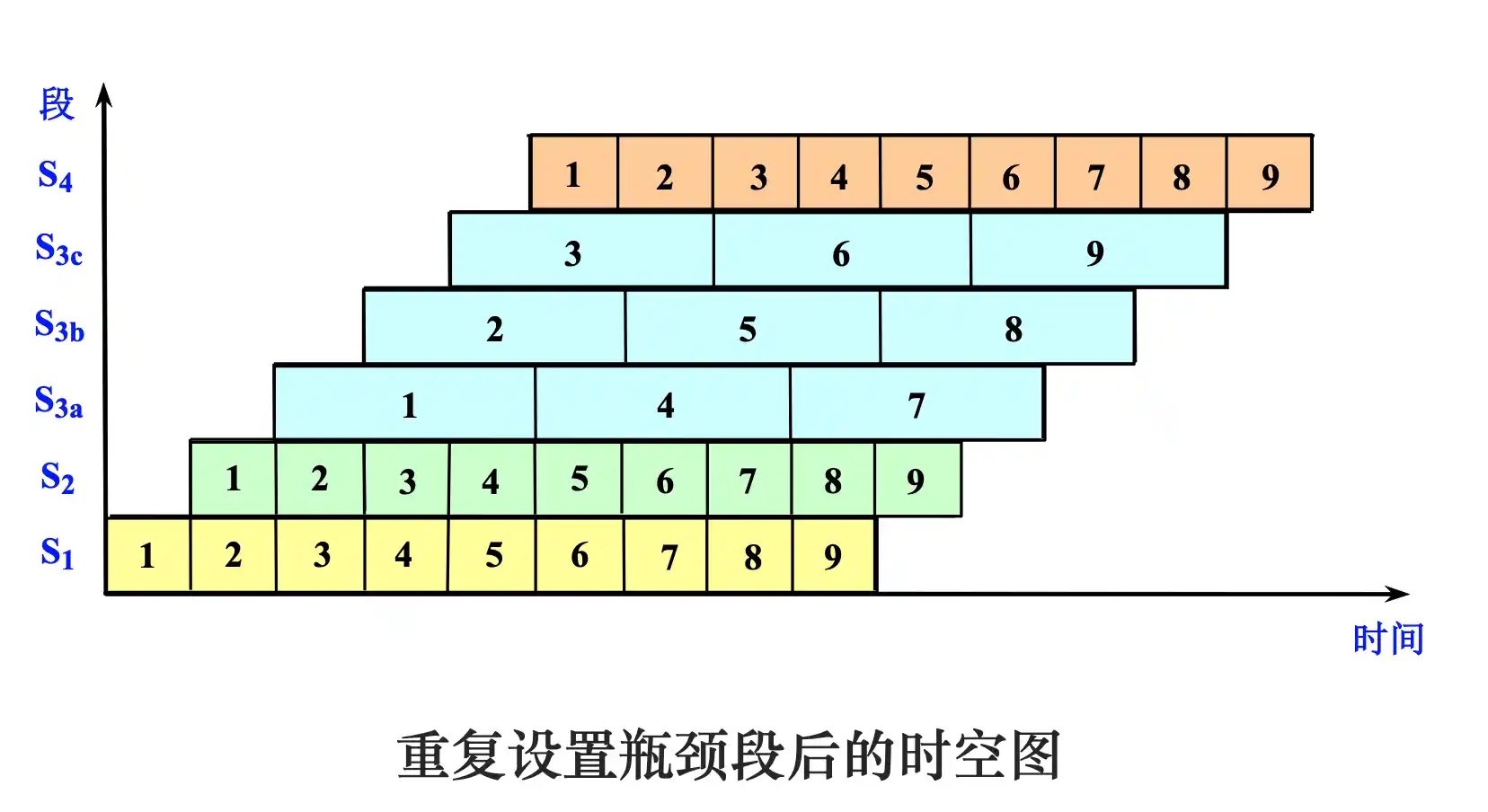



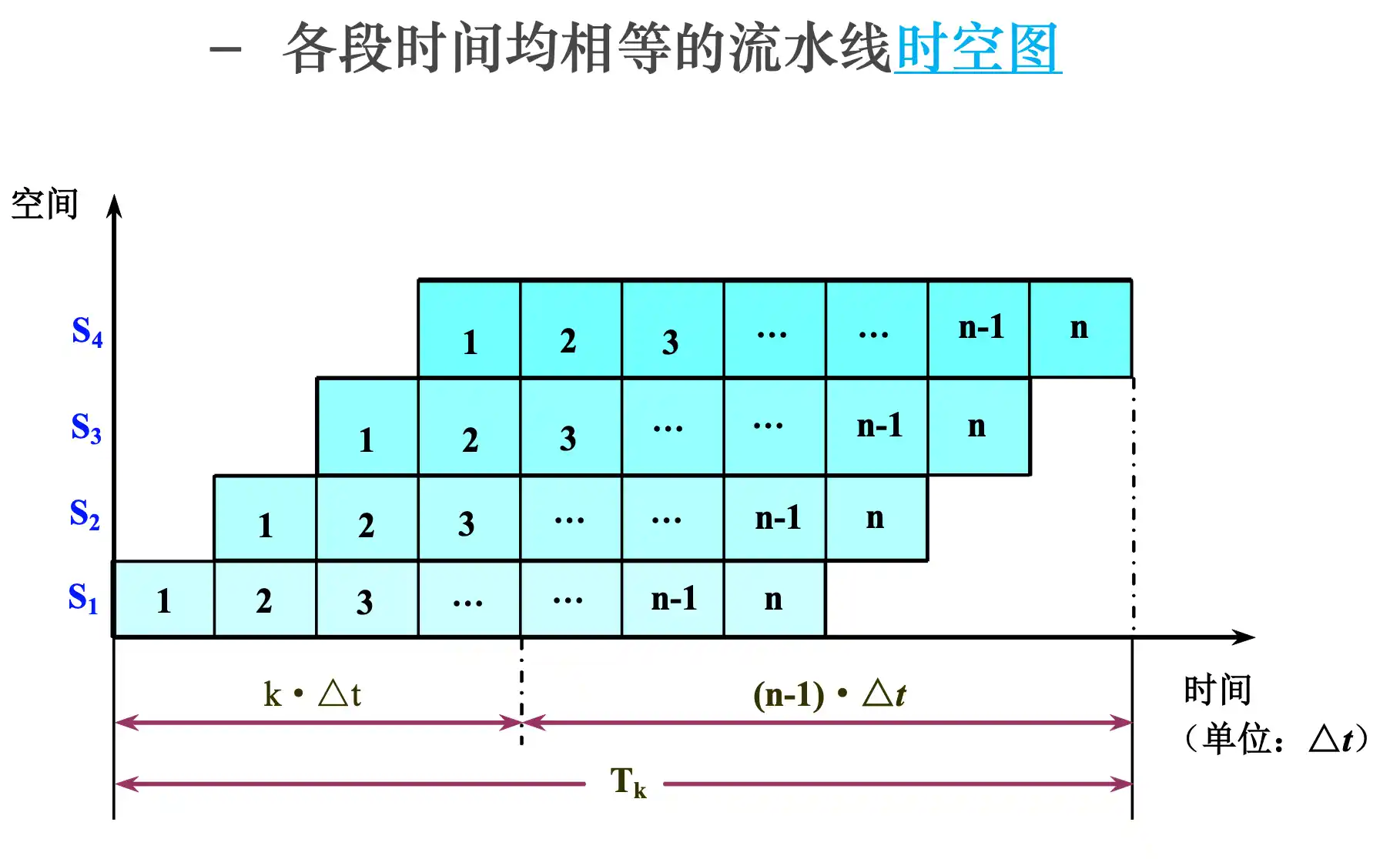

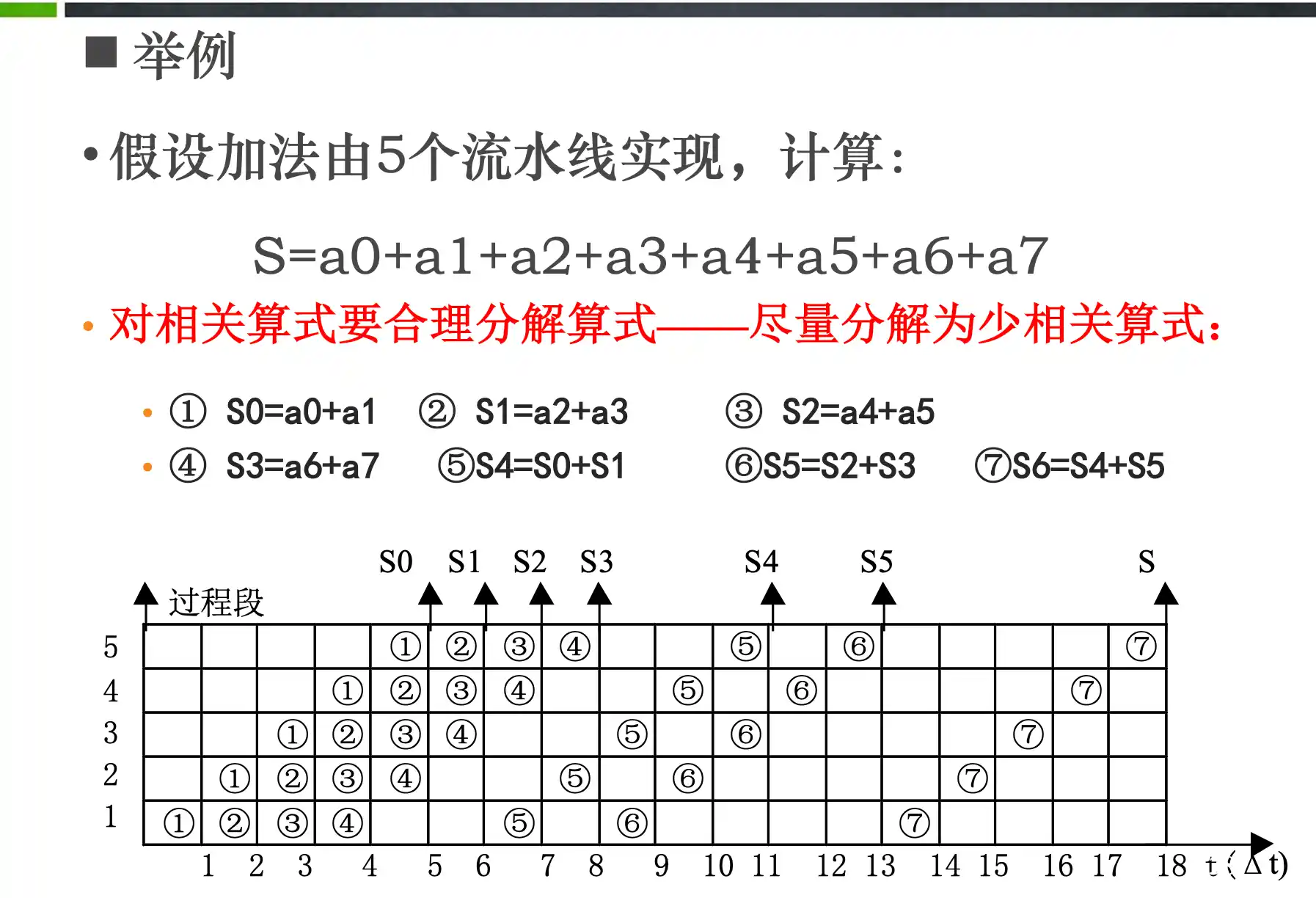
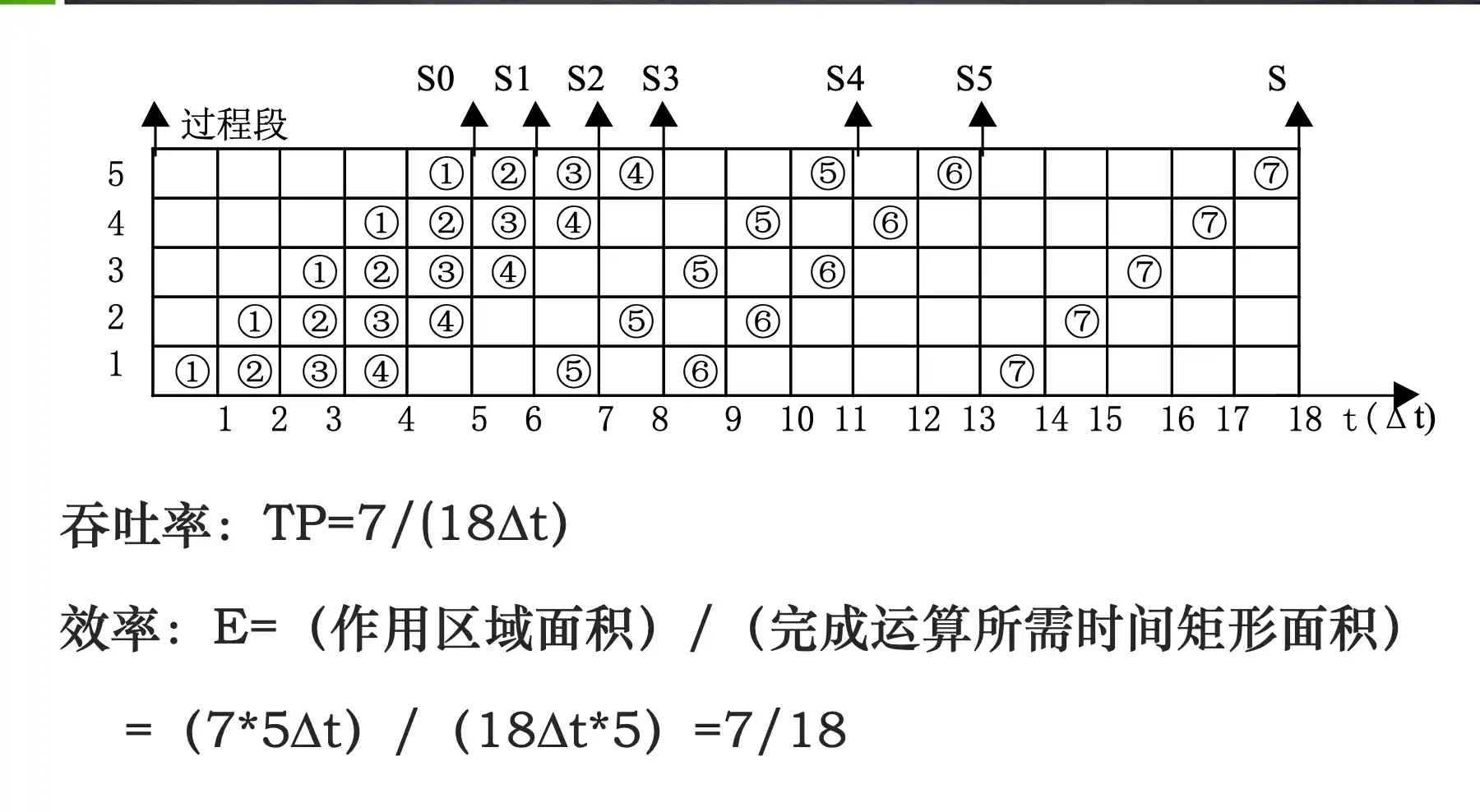


add, sub, addi, or, ori, lw, sw, beq每条指令在5级流水线的执行过程
结构冒险、数据冒险和控制冒险的判断,以及需要暂停的时钟周期数的判断(控制冒险的解决性能依赖于分支地址计算阶段和分支条件判断阶段)

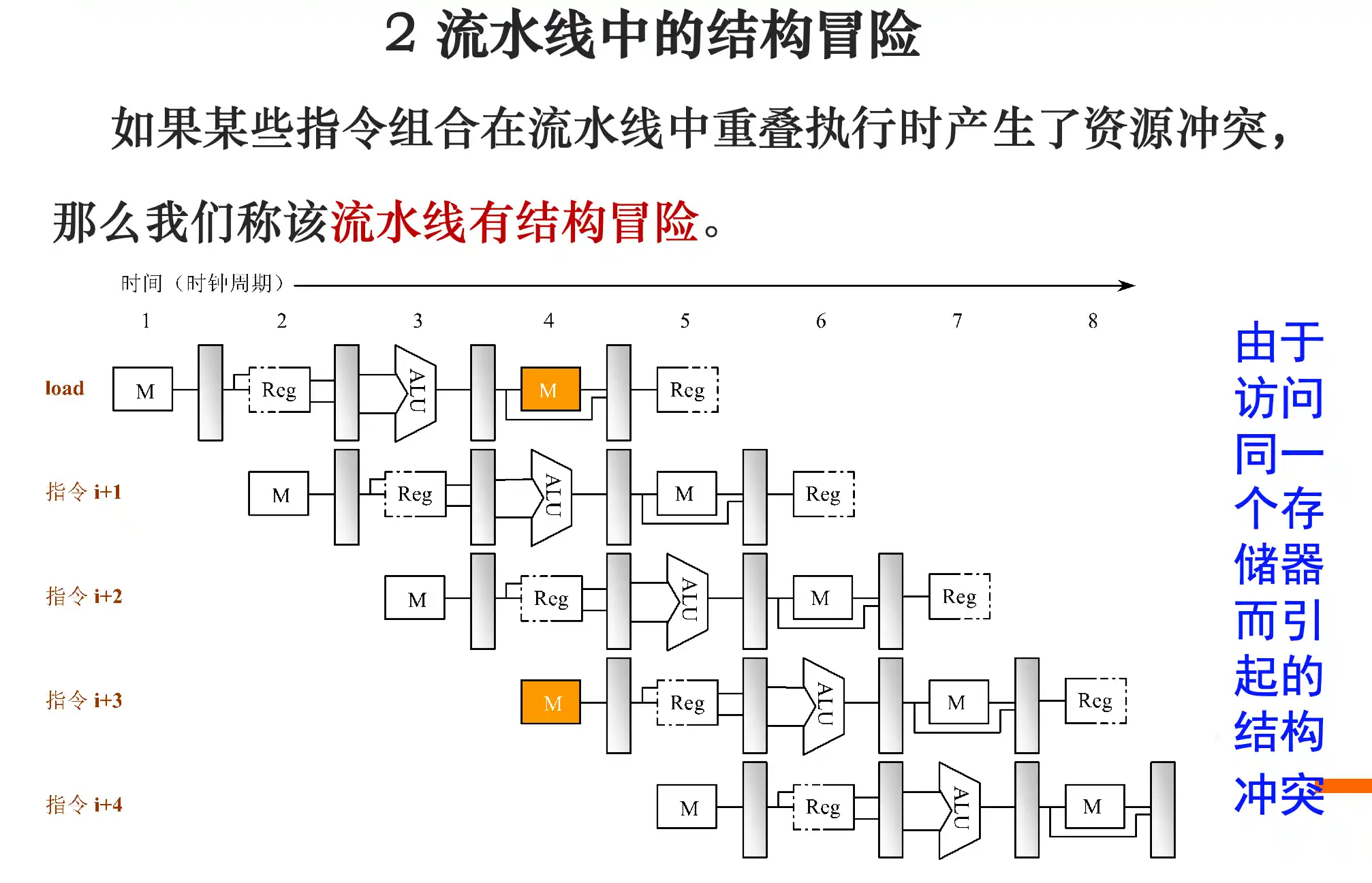
结构冒险以及三个解决办法
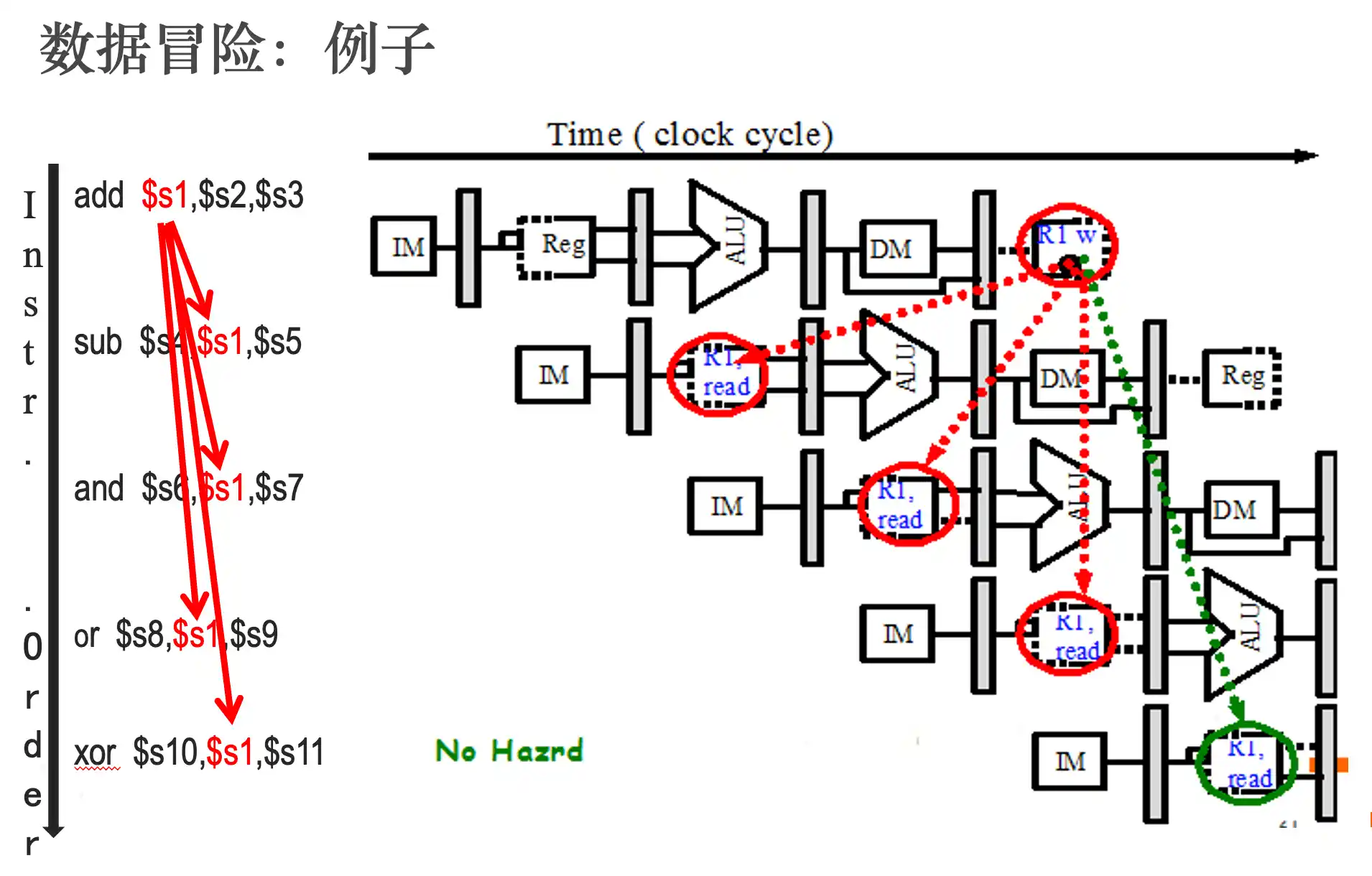
数据冒险以及解决办法
数据冒险指的是 写后读 RAW




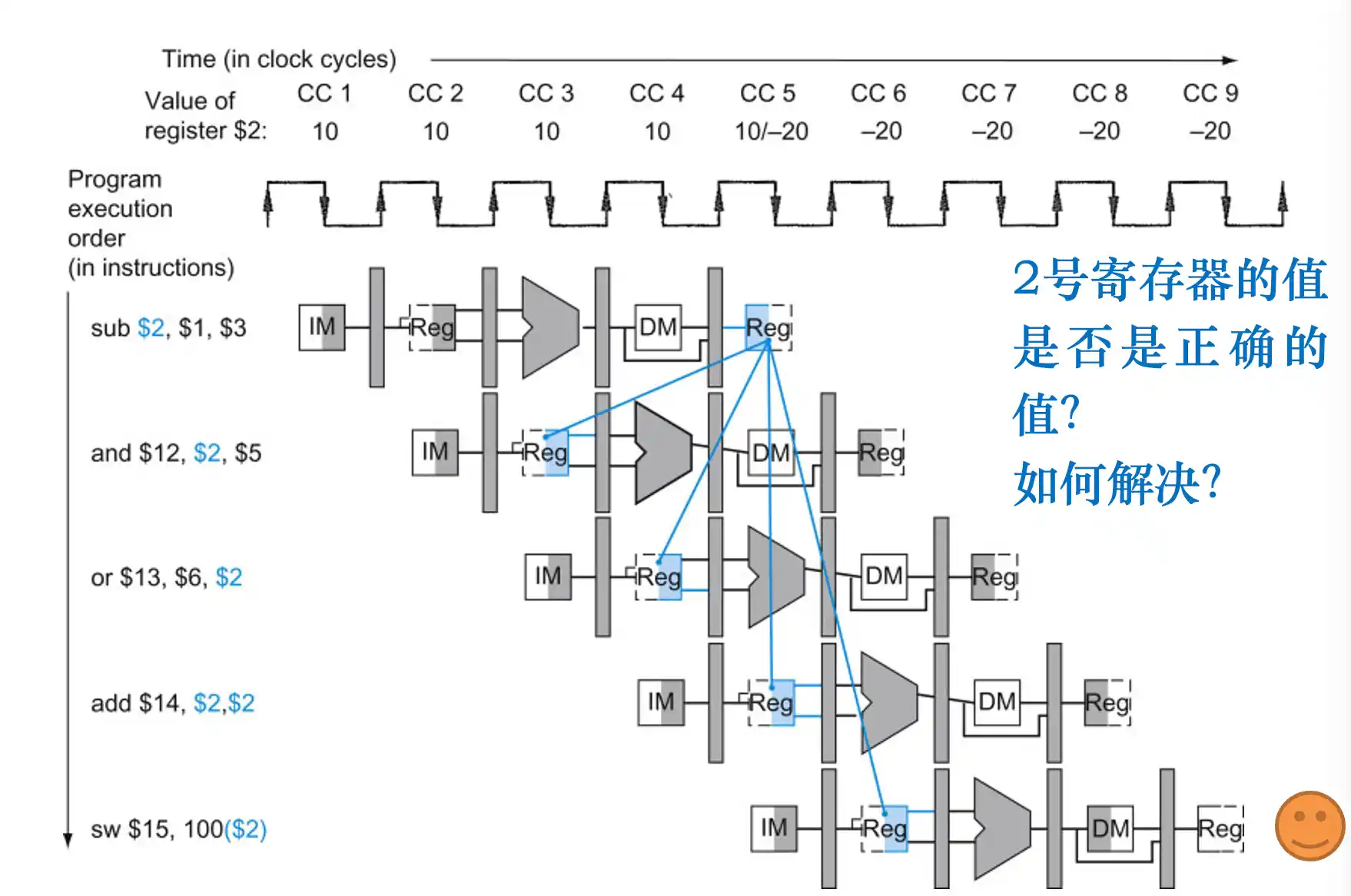
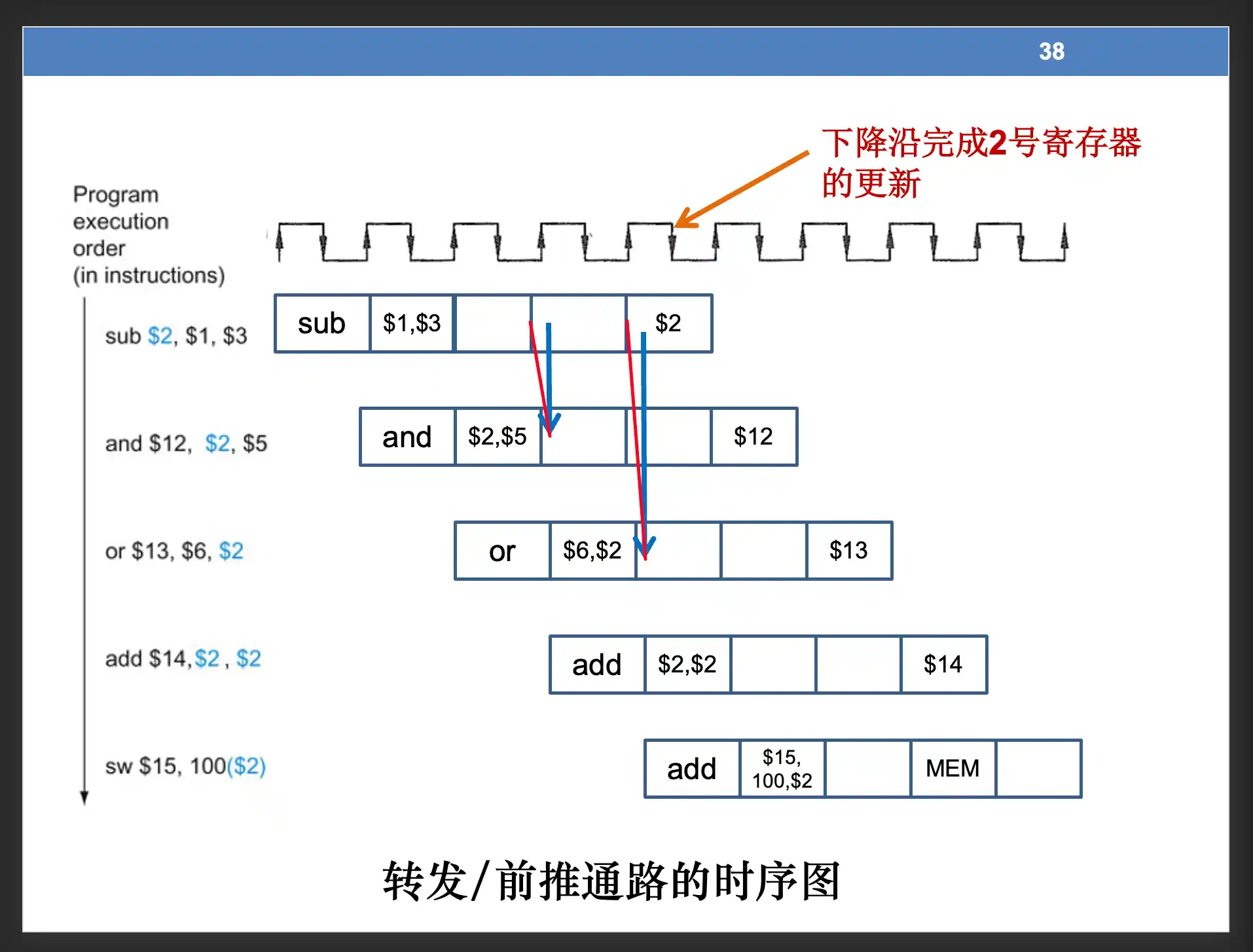
办法2:数据前推
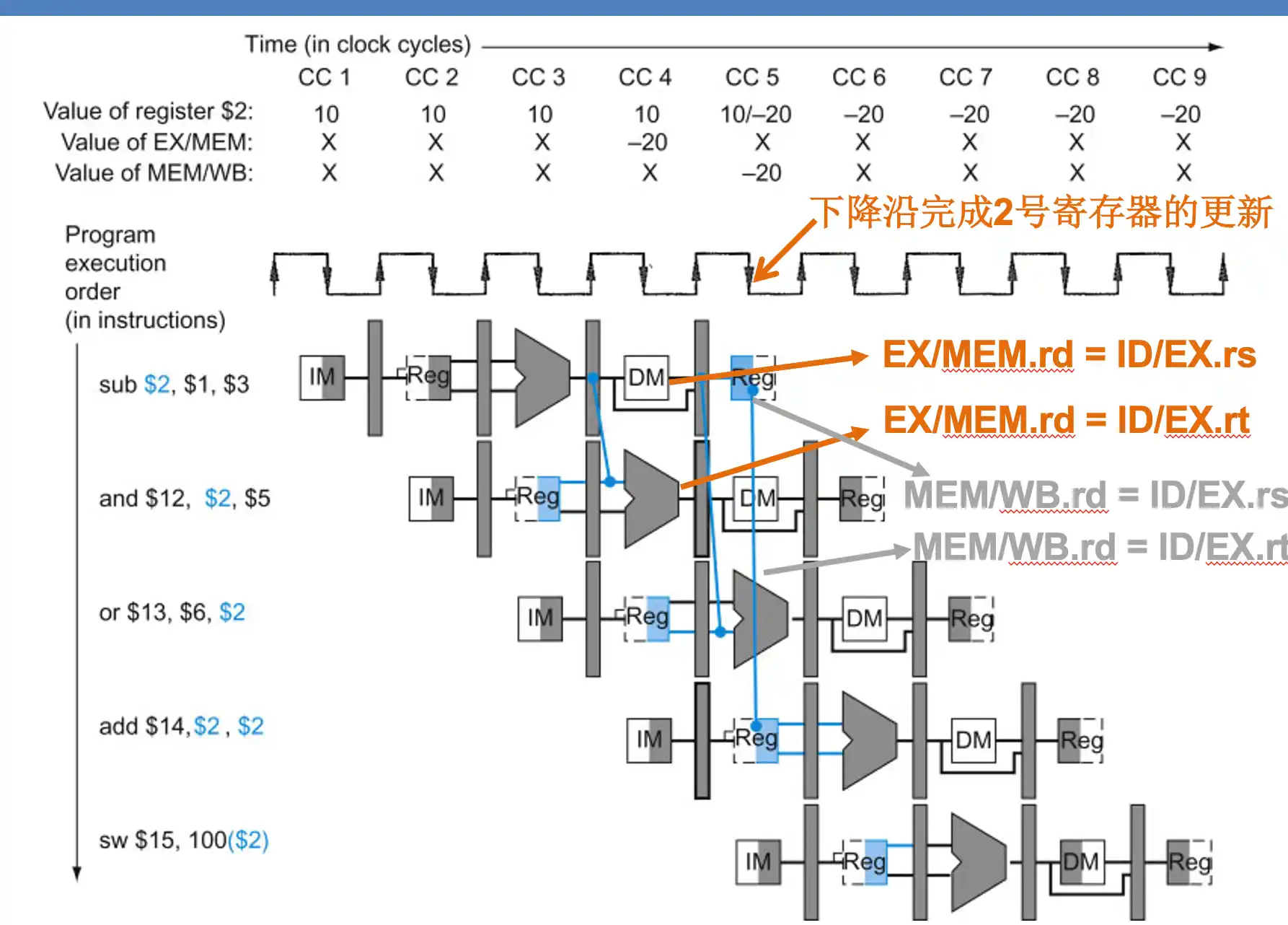
注意是 从 流水线寄存器 中取出数据到操作数中
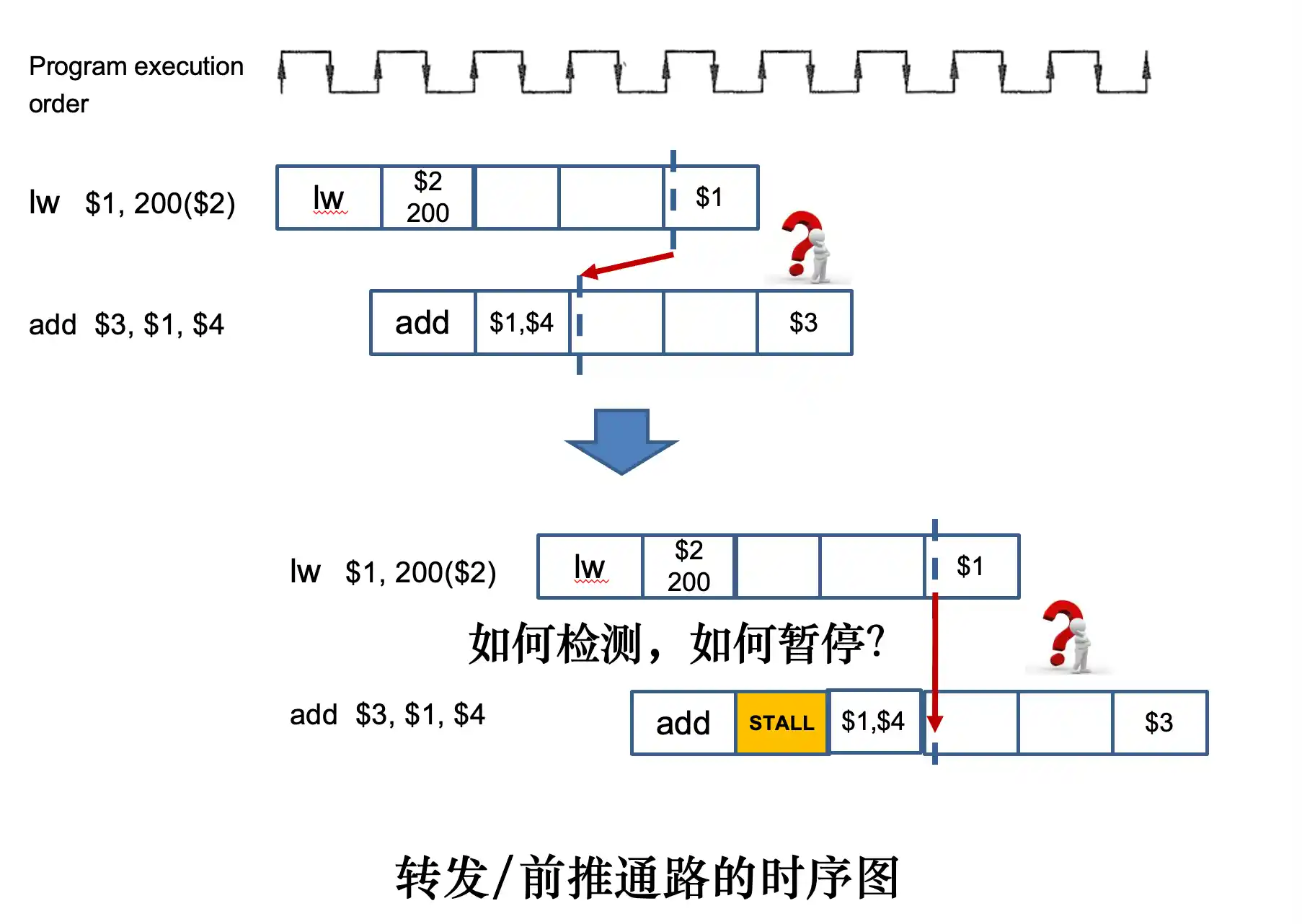
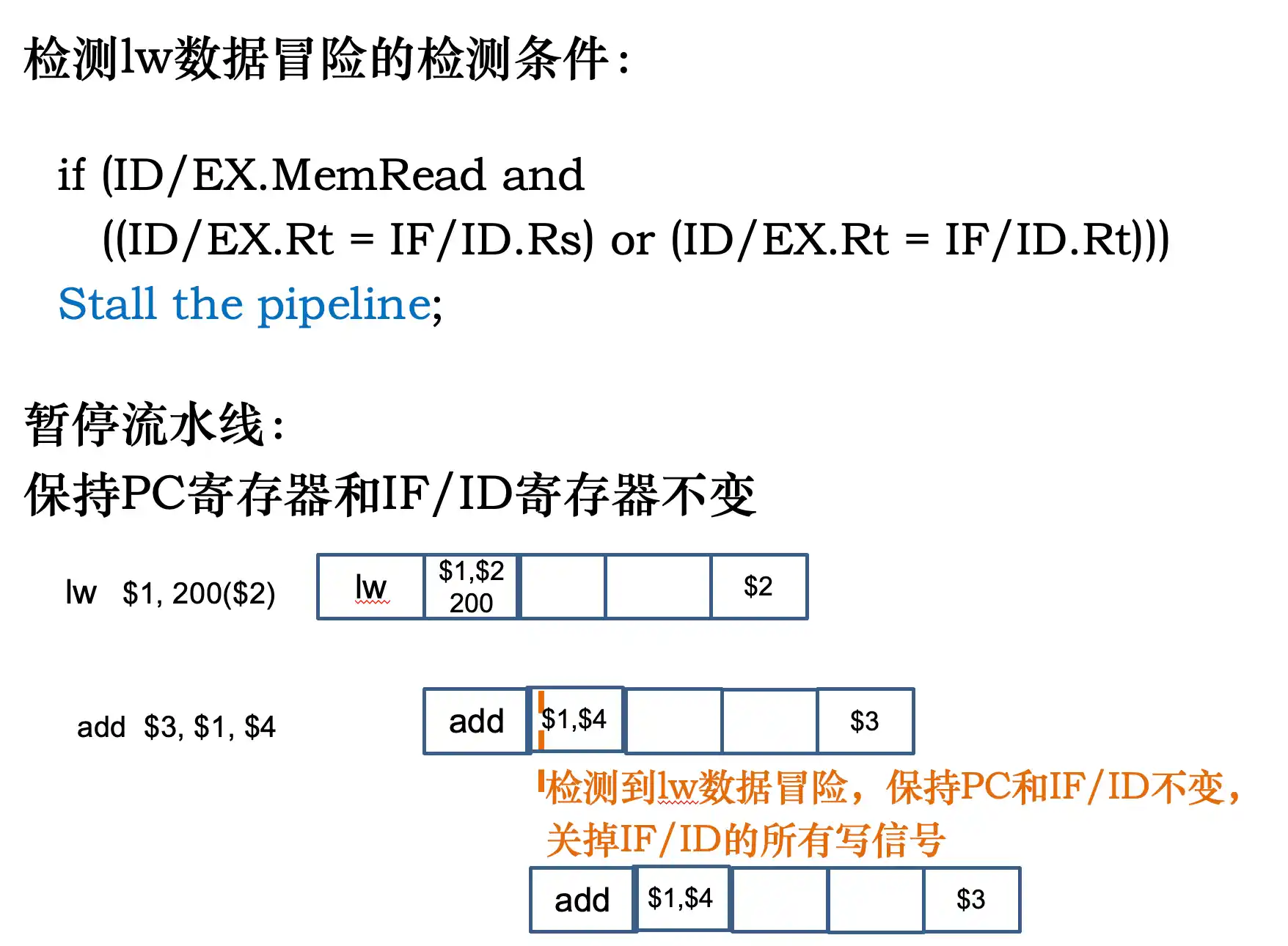
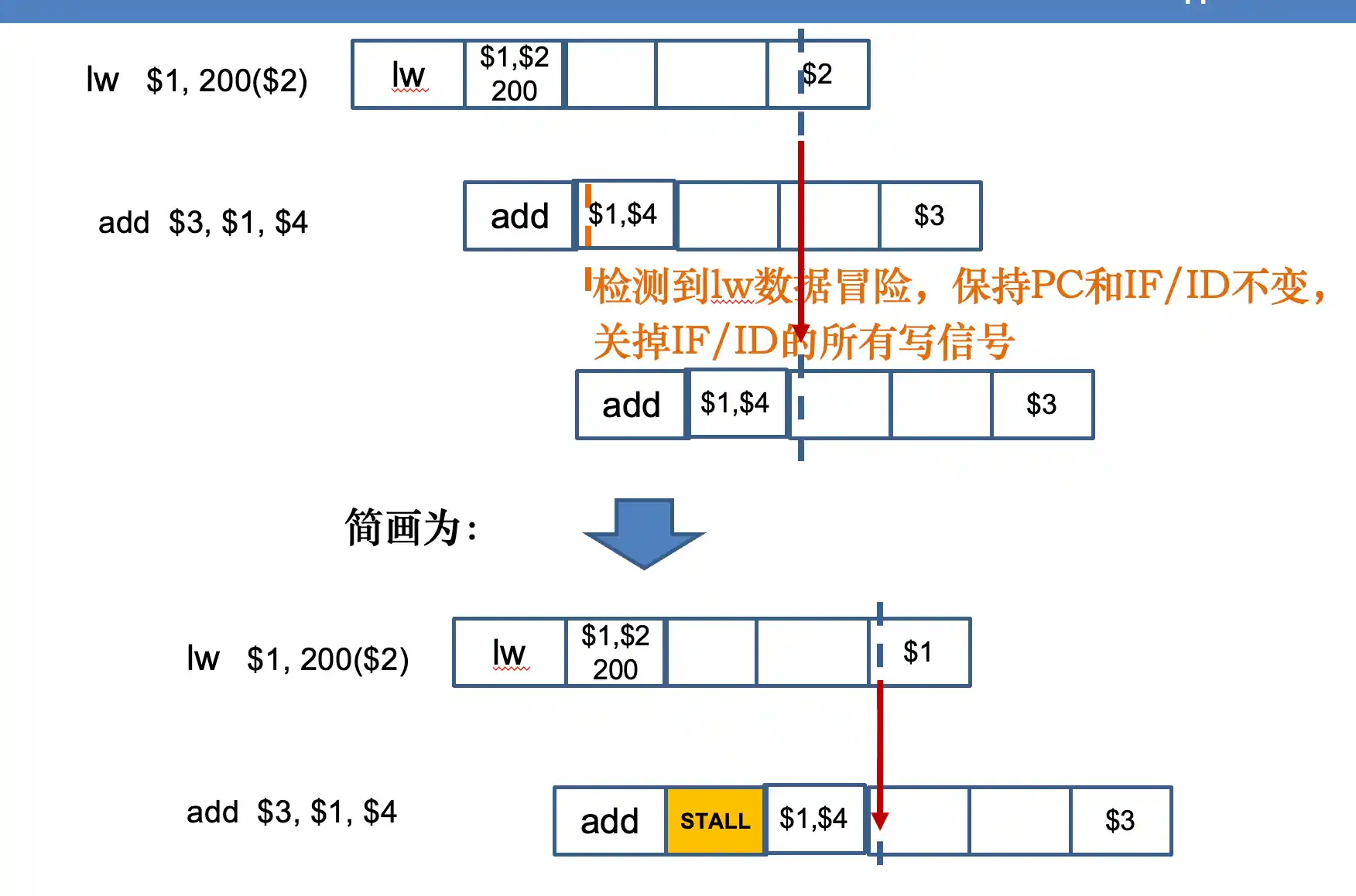
对于 lw 。。 op 。。 这种数据冒险,由于lw在 MEM阶段过后 结果才存在在流水线寄存器中
所以要对下面的在IF ID中进行stall 暂停流水线:保持PC寄存器和IF/ID寄存器不变
控制冒险以及解决办法








如果add在alu中 mem阶段过后 pc在得到正确的下一个指令地址
在ID及计算转移地址

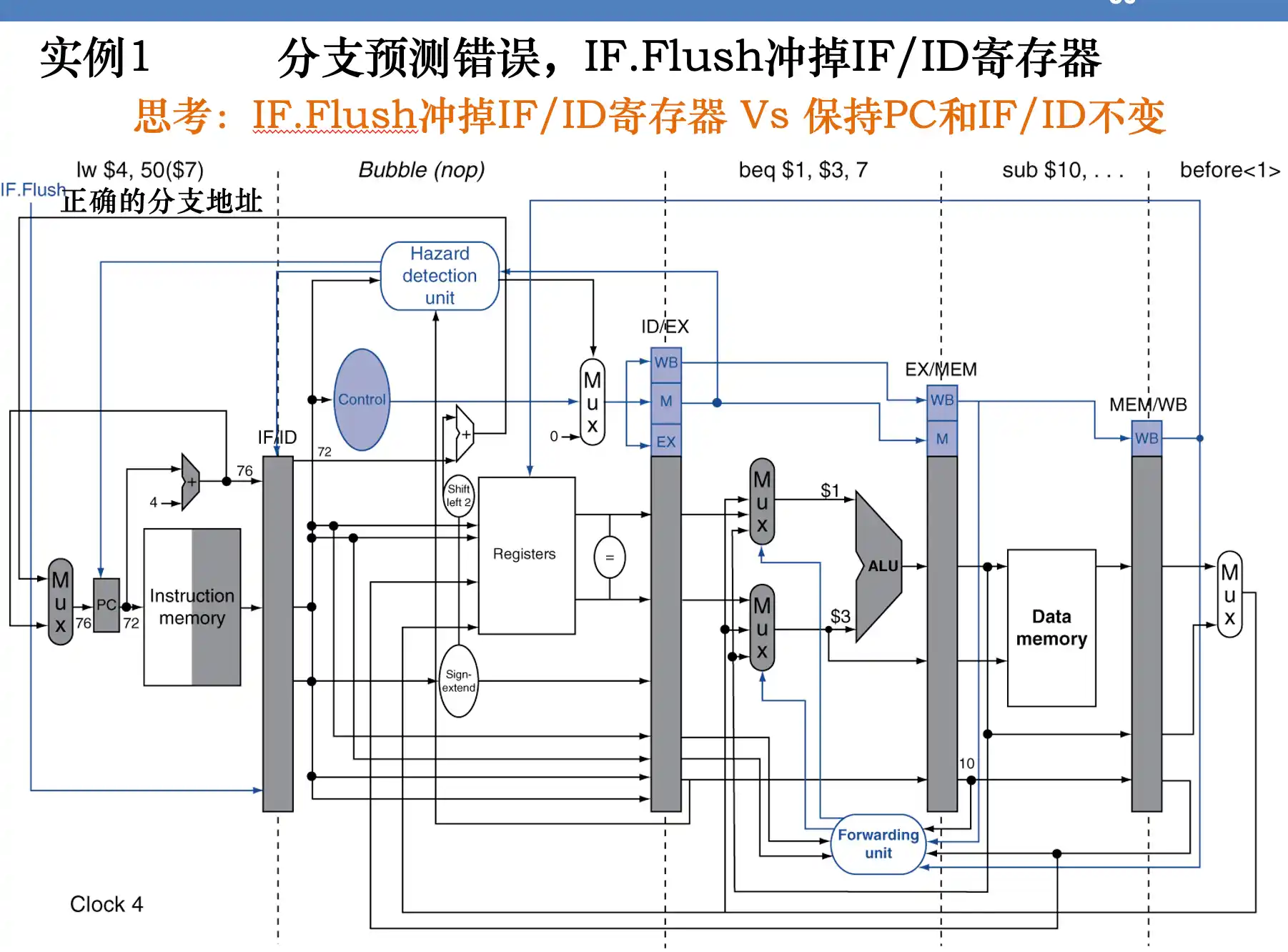
如果分支预测错误就flush ID/EXE寄存器 ,即把转移指令的下一个指令转为NOP 空指令。
flush
指令编码变全0:流水线定义编码为全0的指令为nop指令,语义:什么工作都不做。 IF.Flush有效,则将该指令在打入IF/ID寄存器时变为nop指令。
指令编码不变:将该指令的所有写信号全部关闭。
结构冒险、数据冒险和控制冒险的解决办法
stall理解为关闭要等待指令的写信号
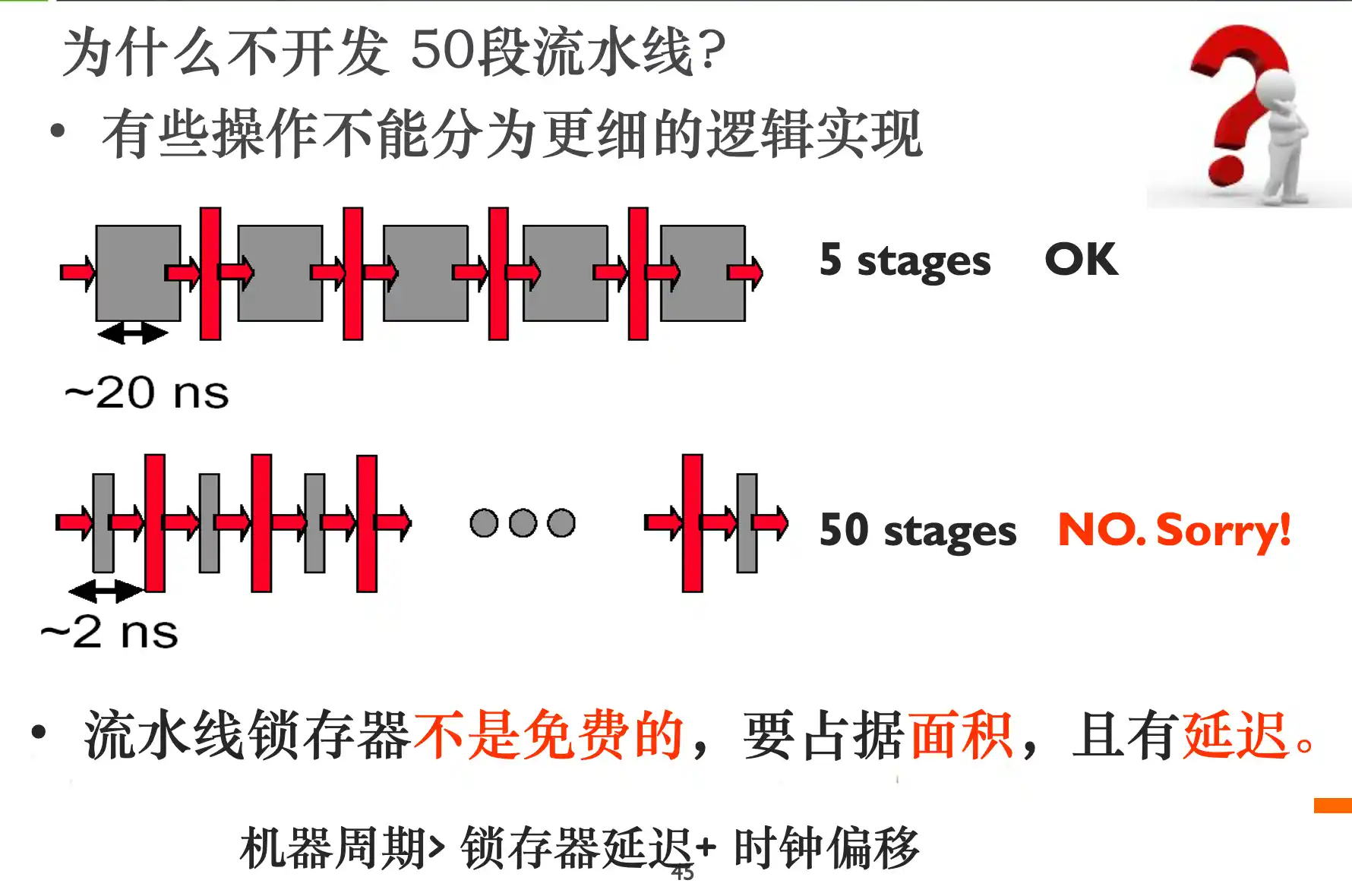
结构冒险:
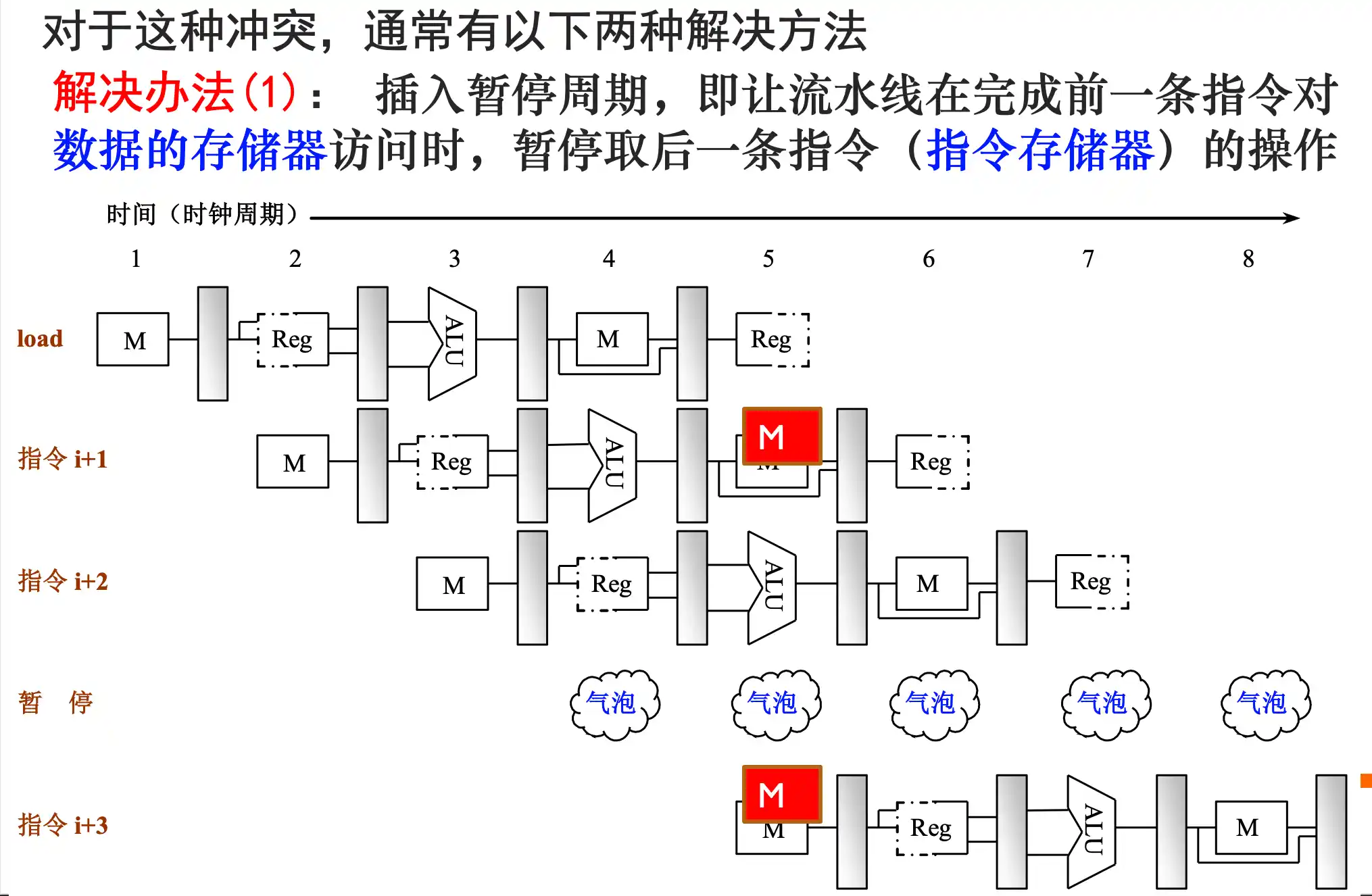
1. 插入暂停周期,即让流水线在完成前一条指令对数据的存储器访问时,暂停取后一条指令(指令存储器)的操作
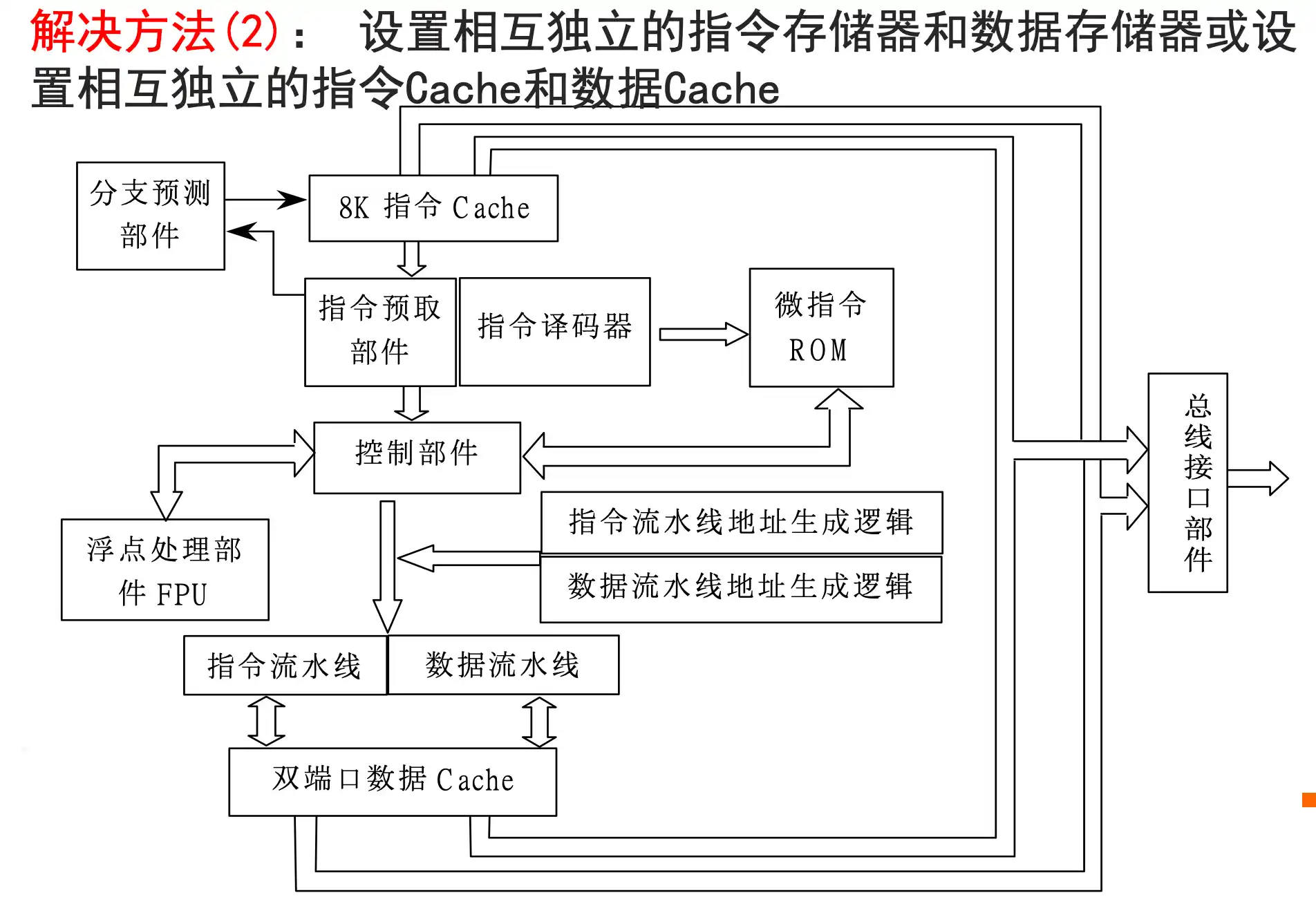
2. 设置相互独立的指令存储器和数据存储器或设置相互独立的指令Cache和数据Cache
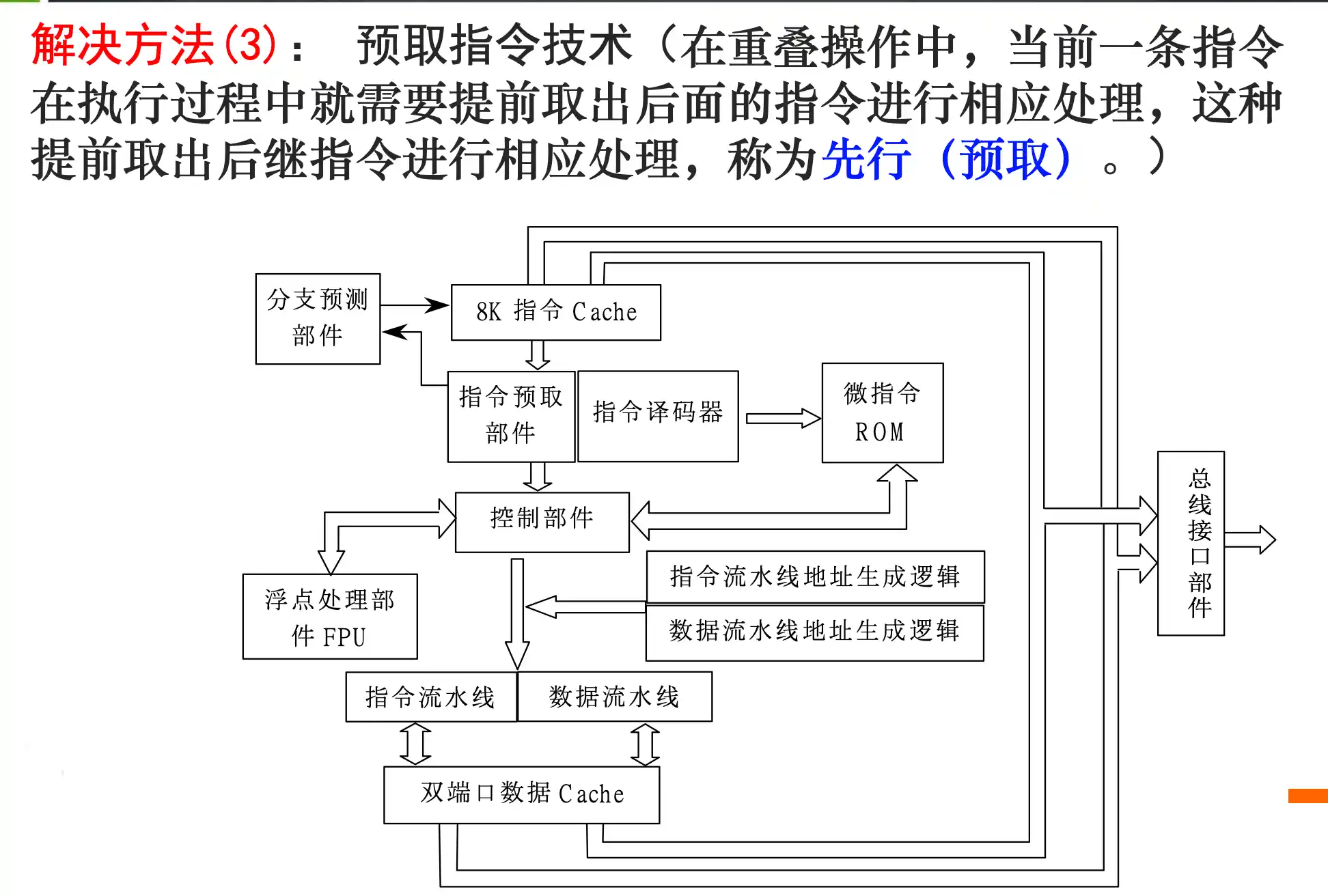
3. 预取指令技术(在重叠操作中,当前一条指令在执行过程中就需要提前取出后面的指令进行相应处理,这种提前取出后继指令进行相应处理,称为先行(预取)。)
数据冒险:
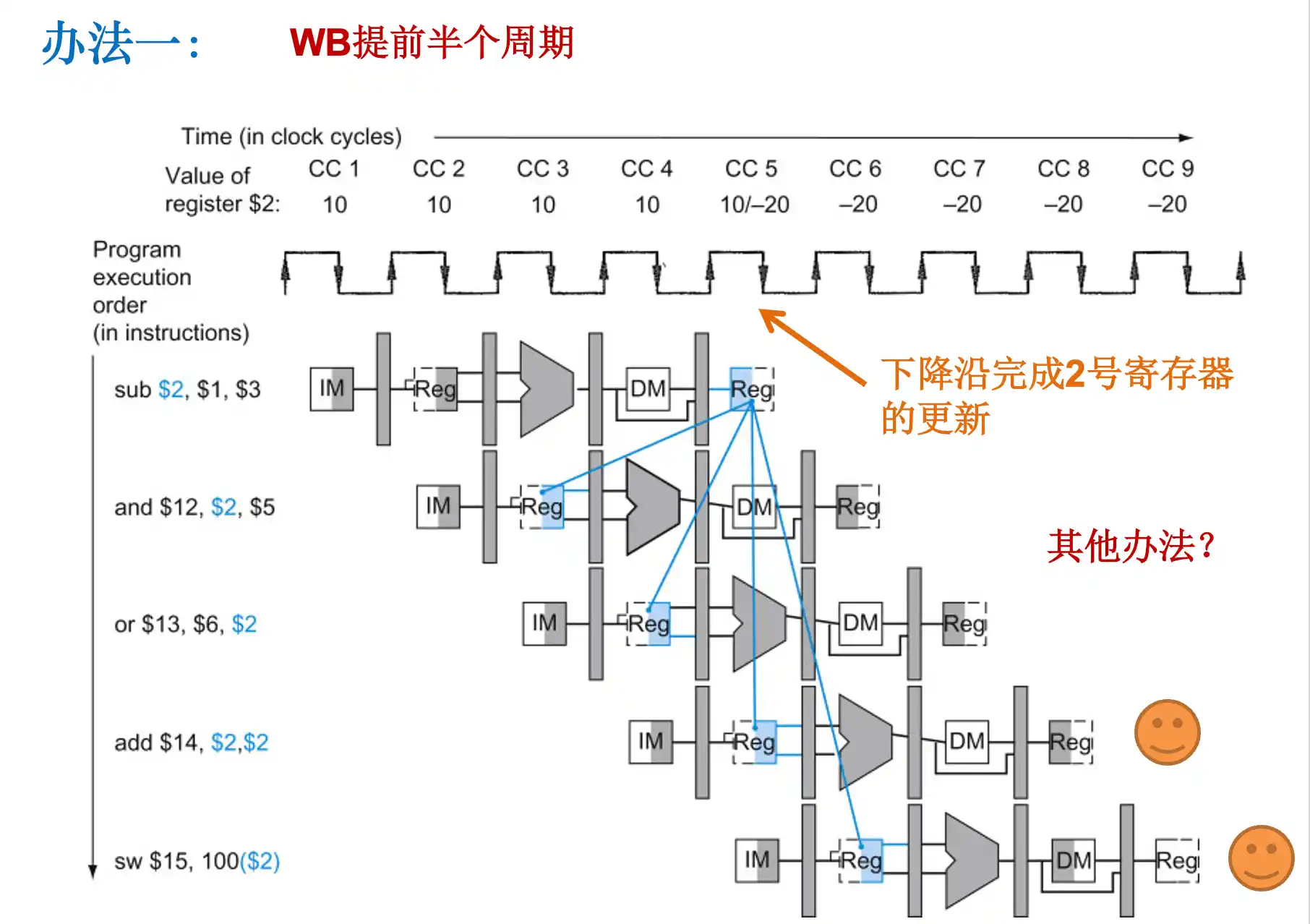
1. 写回WB操作提前半个周期
2. 数据前推:如果发现与结下来的1、2条指令存在数据冒险。从流水线寄存器中拿出 数据到冲突的指令操作数。 由于要检测两个位置,每个ALU输入需要一个 四路复选。
- 对于 lw 。。 op 。。 这种数据冒险,由于lw在 MEM阶段过后 结果才存在在流水线寄存器中
所以要对下面的在IF ID中进行stall 暂停流水线:保持PC寄存器和IF/ID寄存器不变
控制冒险:
1. 转移Stalls ,但会造成大的性能损失
2. 改进分支预测技术
- 静态预测:例如总是预测分支不发生(即假设分支不发生,属于静态预测机制)(成功率在50%左右)。
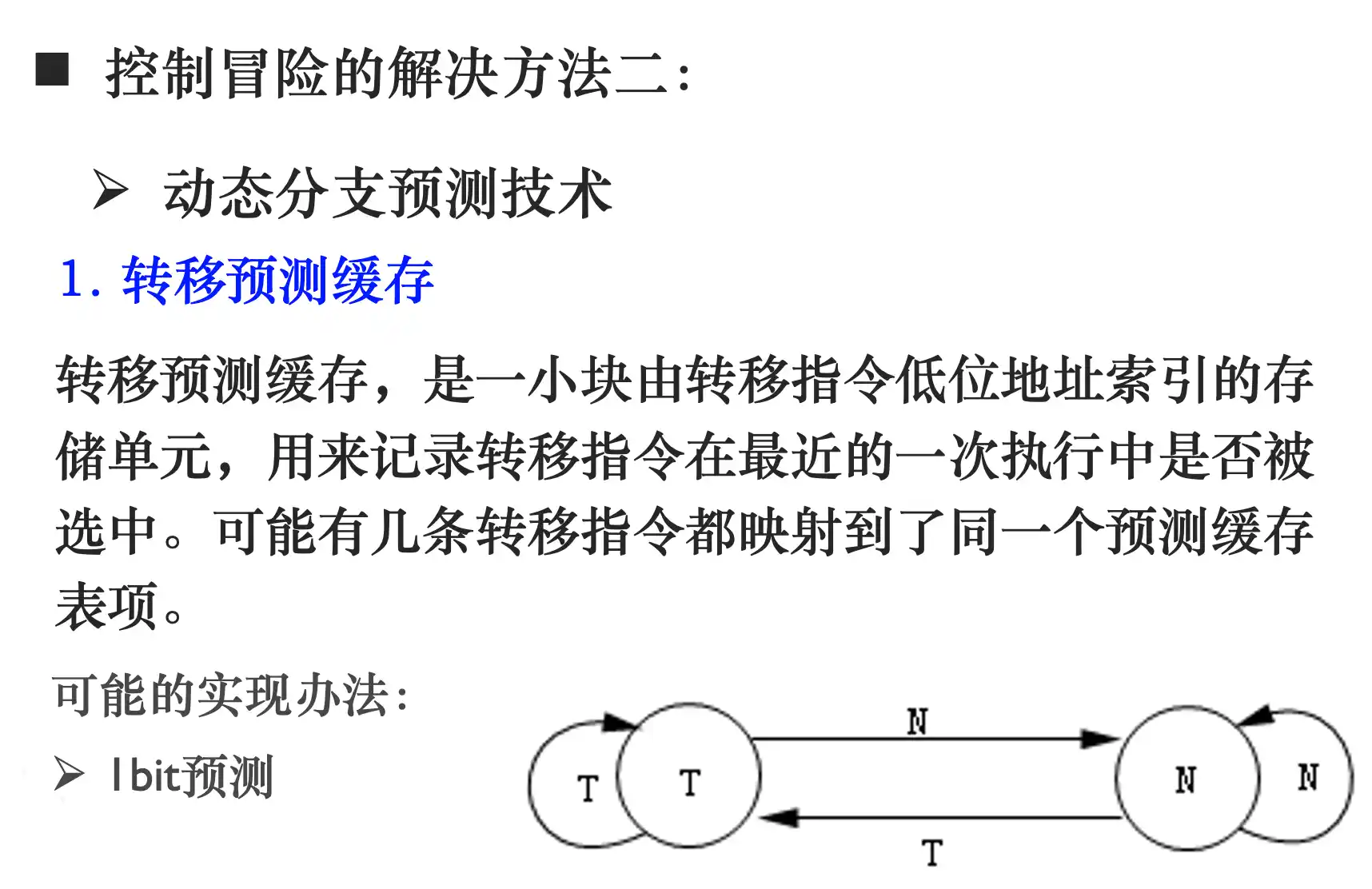
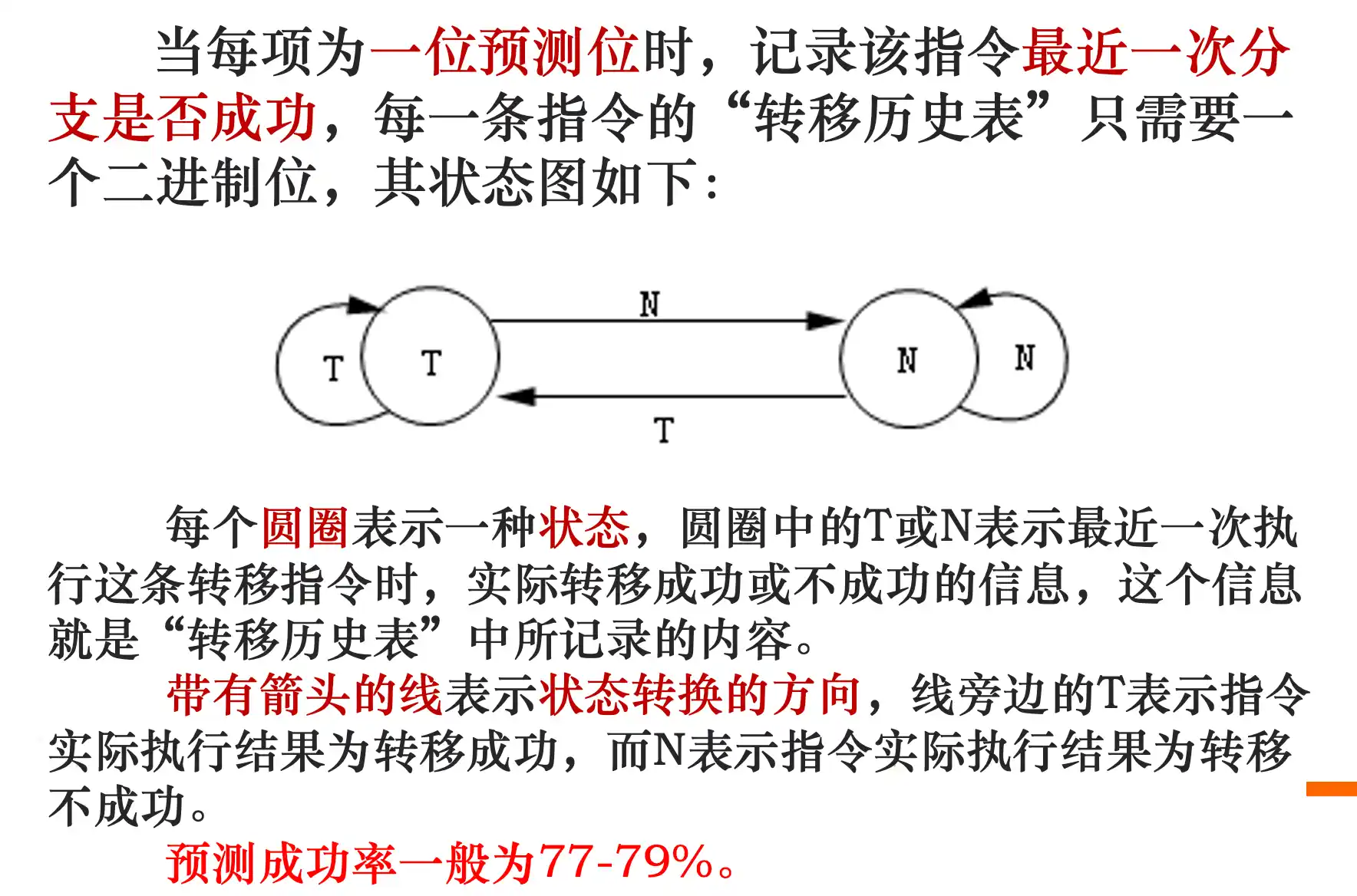
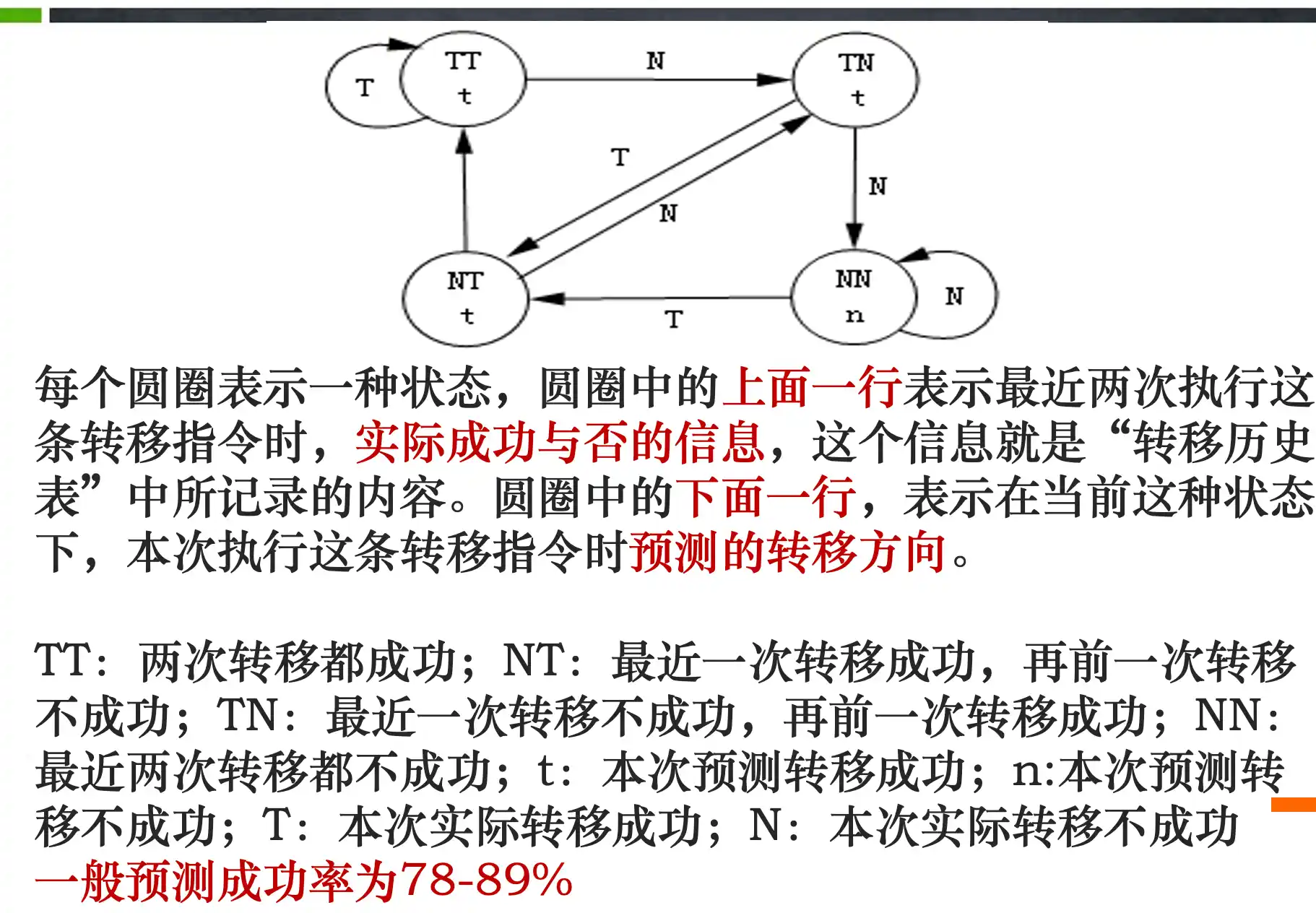
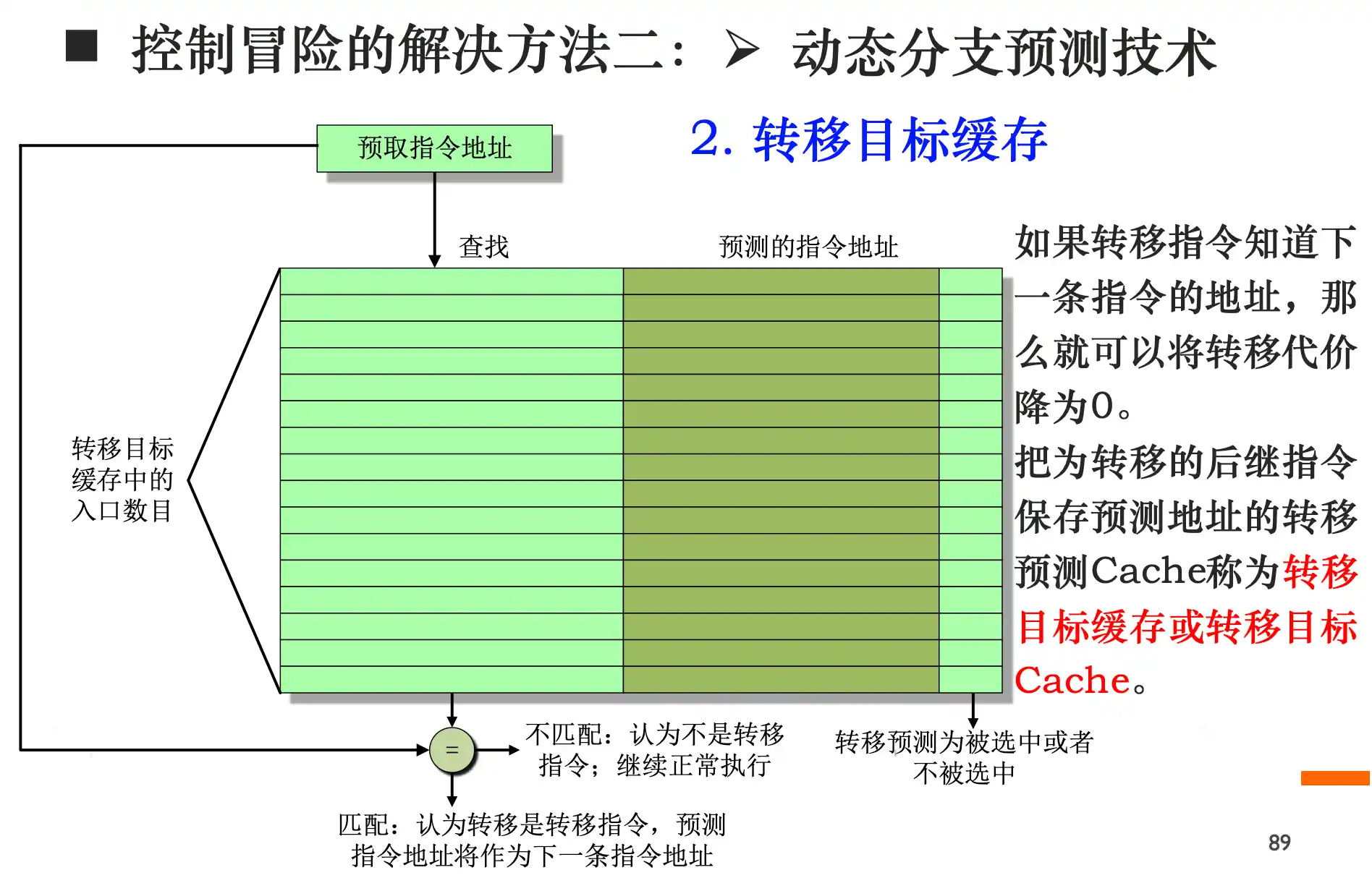
- 动态预测: 转移预测缓存 1位或者2位 或者 转移目标缓存(把为转移的后继指令保存预测地址的转移预测Cache称为转移目标缓存或转移目标Cache。)
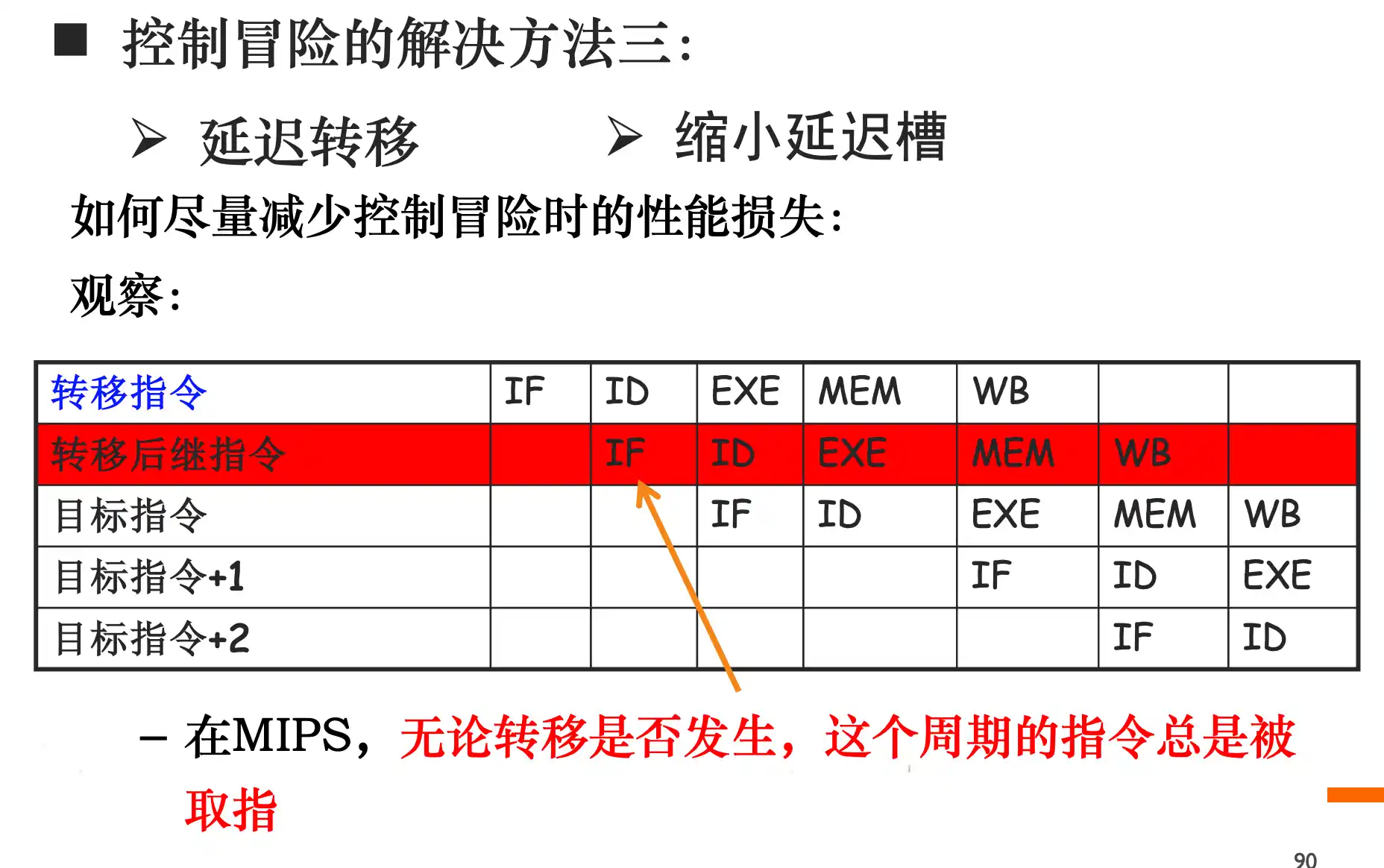
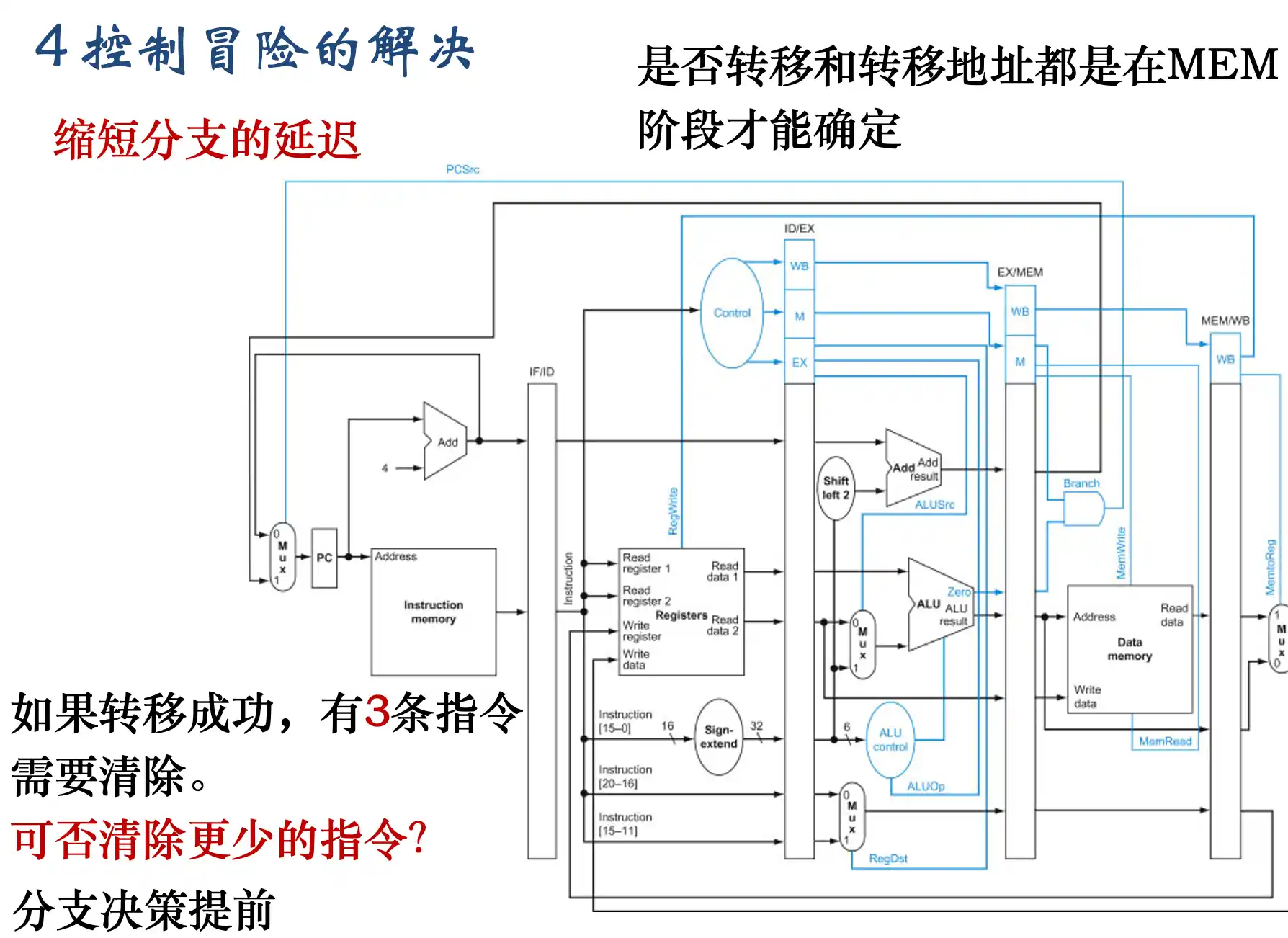
3. 延迟转移、缩小延迟槽:延迟转移是指在转移指令后顺序执行一条无关的指令,然后再进行转移。缩小延迟槽是尽早计算出转移目标地址,例如EXE阶段的ADD移动到 ID阶段
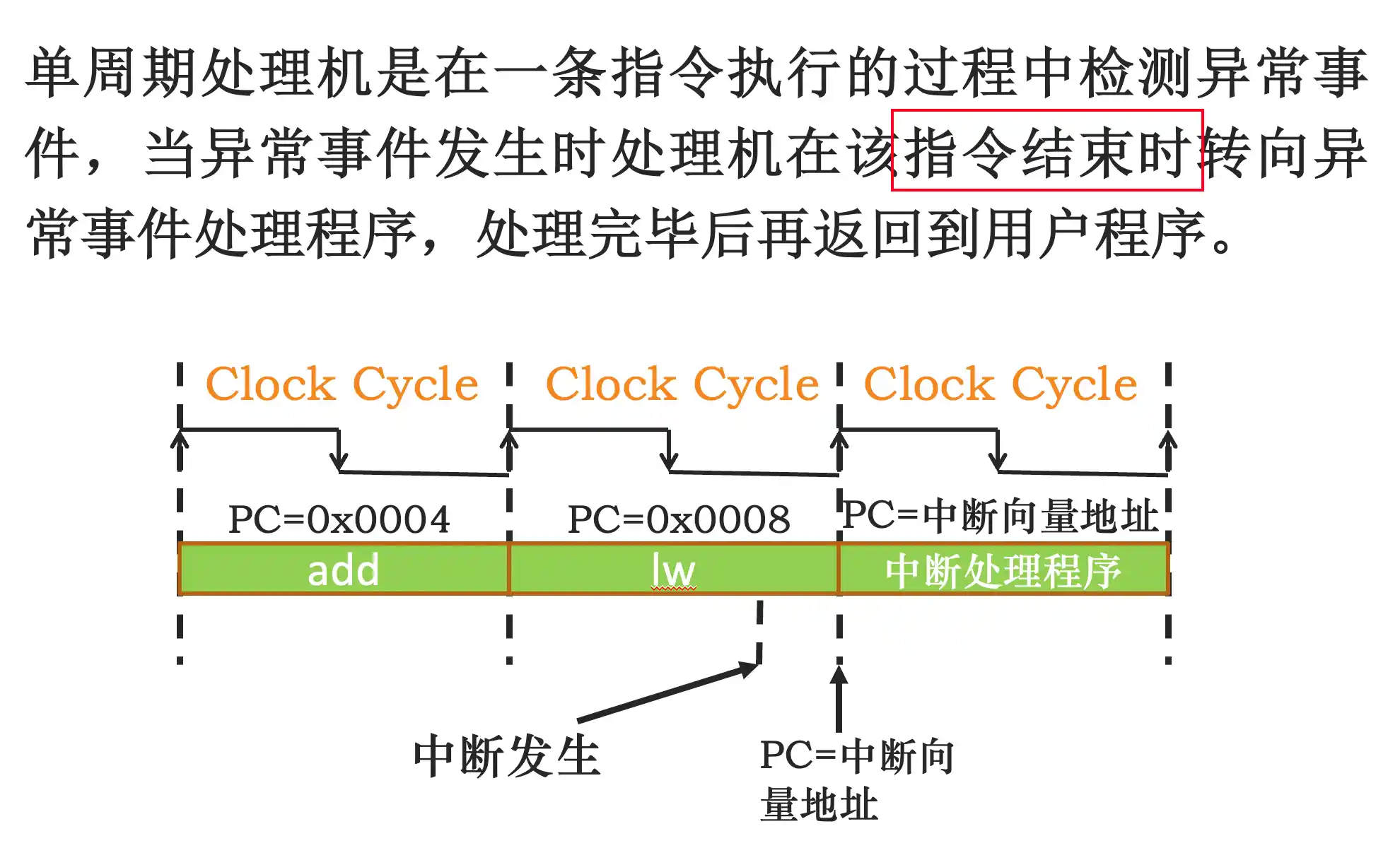
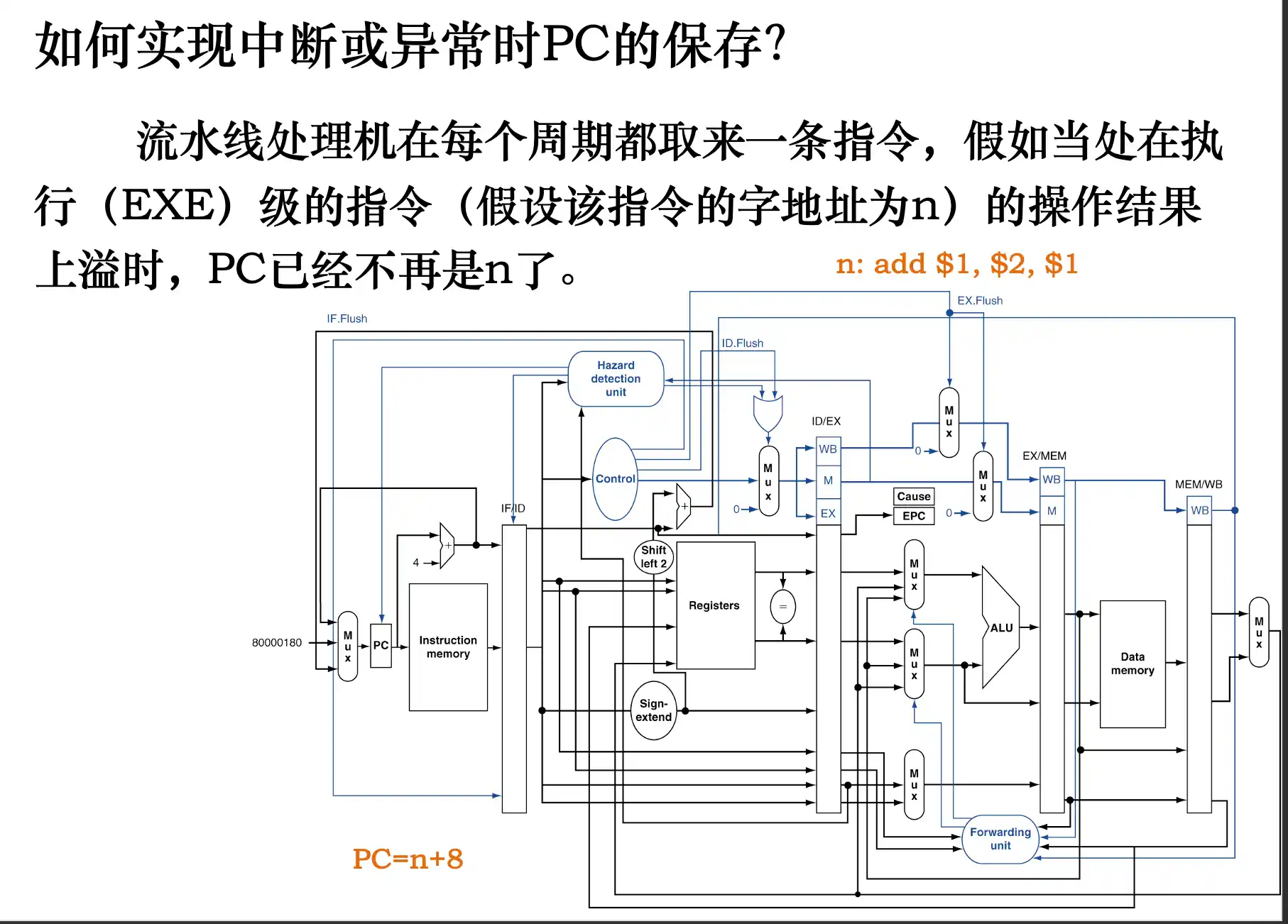
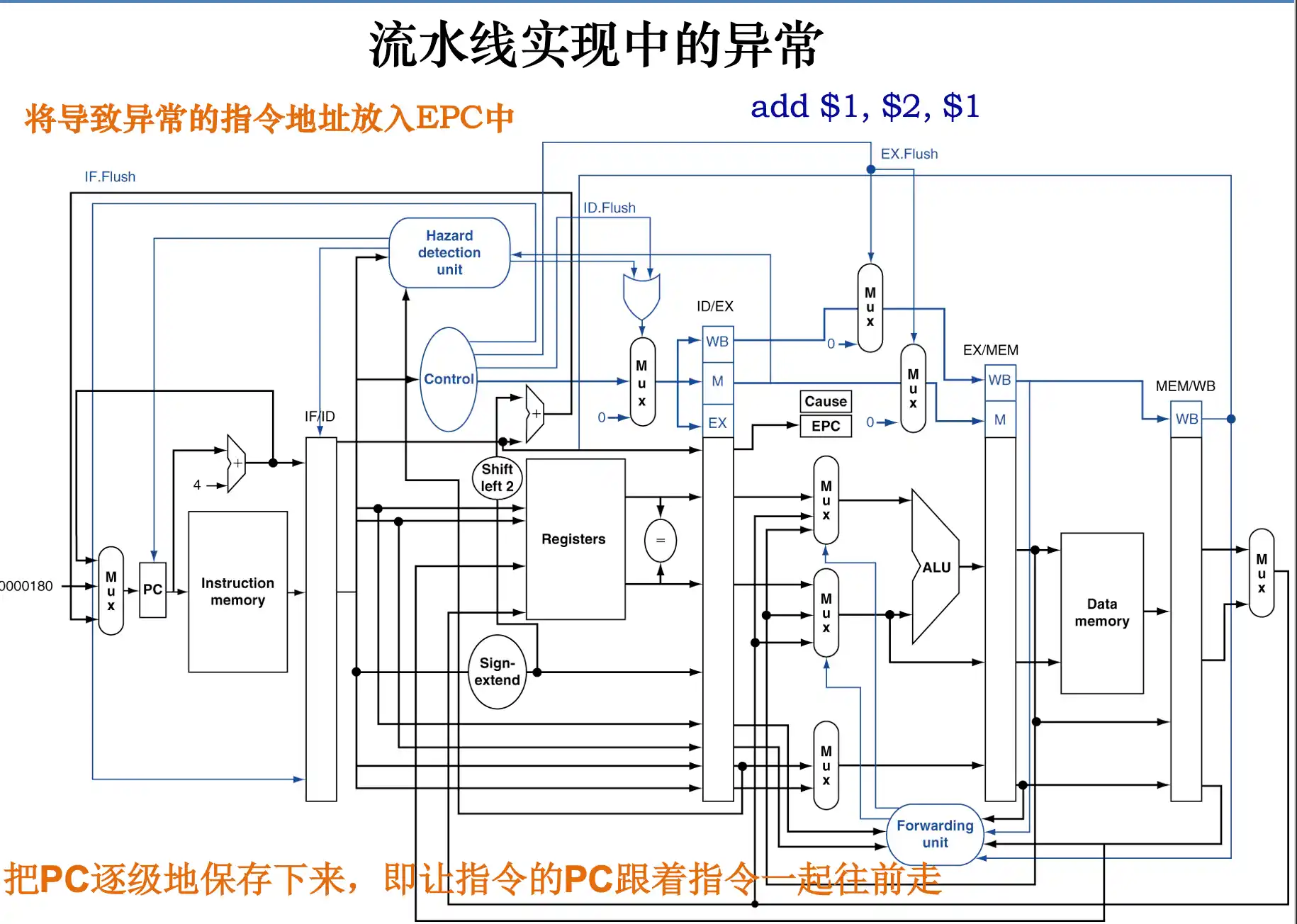
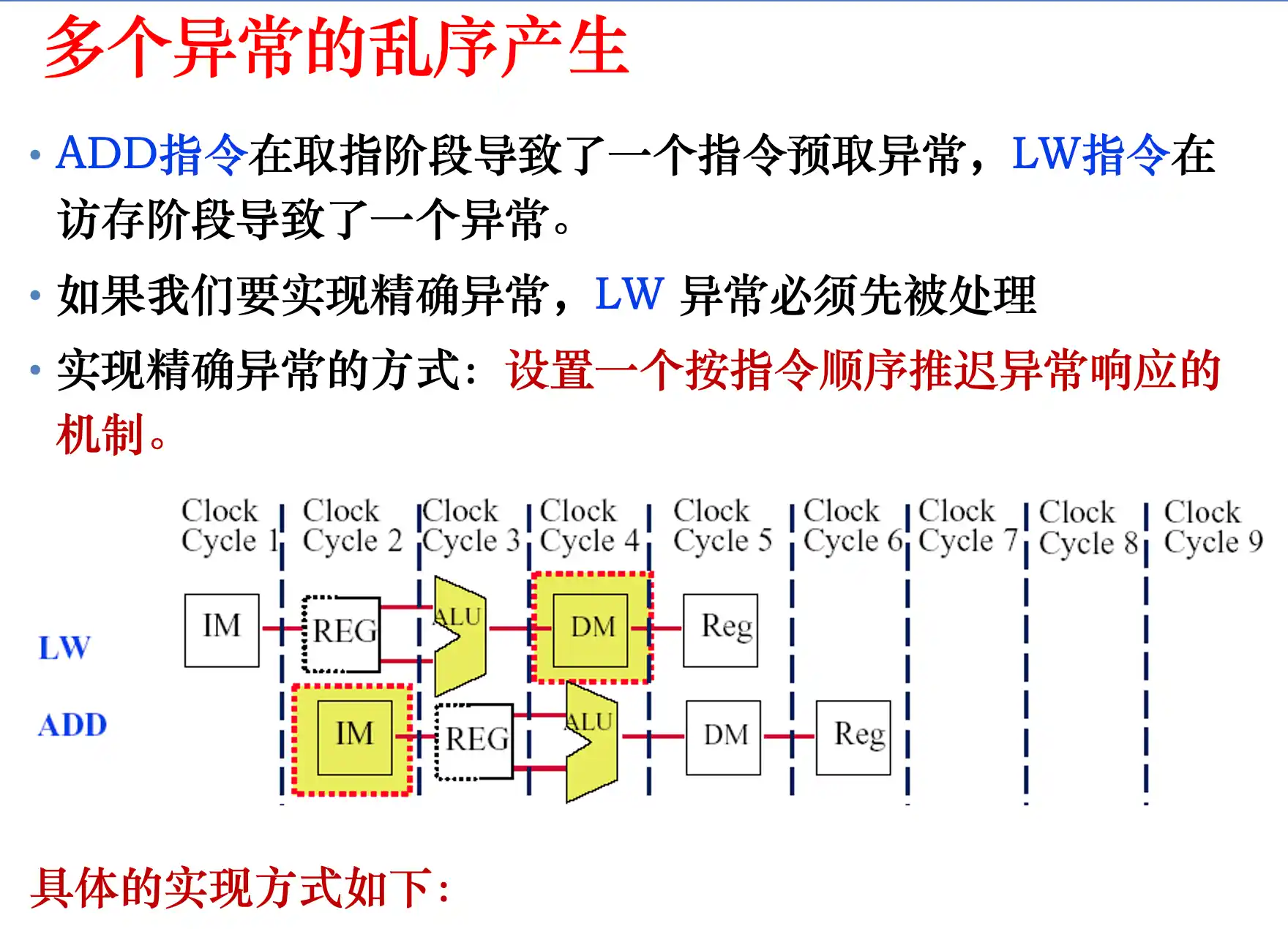
流水线中处理中断和异常的方法



处理完后PC是PC_origin+4

流水线处理机处理异常的方式:


!!EX/MEM被清除是周期结束之后清楚掉add的结果 在周期完成之后才进行异常的处理
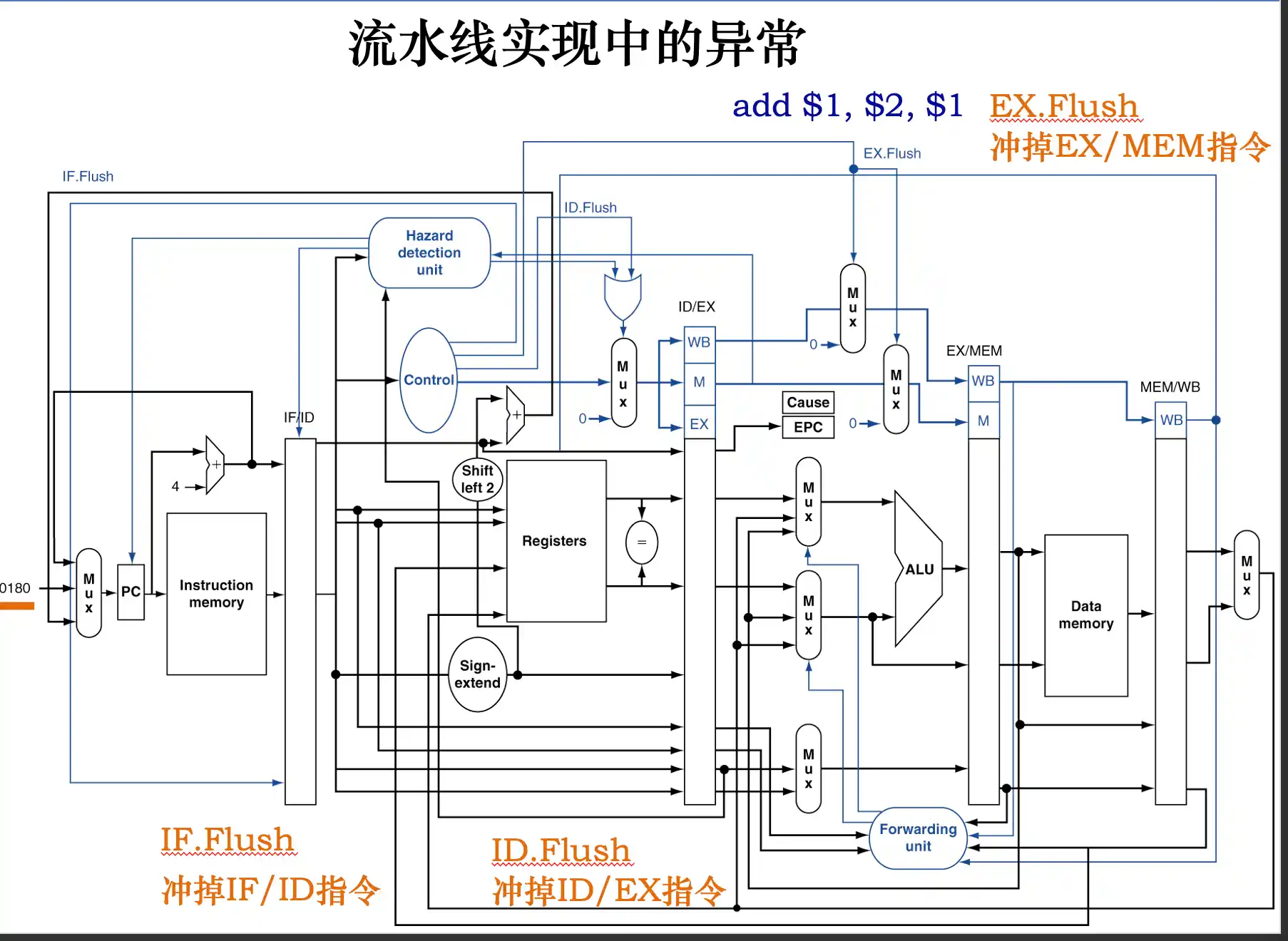
精确非精确异常



同一个周期内多个阶段出现异常,先处理最早流入流水线的异常。
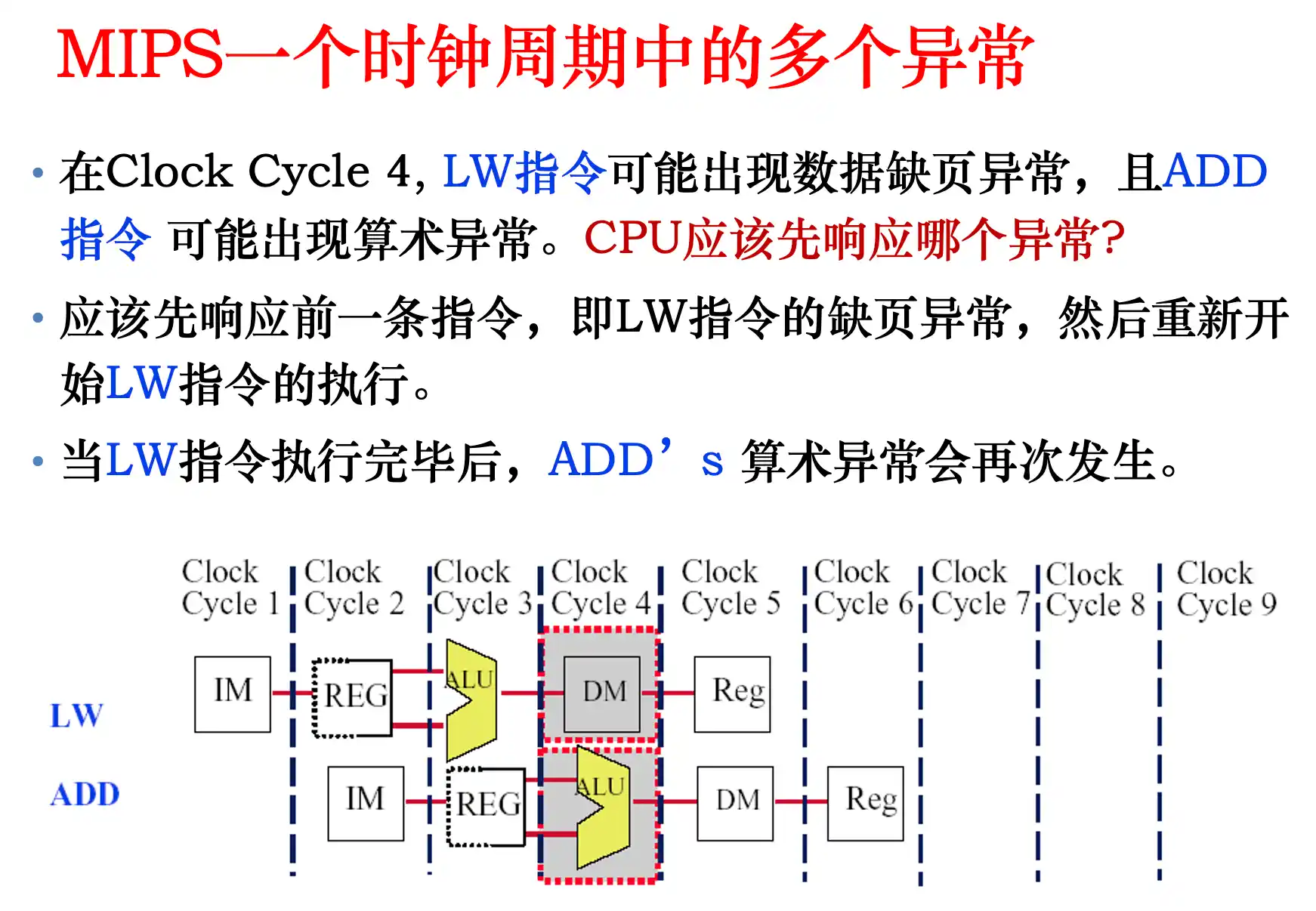

其他
打乱顺序可以提高并行程度,有静态调度(编译器)和动态调度(硬件实现)


写后写 读后写 和数据冒险(写后读)这几种不能调整顺序。

循环展开

还有一些利用了时空相似性提高cache命中的方法 例如 合并数组、合并独立循环、调整循环顺序等。
记分牌/Tomasulo动态调度算法!!!!!!!!!!!!!!
计分牌
四个阶段
-
IS(Issue):顺序发射指令
- (进入条件)在执行发射之前,检查 : 1.结构冲冲突 即busy; 2. 写写冲突,检查 寄存器状态表 是不是有 写写冲突
- (计分牌记录内容)
- 把要使用的部件 Busy置为Yes 记录Op Fd Fj Fk Qj Qk Rj Rk记录
- 在寄存器状态表中 要写的寄存器来源记为当前功能单元
-
RO(Read Operand):读操作数
- (进入条件)Rj · Rk = 1 两个操作数必须都要同时准备好 解决了先写(还没准备好,要等准备好之后才能读)再读(数据冒险)
- (计分牌记录内容)
- R yes转为no 已经被读 Qj Qk转为0
-
EXE 执行
-
WB(WriteBack):写回
- (进入条件)检查要写的寄存器是不是其他已经准备好的内容 比如要写F0 但是有条指令要用F0 而且状态是yes 那么就不能写。 解决的是读写冲突
- (计分牌内容)如果有Q在等待当前WB的部件,把Q去掉,F写进去,R置为Yes 然后把状态寄存器中的等待部件释放 释放BUSY
三张表:
- 指令状态表 记录各个指令运行到哪个状态
- Instruction IS RO EXE WB
- 计分板 记录各个部件的情况
- 部件名 Busy Op(instruction) Fd Fj Fk Qj Qk Rj Rk Q指的是要来源于哪个部件或者功能单元 R指的是是否准备好
- 寄存器状态表 记录各个寄存器将要被谁 哪个部件(功能单元) 写入
Tomasulo动态调度算法
数据传递主要是用CDB 公共数据总线
每个部件之前都有 保留站 reverse station
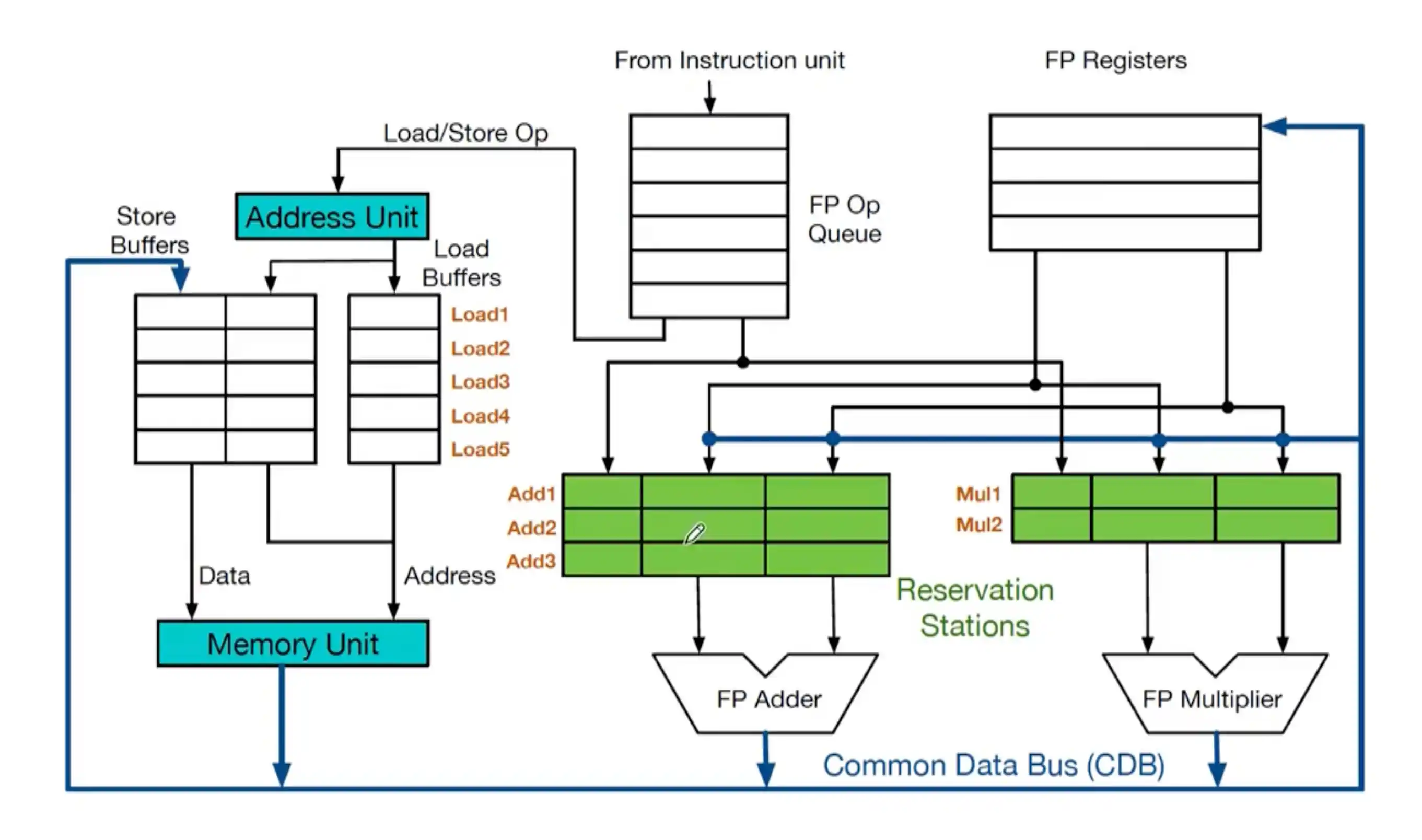
访存unit是单独的store buffer 和load buffer
三个阶段
-
IS(Issue):顺序发射指令
- 如果要进入的部件的 保留站 有位置 就把当前指令载入到保留站中,若其中的操作数在寄存器就绪就将其送入保留站,如果未就绪就在保留站中记录产生该操作数的保留站编号(操作数寄存器名换成了保留站名)。
- 如果是访存操作且有空的缓冲就流出到缓冲。
- 如果没有空的保留站和缓冲,即有结构相关,就不流出。
- 如果IS时候源操作数在FPReg中有值 就直接填入进来(防止WAR)即数据冒险
- 如果有操作数还没写完,就在Q中记录tag
-
EXE 执行: 如果保留站的操作数未计算出,就用保留站编号监视CDB(公共数据总线),一旦有结果就取到保留站中,当两个操作数就绪,进入执行阶段,执行指令操作。解决先写后读相关(RAW)。
-
WB(WriteBack):功能部件完成计算后,将结果连同产生该结果的保留站号一起送到CDB上。根据流出时的记录,所有等待本保留站结果的保留站、存缓冲、目标寄存器将同时从CDB上获得所需数据。
三张表:
- 指令状态表 记录各个指令运行到哪个状态
- Instruction IS EXE WB
- 计分板 记录各个保留站的情况
- (保留站每一条的)标志tag Busy Op(instruction) Vj Vk Qj Qk A
- V是操作数的数值,Q是在等待的保留站条目的tag 两个只有一个有效 Q=0 表示 操作数在V中或者不需要这个操作数,A存的是存储器地址
- 寄存器状态表 记录各个寄存器将要被谁 哪个 tag(最新的) 写入 也可以包括寄存器的值
如果有写写冲突,因为 顺序issuse 在寄存器堆中都会记录正确的最新的数据来源
load在exe阶段可以计算出要访问的地址,然后再WB阶段才写回
第五章 存储系统
存储器的分类和主要特点
SRAM一般CACHE DRAM一般是MEM 因为D要刷新,重启之后数据都没有了。







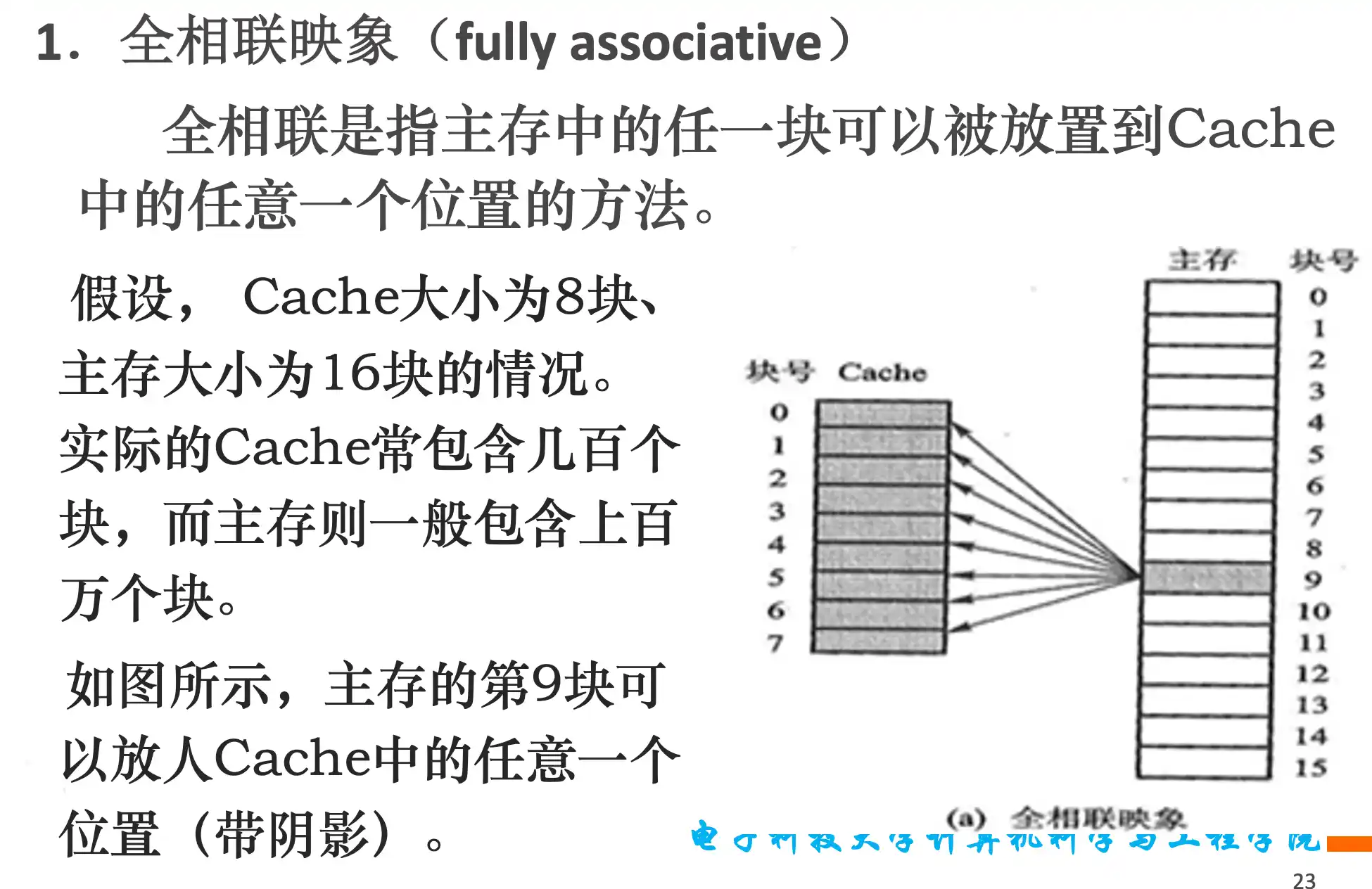
Cache的三种映像关系:全相联、直接映像、组相联


第几组是由较低位地址决定的(offset之前的低位地址)
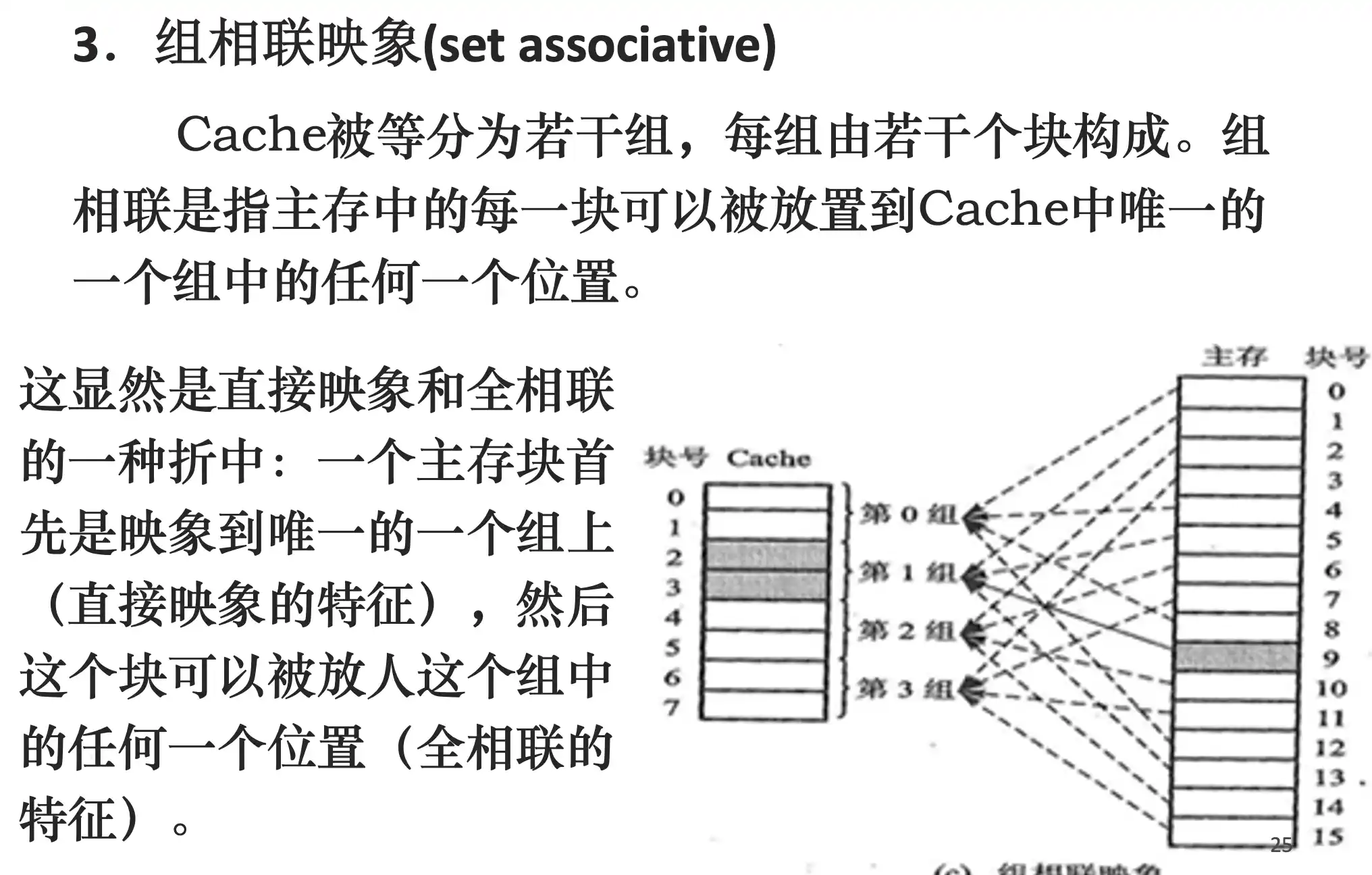

相联度越高 路数就越多 组数就越少,全相联只有一组,很多路
主存地址Tag、Index、块内偏移三个字段的计算




索引是用来找在哪一组的,cache的组越多,index位就越多,全相联只有一个组,所以不用index,除了block offset都是tag
Cache块的替换策略

FIFO的替换看cache中谁先进来的

LRU看访问顺序中谁最早被访问

Cache的读写过程





因为写到buffer里面的速度更快



平均访存时间和CPU时间的计算




Cache失效率的类别,以及每种失效率的解决方法有哪些
强制失效 容量失效 冲突失效

相联度高,路数变多,冲突减少,但是因为要硬件同时比较更多的tag有可能使时钟周期变长


强制失效跟程序的大小有关系,跟容量没关系。减少强制失效,可以增加快大小,每次装入更多的程序。


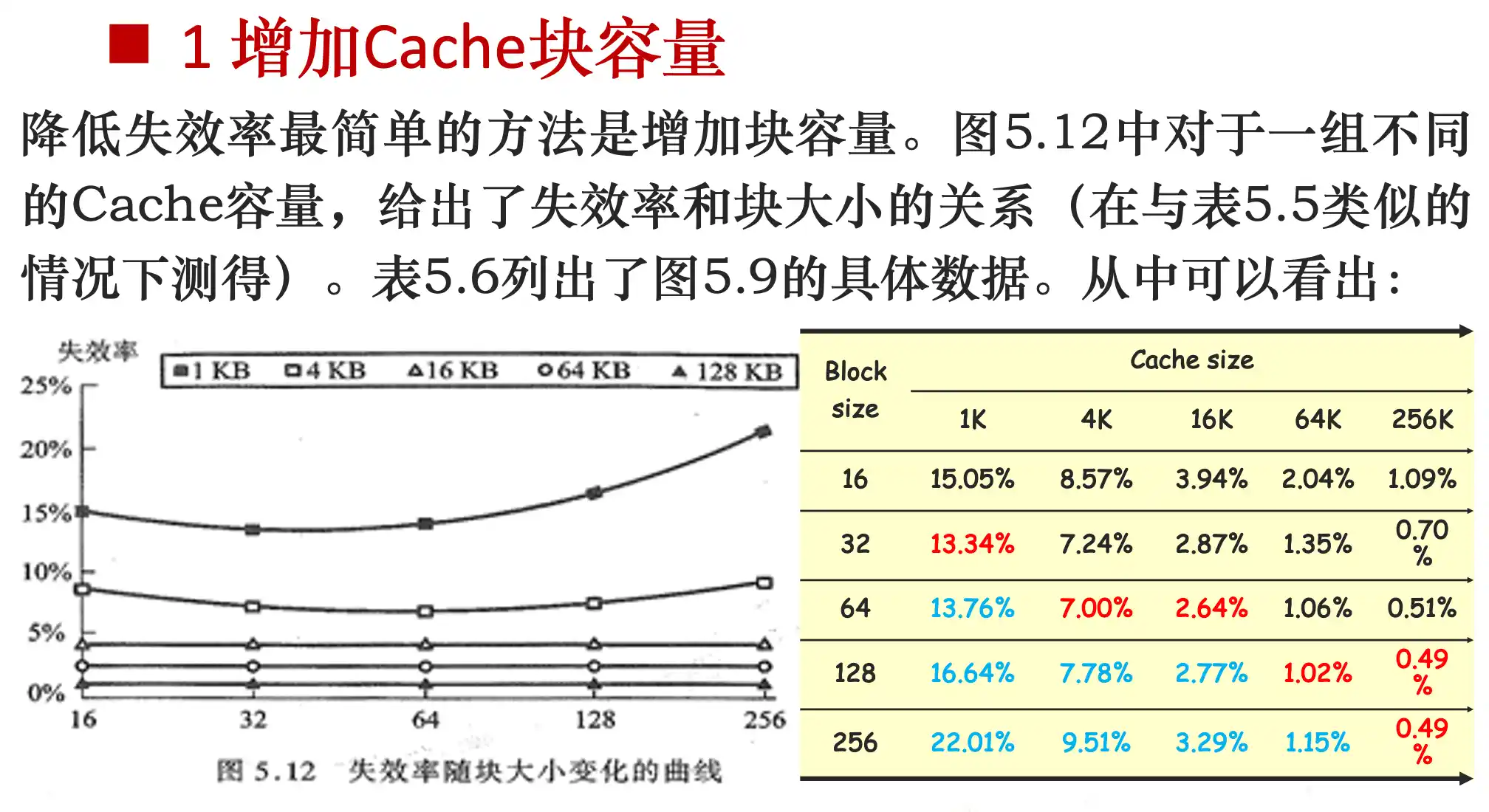
减少 强制失效 但是增大了 容量失效(cache不够大) 和 冲突失效
Cache容量越大,使失效率达到最低的块大小就越大

增加块大小的方法会在降低失效率的同时增加失效开销,而提高相联度则是以增加命中时间为代价。
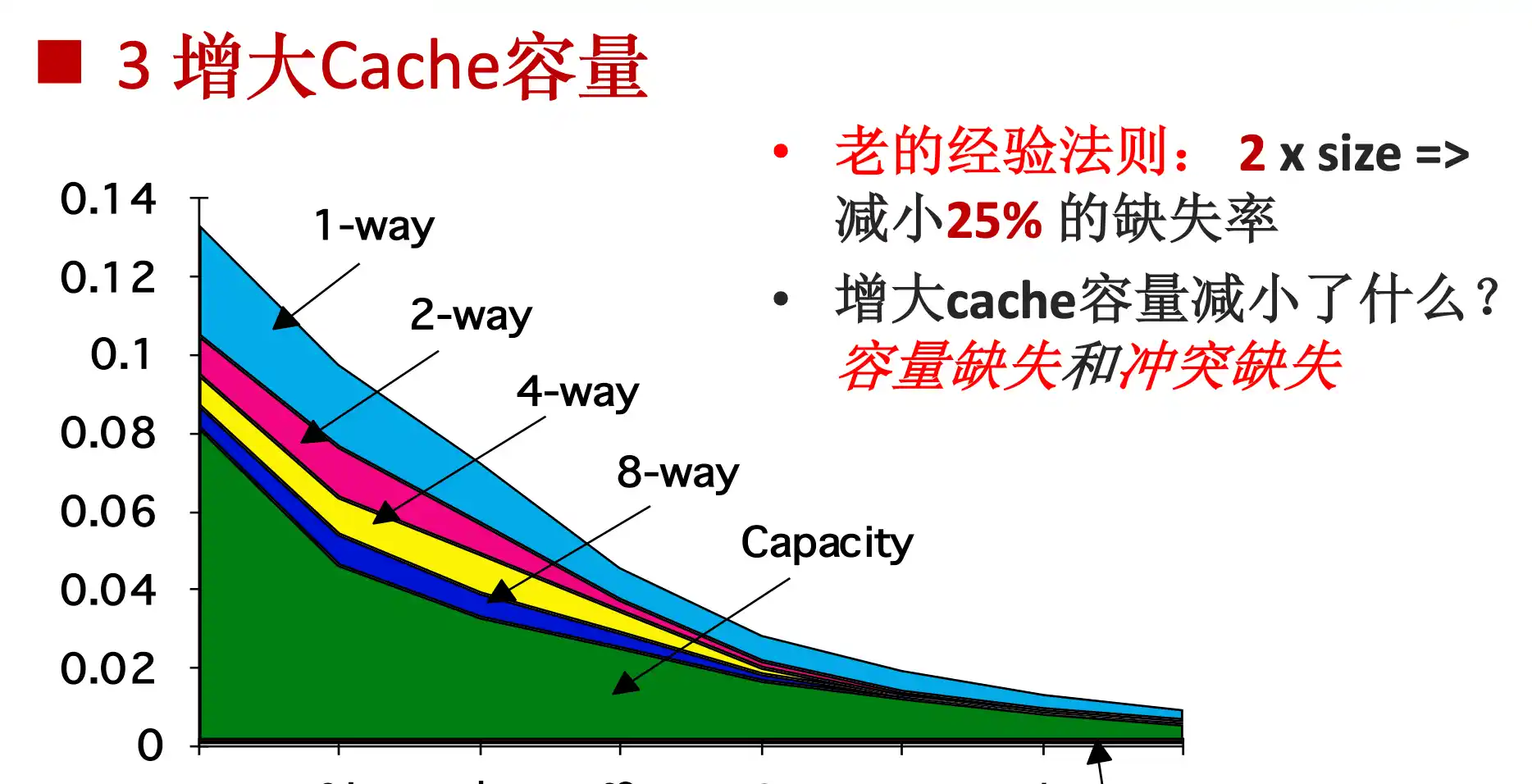
增大cache容量减小了 容量失效 和 冲突失效




减小失效开销:






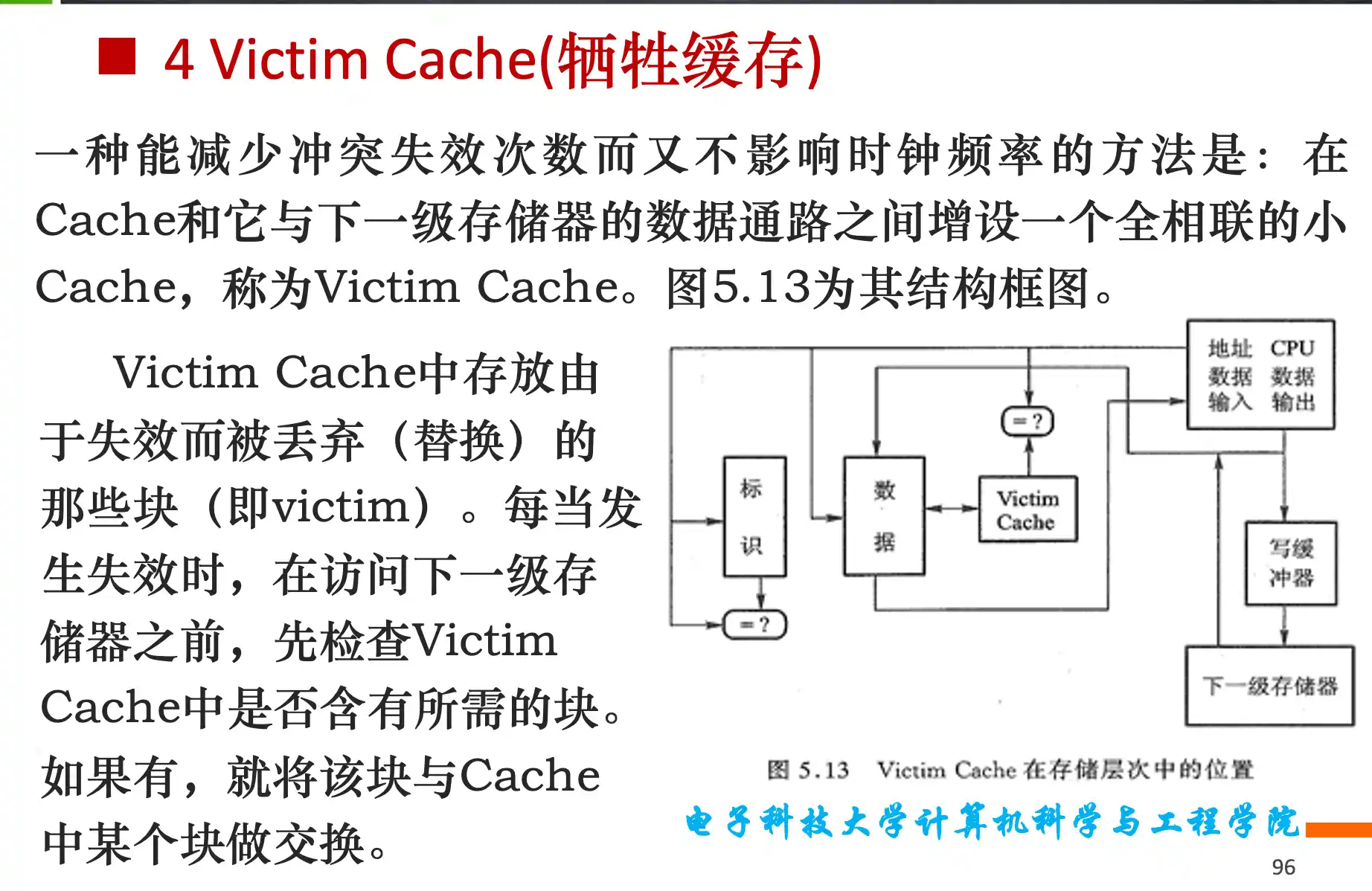


减小命中时间

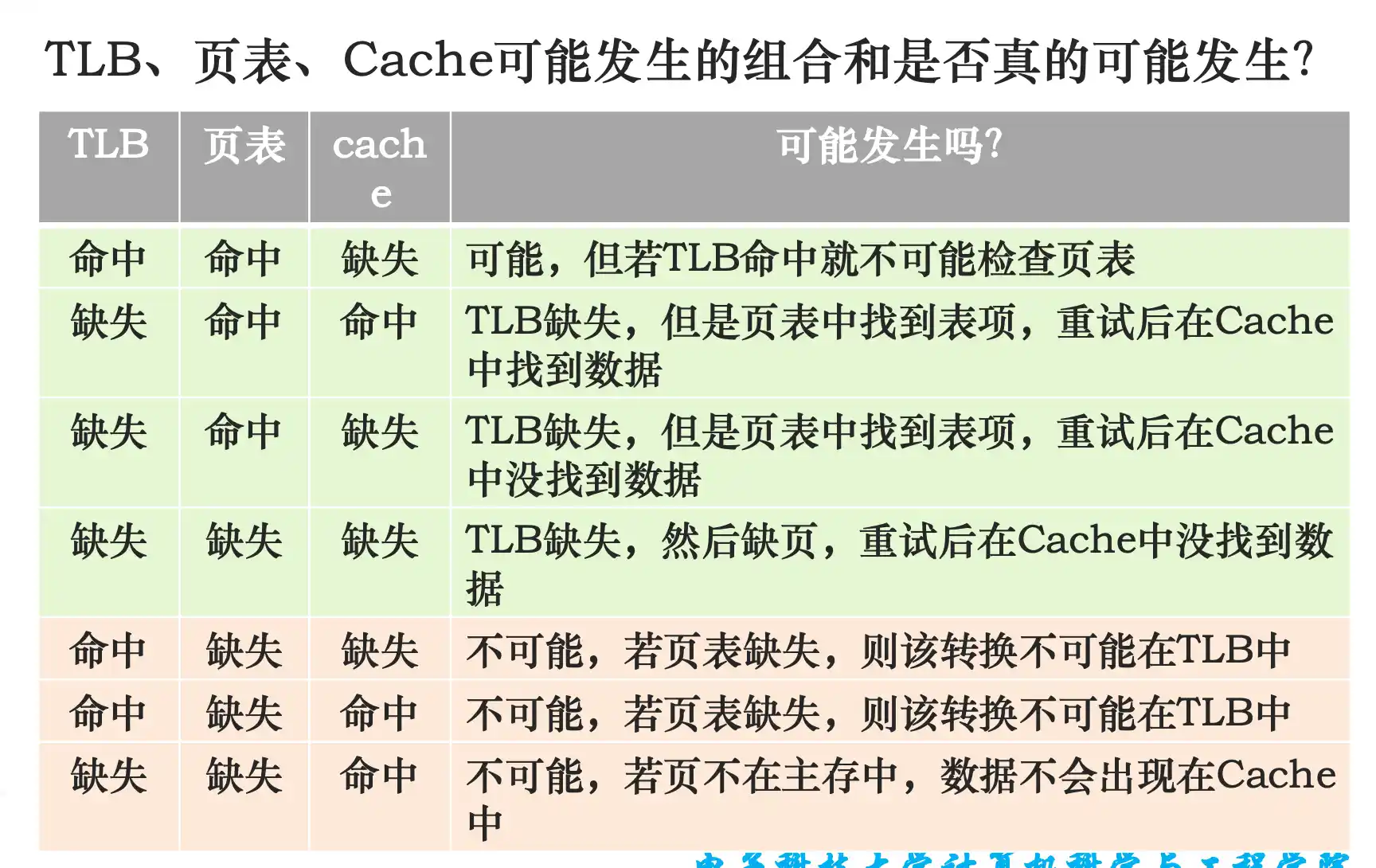
虚拟地址到物理地址的转换过程,TLB表的原理和作用,与Cache的关系,访存时间的最好情况和最坏情况的判断

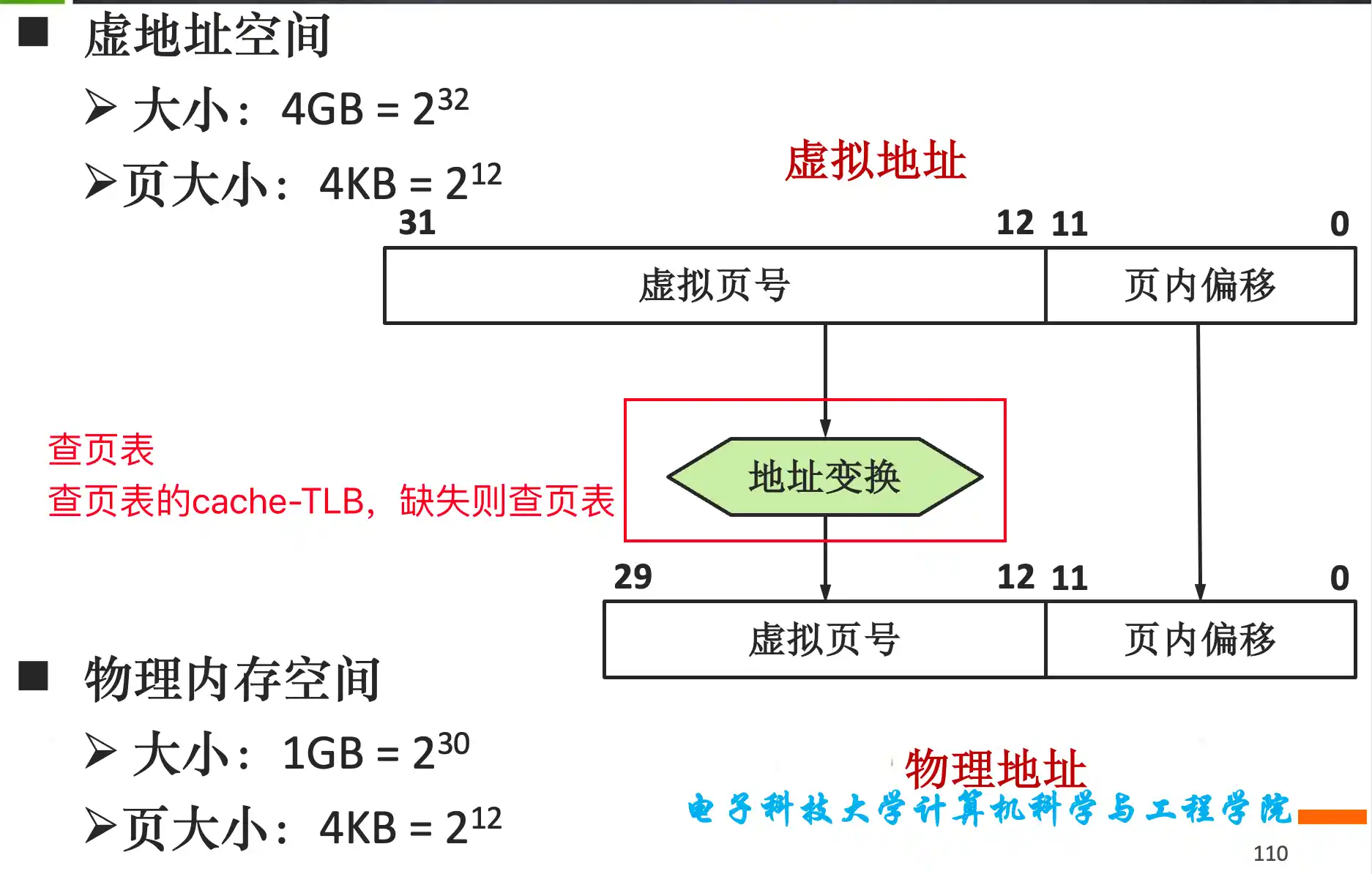

由于写磁盘太长,页表应采用写回机制
页表 直接相联 通过虚拟地址索引 然后
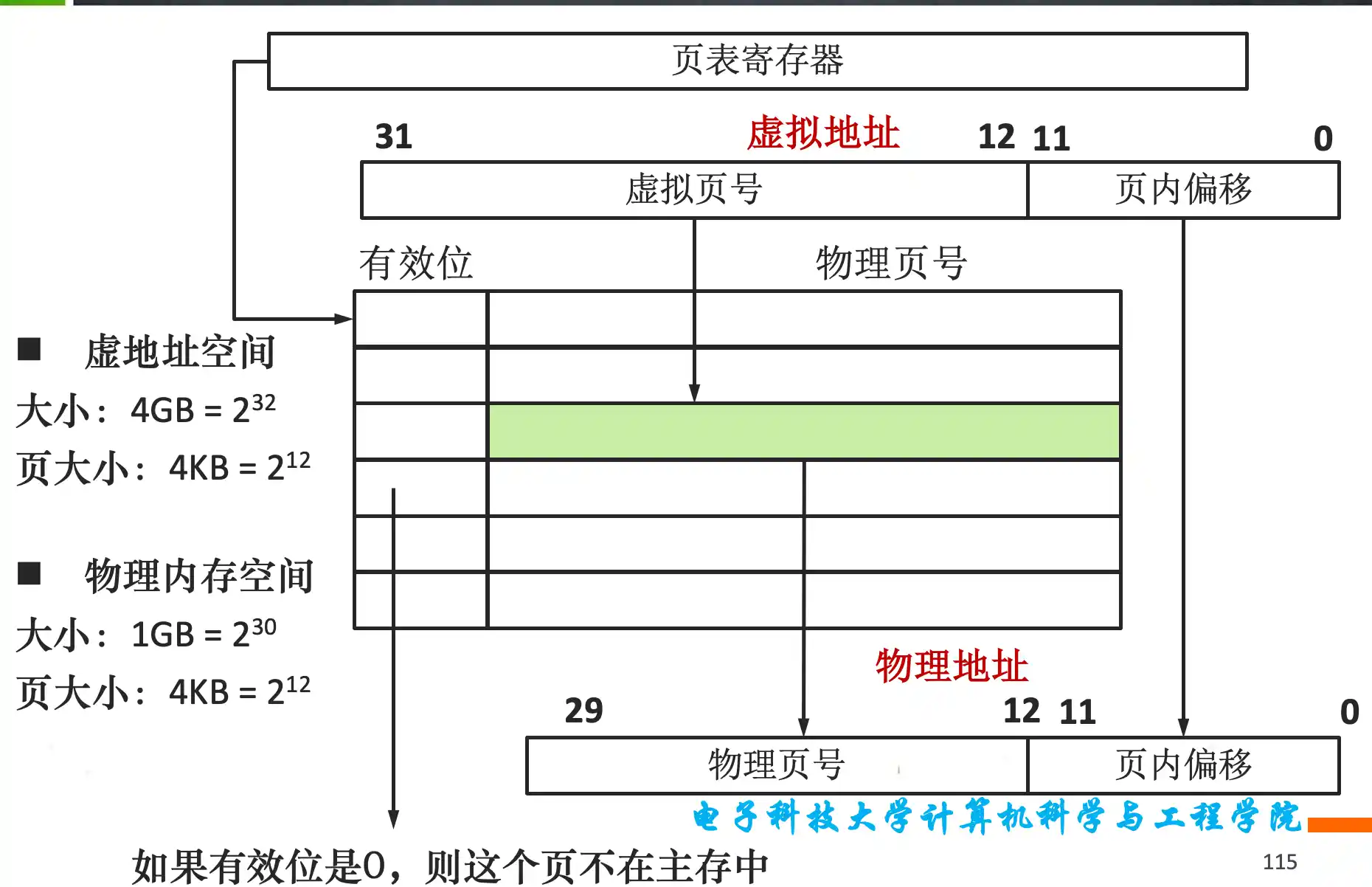
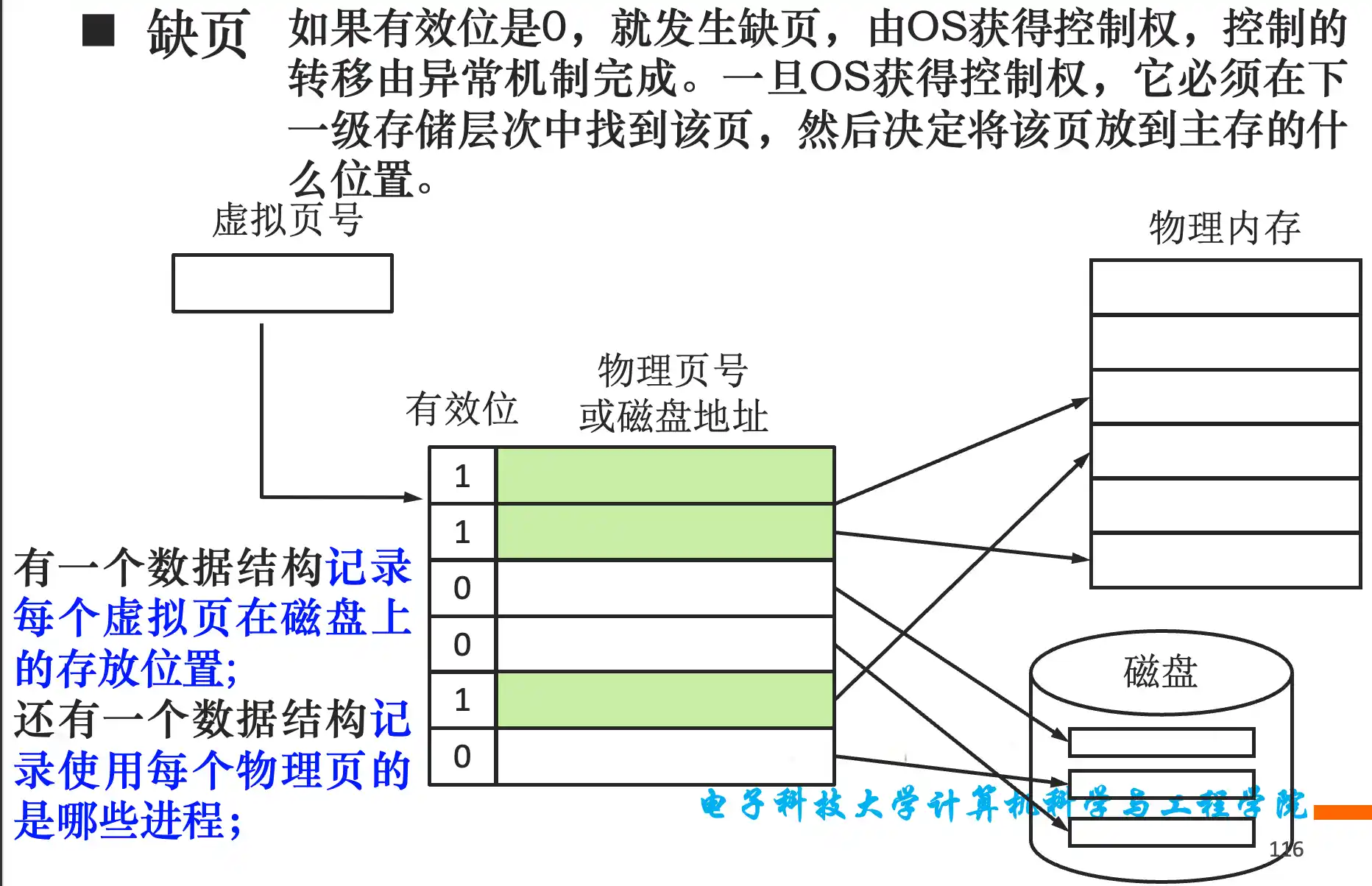




TLB是全相联 页表一般是直接相联



查TLB时虚拟地址是tag

 微信
微信 支付宝
支付宝